
V tomto tutoriálu, se dozvíte, Logistická Regrese. Zde budete vědět, co přesně je logistická regrese, a uvidíte také příklad s Pythonem. Logistická regrese je důležitým tématem strojového učení a budu se snažit, aby to bylo co nejjednodušší.
na počátku dvacátého století byla logistická regrese používána hlavně v biologii poté byla použita v některých aplikacích společenských věd. Pokud jste zvědaví, můžete se zeptat, kde bychom měli použít logistickou regresi? Takže používáme logistickou regresi, když je naše nezávislá proměnná kategorická.
příklady:
- předpovědět, zda člověk bude kupovat auto (1) nebo (0)
- vědět, zda je nádor maligní (1) nebo (0)
Nyní uvažujme situaci, kdy máte zařadit, zda člověk bude koupit auto, nebo ne. V tomto případě, pokud použijeme jednoduchou lineární regresi, budeme muset určit prahovou hodnotu, na které lze klasifikaci provést.
řekněme, skutečná třída je člověk koupí auto, a předpověděl, kontinuální hodnota je 0,45 a prahu máme za 0.5, pak bude tento datový bod považován za osobu, která si auto nekoupí, a to povede k nesprávné predikci.
takže jsme dospěli k závěru, že pro tento typ klasifikačního problému nemůžeme použít lineární regresi. Jak víme, lineární regrese je ohraničena, takže zde přichází logistická regrese, kde se hodnota striktně pohybuje od 0 do 1.
Jednoduché Logistické Regrese:
Výstup: 0 nebo 1
Hypotéza: K = W * X + B
hΘ(x) = sigmoid(K)
Sigmoid Funkce:


Druhy Logistické Regrese:
Binární Logistické Regrese
Pouze dva možné výsledky(Kategorie).
příklad: osoba si koupí auto nebo ne.
multinomiální logistická regrese
Více než dvě kategorie možné bez objednání.
ordinální logistická regrese
Více než dvě kategorie možné s objednáním.
reálný příklad s Pythonem:
nyní vyřešíme skutečný problém s logistickou regresí. Máme datovou sadu, která má 5 sloupců a to: ID uživatele, pohlaví, věk, odhadovaný plat a zakoupený. Nyní musíme vytvořit model, který dokáže předpovědět, zda na daném parametru člověk koupí auto nebo ne.
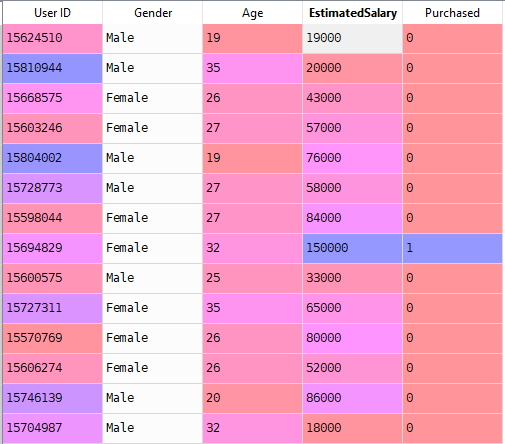 br. Datová sada
br. Datová sadakroky k sestavení modelu:
1. Importing the libraries
zde importujeme knihovny, které budou potřebné pro sestavení modelu.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
importujeme naši datovou sadu do proměnné (tj. datové sady) pomocí pand.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
V našem souboru Dat budeme uvažovat Věk a EstimatedSalary jako Nezávislé proměnné a Zakoupit jako Závislá Proměnná.
X = dataset.iloc].valuesy = dataset.iloc.valueszde X je nezávislá proměnná a y je závislá proměnná.
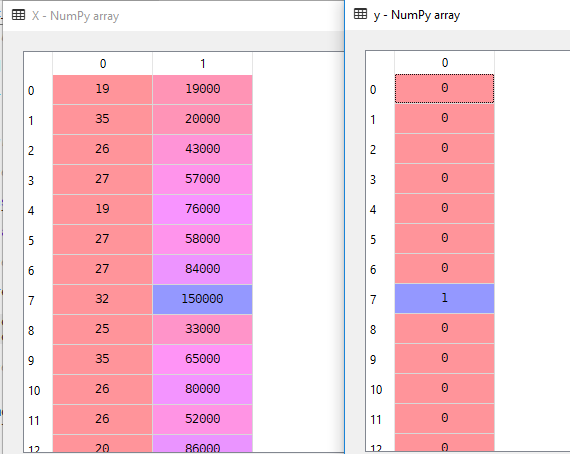
3. Splitting the Data set into the Training Set and Test Set
Nyní rozdělíme náš soubor Dat do trénovací Data a Testovací Data. Tréninková data budou použita k trénování našeho
logistického modelu a testovací data budou použita k ověření našeho modelu. Použijeme Sklearn k rozdělení našich dat. Budeme importovat train_test_split z sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
Teď uděláme funkce škálování na stupnici naše data mezi 0 a 1, aby si lepší přesnost.
zde škálování je důležité, protože tam je obrovský rozdíl mezi věkem a Odhademsalay.
- Import StandardScaler z sklearn.předzpracování
- Pak se instance sc_X objektu StandardScaler
- Pak fit a transformovat X_train a transformovat X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Nyní budeme budovat náš klasifikátor (Logistické).
- Import LogisticRegression z sklearn.linear_model
- Vytvořte klasifikátor instancí objektu LogisticRegression a dejte
random_state = 0, abyste pokaždé získali stejný výsledek. - Nyní použijte tento klasifikátor, aby se vešly X_train a y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)na Zdraví!! Po provedení výše uvedeného příkazu budete mít klasifikátor, který dokáže předpovědět, zda si člověk koupí auto nebo ne.
nyní pomocí klasifikátoru proveďte předpověď pro sadu testovacích dat a najděte přesnost pomocí matrice zmatku.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)Nyní budeme mít y_pred

Nyní můžeme použít y_test (Skutečný Výsledek) a y_pred ( Předpokládané výsledky), aby si správnost našeho modelu.
7. Making the Confusion Matrix
pomocí matrice zmatku můžeme získat přesnost našeho modelu.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)získáte matici cm .

Použijte cm pro výpočet přesnosti, jak je uvedeno níže:
Přesnost = ( cm + cm ) / ( Celkový test datových bodů )

Tady se dostáváme přesnost 89 % . Na zdraví!! dostáváme dobrou přesnost.
nakonec si vizualizujeme náš výsledek tréninkového setu a výsledek testovacího setu. Použijeme matplotlib k vykreslení naší datové sady.
Vizualizace Sadu Školení, výsledek
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()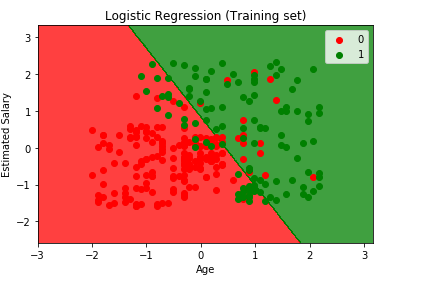
Vizualizace Testu, výsledek
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Nyní Si můžete vytvořit své vlastní klasifikátor pro Logistické Regrese.
Díky!! Pokračujte V Kódování !!
Poznámka: Toto je příspěvek hosta a názor v tomto článku je hostujícím spisovatelem. Pokud máte nějaké problémy s některým z článků zveřejněných na www.marktechpost.com please contact at [email protected]
Advertisement
