Všechny databáze uživatelů ví o pravidelné agregační funkce, které pracují na celou tabulku a použít s klauzule GROUP BY. Jen velmi málo lidí používá funkce okna v SQL. Ty pracují na sadě řádků a vracejí jednu agregovanou hodnotu pro každý řádek.
hlavní výhodou použití okenních funkcí oproti běžným agregátním funkcím je: Funkce okna nezpůsobují seskupení řádků do jednoho výstupního řádku, řádky si zachovávají svou samostatnou identitu a ke každému řádku bude přidána agregovaná hodnota.
Pojďme se podívat na to, jak Okno funguje a pak vidět několik příkladů použití v praxi, aby být jisti, že věci jsou jasné, a také, jak SQL a výstup porovnat, že pro SUM() funkce.
jako vždy se ujistěte, že jste plně zálohováni, zejména pokud zkoušíte nové věci s vaší databází.
Úvod do funkcí okna
funkce okna pracují na sadě řádků a vracejí jednu agregovanou hodnotu pro každý řádek. Okno termín popisuje sadu řádků v databázi, na které bude funkce pracovat.
okno (sada řádků, na kterých funkce pracují) definujeme pomocí klauzule OVER (). Více o klauzuli OVER() budeme diskutovat v článku níže.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Když budete zahrnovat vše, bude počítat všechny hodnoty včetně duplicitních. ODLIŠNÉ není podporován v okně funkce,
výraz
cílový sloupec nebo výraz, že funkce pracuje. Jinými slovy, název sloupce, pro který potřebujeme agregovanou hodnotu. Například sloupec obsahující částku objednávky, abychom mohli vidět celkový počet přijatých objednávek.
OVER
určuje klauzule okna pro agregované funkce.
PARTITION by partition_list
definuje okno (sadu řádků, na kterých funguje funkce window) pro funkce window. Musíme poskytnout pole nebo seznam polí pro oddíl po oddílu podle klauzule. Více polí musí být odděleno čárkou jako obvykle. Pokud oddíl podle není zadán, seskupení bude provedeno na celé tabulce a hodnoty budou odpovídajícím způsobem agregovány.
pořadí podle order_list
seřadí řádky v každém oddílu. Pokud ORDER BY není zadán, ORDER BY používá celou tabulku.
příklady
vytvoříme tabulku a vložíme fiktivní záznamy pro psaní dalších dotazů. Spustit pod kódem.
souhrnné funkce okna
SUM ()
všichni známe souhrnnou funkci SUM (). Dělá součet zadaného pole pro zadanou skupinu (jako město, stát, země atd.) nebo pro celou tabulku, pokud skupina není zadána. Uvidíme, jaký bude výstup Funkce regular SUM() aggregate a funkce window SUM () aggregate.
níže je uveden příklad agregátní funkce regulárního součtu (). Shrnuje částku objednávky pro každé město.
můžete vidět z výsledku, že normální agregační funkce skupiny více řádků do jednoho výstupního řádku, které způsobí, že jednotlivé řádky ztratit svou identitu.
|
1
2
3
4
|
VYBERTE město, SUM(order_amount) total_order_amount
OD . SKUPINA PODLE města
|

To se nestane s oknem agregační funkce. Řádky si zachovávají svou identitu a také vykazují agregovanou hodnotu pro každý řádek. V níže uvedeném příkladu dotaz dělá totéž, a to agreguje data pro každé město a ukazuje součet celkové částky objednávky pro každé z nich. Dotaz však nyní vloží další sloupec pro celkovou částku objednávky tak, aby si každý řádek zachoval svou identitu. Sloupec označený grand_total je nový sloupec v příkladu níže.
AVG ()
AVG nebo Average pracuje přesně stejným způsobem s funkcí okna.
následující dotaz vám poskytne průměrnou částku objednávky pro každé město a pro každý měsíc (i když pro jednoduchost jsme použili data pouze za jeden měsíc).
určíme více než jeden průměr zadáním více polí v seznamu oddílů.
je také třeba poznamenat, že můžete použít výrazy v seznamech jako měsíc (order_date), jak je uvedeno v níže uvedeném dotazu. Jako vždy můžete tyto výrazy tak složité, jak chcete, pokud je syntaxe správná!
Z výše uvedeného obrázku, můžeme jasně vidět, že v průměru jsme obdrželi rozkaz 12,333 pro Arlington města na duben 2017.
Průměrná Objednávka Částka = Celková Částka Objednávky / Celkem Objednávky
= (20,000 + 15,000 + 2,000) / 3
= 12,333
můžete také použít kombinaci SUM() & COUNT() funkce pro výpočet průměru.
MIN ()
funkce min () aggregate najde minimální hodnotu pro zadanou skupinu nebo pro celou tabulku, pokud skupina není zadána.
například hledáme nejmenší objednávku (minimální objednávku) pro každé město, které bychom použili následující dotaz.
MAX (v)
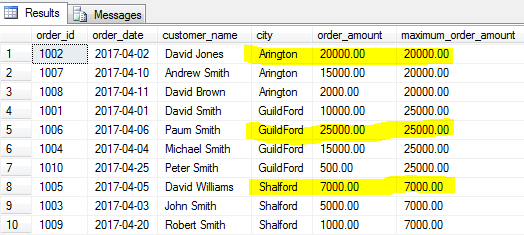
stejně jako MIN() funkce vám dává minimální hodnota, MAX() funkce bude identifikovat největší hodnotu zadaného pole pro zadané skupiny řádků nebo pro celou tabulku, pokud skupina není uvedeno.
najdeme největší objednávku (maximální částku objednávky) pro každé město.
Počet ()
funkce COUNT () počítá záznamy / řádky.
Všimněte si, že DISTINCT není podporován funkcí window COUNT (), zatímco je podporován funkcí regular COUNT (). DISTINCT vám pomůže najít odlišné hodnoty zadaného pole.
Pokud například chceme vidět, kolik zákazníků zadalo objednávku v dubnu 2017, nemůžeme přímo počítat všechny zákazníky. Je možné, že stejný zákazník zadal více objednávek ve stejném měsíci.
počet (customer_name) vám dá nesprávný výsledek, protože bude počítat duplikáty. Zatímco počet (odlišné uživatelské jméno) vám poskytne správný výsledek, protože počítá každého jedinečného zákazníka pouze jednou.
platí pro funkci regulárního počtu ():
|
1
2
3
4
5
|
VYBERTE město,POČET(ODLIŠNÉ customer_name) number_of_customers
OD .
SKUPINA PODLE města
|
Neplatný pro okna COUNT() funkce:
výše uvedený dotaz s Oknem funkce vám níže chybu.
nyní najdeme celkovou objednávku přijatou pro každé město pomocí funkce window COUNT ().
Pořadí Funkcí Okna
stejně jako Okna agregační funkce agregační hodnotu zadaného pole, POŘADÍ funkce bude pořadí hodnot vybraného pole a kategorizovat je podle jejich hodnost.
nejběžnějším použitím hodnotících funkcí je nalezení horní (N) záznamy na základě určité hodnoty. Například Top 10 nejlépe placených zaměstnanců, Top 10 hodnocených studentů, Top 50 největších objednávek atd.
jsou podporovány následující funkce hodnocení:
RANK (), DENSE_RANK (), ROW_NUMBER (), NTILE ()
pojďme o nich diskutovat jeden po druhém.
RANK ()
funkce RANK () se používá k udělení jedinečné hodnosti každému záznamu na základě zadané hodnoty, například platu, částky objednávky atd.
pokud mají dva záznamy stejnou hodnotu, funkce RANK() přiřadí oběma záznamům stejnou hodnost přeskočením další hodnosti. To znamená – pokud jsou v hodnosti dvě stejné hodnoty 2, přiřadí stejnou hodnost 2 oběma záznamům a poté přeskočí hodnost 3 a přiřadit hodnost 4 k dalšímu záznamu.
řadíme každou objednávku podle výše objednávky.
|
1
2
3
4
5
|
VYBERTE order_id,order_date,customer_name,město,
RANK() OVER(ORDER BY order_amount DESC)
OD .
|
Z výše uvedeného obrázku můžete vidět, že stejné hodnoty (3) je přiřazena do dvou stejných záznamů (každý s objednávku výši 15,000) a to pak přeskočí na další hodnost (4) a přiřadit hodnost 5, aby se další záznam.
DENSE_RANK ()
funkce DENSE_RANK () je identická s funkcí RANK (), kromě toho, že nevynechává žádnou hodnost. To znamená, že pokud jsou nalezeny dva identické záznamy, DENSE_RANK () přiřadí oběma záznamům stejnou hodnost, ale nepřeskočí, pak přeskočí další hodnost.
podívejme se, jak to funguje v praxi.
Jak můžete vidět výše, stejné hodnoty je dána dva stejné záznamy (každý má stejné množství objednávky) a pak další hodnost číslo je uvedeno na další záznam bez přeskočení hodnosti hodnotu.
ROW_NUMBER ()
název je samozřejmý. Tyto funkce přiřazují každému záznamu jedinečné číslo řádku.
číslo řádku bude resetováno pro každý oddíl, pokud je zadán oddíl podle. Podívejme se, jak ROW_NUMBER () funguje bez oddílu a poté s oddílem.
ROW_ ČÍSLO() bez ROZDĚLENÍ,
ROW_NUMBER() s PARTITION
Všimněte si, že jsme udělali oddíl na město. To znamená, že číslo řádku je resetováno pro každé město, a tak se restartuje na 1 znovu. Nicméně, pořadí řádků je určena částka objednávky tak, že na daném městě největší množství objednávky bude první řádek a tak přiřazeno číslo řádku 1.
NTILE ()
NTILE () je velmi užitečná funkce okna. To vám pomůže určit, co percentil (nebo kvartil, nebo jakékoliv jiné dělení) daný řádek spadá do.
To znamená, že pokud máte 100 řádků a chcete vytvořit 4 kvartilů na základě zadaného hodnota pole můžete to udělat tak snadno, a uvidíte, jak mnoho řádků spadají do každého kvartilu.
podívejme se na příklad. V níže uvedeném dotazu jsme uvedli, že chceme vytvořit čtyři kvartily na základě výše objednávky. Pak chceme vidět, kolik objednávek spadá do každého kvartilu.
NTILE vytváří dlaždice na základě následujícího vzorce:
počet řádků v každé dlaždice = počet řádků v sada výsledků / počet dlaždic uvedeno
Zde je náš příklad, máme celkem 10 řádků a 4 dlaždice jsou uvedené v dotazu, takže počet řádků v každé dlaždice bude 2.5 (10/4). Jako počet řádků by mělo být celé číslo, ne desetinné číslo. SQL engine přiřadí 3 řádky pro první dvě skupiny a 2 řádky pro zbývající dvě skupiny.
funkce hodnotového okna
LAG () a LEAD ()
funkce LEAD() a LAG () jsou velmi silné, ale lze je vysvětlit složitě.
protože se jedná o úvodní článek níže, podíváme se na velmi jednoduchý příklad, který ilustruje, jak je používat.
funkce LAG umožňuje přístup k datům z předchozího řádku ve stejné sadě výsledků bez použití jakýchkoli spojení SQL. Můžete vidět v níže uvedeném příkladu, pomocí funkce LAG jsme našli předchozí datum objednávky.
Skript najít předchozí objednávky, datum objednávky pomocí LAG() funkce:
VÉST funkce umožňuje přístup k datům z další řádek ve stejném výsledek nastavit bez použití SQL spojení. Můžete vidět v níže uvedeném příkladu, pomocí funkce olova jsme našli další datum objednávky.
Skript najít další datum objednávky pomocí LEAD() funkce:
FIRST_VALUE() a LAST_VALUE()
Tato funkce vám pomůže identifikovat první a poslední záznam v partition nebo celou tabulku, pokud ODDÍL není uveden.
pojďme najít první a poslední pořadí každého města z naší stávající datové sady. Poznámka ORDER BY klauzule je povinné pro FIRST_VALUE() a LAST_VALUE() funkce,
Z výše uvedeného obrázku, můžeme jasně vidět, že první objednávky přijaté na 2017-04-02 a poslední objednávky přijaté na 2017-04-11 pro Arlington city a funguje to stejné pro ostatní města.
Užitečné Odkazy
- Zálohování Typy & Strategie pro SQL Databází
- Článek na webu TechNet na CELÉM Doložka
- Článku na webu MSDN Na DENSE_RANK
Další skvělé články od Ben
Jak SQL Server vybere zablokování oběť,
Jak Používat Okno Funkce
- Autora
- Poslední Příspěvky
Zobrazit všechny příspěvky od Ben Richardson
- Power BI: Vodopád Grafy a Kombinované Vizuální – 19. ledna 2021
- Power BI: Podmíněné formátování a data barvy v akci – 14. ledna 2021
- Power BI: Import dat z SQL Server a MySQL – 12. ledna 2021