rozpoznávání obličeje-krok za krokem
řešme tento problém krok za krokem. Pro každý krok se dozvíme o jiném algoritmu strojového učení. Nebudu vysvětlovat, každý algoritmus zcela na to, aby z toho knihu, ale budete učit z hlavních myšlenek za každým jednou a dozvíte se, jak si můžete vytvořit svůj vlastní rozpoznávání obličeje systém v Pythonu pomocí OpenFace a dlib.
Krok 1: Nalezení všech ploch
prvním krokem v našem potrubí je detekce obličeje. Je zřejmé, že musíme najít tváře na fotografii, než se je pokusíme rozeznat!
Pokud jste použili jakýkoli fotoaparát v posledních 10 letech, pravděpodobně jste viděli detekce obličeje v akci:

detekce Obličeje je skvělá vlastnost pro kamery. Když fotoaparát může automaticky vybrat tváře, může se ujistit, že všechny tváře jsou zaostřeny, než pořídí snímek. Ale použijeme to pro jiný účel-nalezení oblastí obrazu, které chceme předat dalšímu kroku v našem potrubí.
detekce Obličeje šel proudu v brzy 2000, když Paulem Violou a Michaelem Jonesem vynalezl způsob, jak detekovat tváře, že byl dostatečně rychlý na levné kamery. Nyní však existují mnohem spolehlivější řešení. Použijeme metodu vynalezenou v roce 2005 zvanou Histogram orientovaných gradientů – nebo zkrátka prase.
najít tváře v obraze, začneme tím, že náš obraz černé a bílé, protože my nepotřebujeme barvu údaje najít tváře:

Pak se podíváme na každou pixelů v našem obrázku, jeden po druhém. Pro každý jednotlivý pixel se chceme podívat na pixely, které jej přímo obklopují:

Naším cílem je zjistit, jak se temná aktuální pixel je ve srovnání s pixely přímo v okolí. Pak chceme nakreslit šipku ukazující, kterým směrem se obraz ztmavne:

Pokud tento proces zopakujete pro každý jednotlivý pixel v obraze, skončíte s tím, že každý pixel bude nahrazen šipkou. Tyto šipky se nazývají přechody a ukazují tok ze světla do tmy po celém obrázku:
To se může zdát jako náhodný věc, kterou udělat, ale je tam opravdu dobrý důvod pro nahrazení pixelů s přechody. Pokud analyzujeme pixely přímo, opravdu tmavé obrázky a opravdu světlé obrázky stejné osoby budou mít zcela odlišné hodnoty pixelů. Ale pouze s ohledem na směr, kterým se mění jas, jak skutečně tmavé obrázky, tak opravdu jasné obrázky skončí se stejným přesným znázorněním. Díky tomu je problém mnohem snazší vyřešit!
ale uložení gradientu pro každý jednotlivý pixel nám dává příliš mnoho detailů. Nakonec nám chybí les pro stromy. Bylo by lepší, kdybychom viděli základní tok světla/tmy na vyšší úrovni, abychom viděli základní vzorec obrazu.
Chcete-li to provést, rozdělíme obrázek na malé čtverce o rozměrech 16×16 pixelů. V každém čtverci spočítáme, kolik gradientů ukazuje v každém hlavním směru (kolik bodů nahoru, nahoru-vpravo, vpravo atd.). Pak nahradíme tento čtverec na obrázku směry šipky, které byly nejsilnější.
konečný výsledek je, že jsme zase původní obraz do velmi jednoduchá reprezentace, která zachycuje základní strukturu obličeje jednoduchým způsobem:

najít tváře v tomto HOG obraz, vše, co musíme udělat, je najít část naší image, který vypadá velmi podobně jako známý PRASE vzor, který byl extrahován ze spoustu dalších školení tváře:

Pomocí této techniky, nyní můžeme snadno najít tváře v každém obrazu:

Pokud si chcete vyzkoušet tento krok sami pomocí Python a dlib, tady je kód ukazuje, jak vytvořit a zobrazit PRASE reprezentace obrazů.
Krok 2: pózování a promítání tváří
Uff, izolovali jsme tváře v našem obrazu. Ale teď se musíme vypořádat s problémem, který čelí obrátil různými směry vypadají úplně jinak než počítač:

K účtu pro to, budeme se snažit, aby warp každý obrázek tak, že oči a rty jsou vždy ve vzorku místo v obraze. Díky tomu bude pro nás mnohem snazší porovnávat tváře v dalších krocích.
k tomu použijeme algoritmus nazvaný odhad orientačního bodu obličeje. Existuje mnoho způsobů, jak to udělat, ale použijeme přístup, který vynalezli v roce 2014 Vahid Kazemi a Josephine Sullivan.
základní myšlenkou je, že jsme se přijít s 68 zvláštních bodů (tzv. landmarks), které existují na každé tváři — horní brady, vnější okraj každé oko, vnitřní okraj obočí, atd. Pak budeme trénovat algoritmus strojového učení, abychom mohli najít těchto 68 konkrétních bodů na jakékoli tváři:

Tady je výsledek vyhledání 68 tvář památky na našem testovacím obrázku:

Nyní, když víme, byly oči a ústa jsou, budeme jednoduše otáčet, měřítko a stříhat obraz tak, aby oči a ústa jsou soustředěny co nejlépe. Nebudeme dělat žádné efektní 3D deformace, protože by to způsobilo zkreslení obrazu. Budeme používat pouze základní obrazové transformace, jako je rotace a měřítko, které zachovávají paralelní linie (nazývané afinní transformace):

bez ohledu na to, jak se tváří se obrátil, jsme schopni centrum oči a ústa jsou ve zhruba stejné pozici v obraze. Díky tomu bude náš další krok mnohem přesnější.
Pokud si chcete tento krok vyzkoušet sami pomocí Pythonu a dlib, zde je Kód pro nalezení orientačních bodů obličeje a zde je Kód pro transformaci obrázku pomocí těchto orientačních bodů.
Krok 3: Kódování tváře
nyní jsme na maso problému-vlastně říkat tváře od sebe. To je místo, kde se věci opravdu zajímavé!
nejjednodušší přístup k rozpoznání obličeje je přímo porovnat neznámých tváří, které jsme našli v Kroku 2 s všechny obrázky, které máme lidí, které již byly označeny. Když najdeme dříve označenou tvář, která vypadá velmi podobně jako naše neznámá tvář, musí to být stejná osoba. Vypadá to jako docela dobrý nápad, že?
je tu vlastně obrovský problém s tímto přístupem. Stránky, jako je Facebook s miliardami uživatelů a biliony fotek nemůže smyčka přes všechny předchozí-tagged tváře porovnat to, aby každý nově nahraný obrázek. To by trvalo příliš dlouho. Musí být schopni rozpoznat tváře v milisekundách, ne hodiny.
potřebujeme způsob, jak extrahovat několik základních měření z každé tváře. Pak bychom mohli měřit naši neznámou tvář stejným způsobem a najít známou tvář s nejbližšími měřeními. Můžeme například měřit velikost každého ucha, vzdálenost mezi očima, délku nosu atd. Pokud jste někdy sledovali špatný čin show, jako je CSI, víte, o čem mluvím:
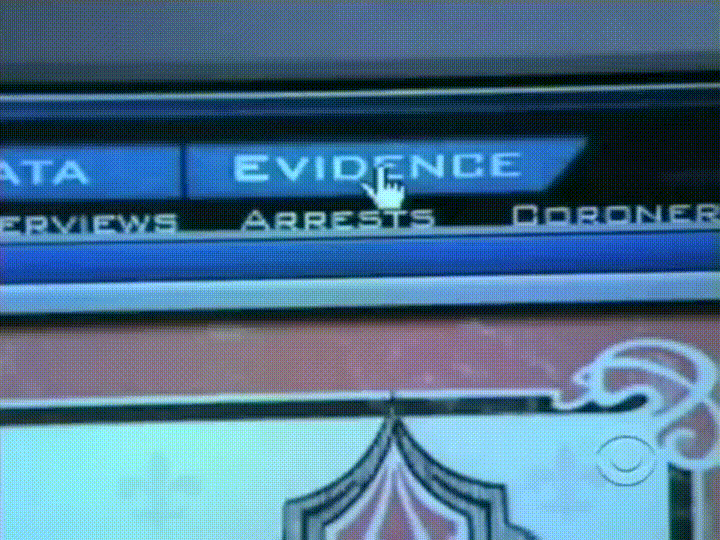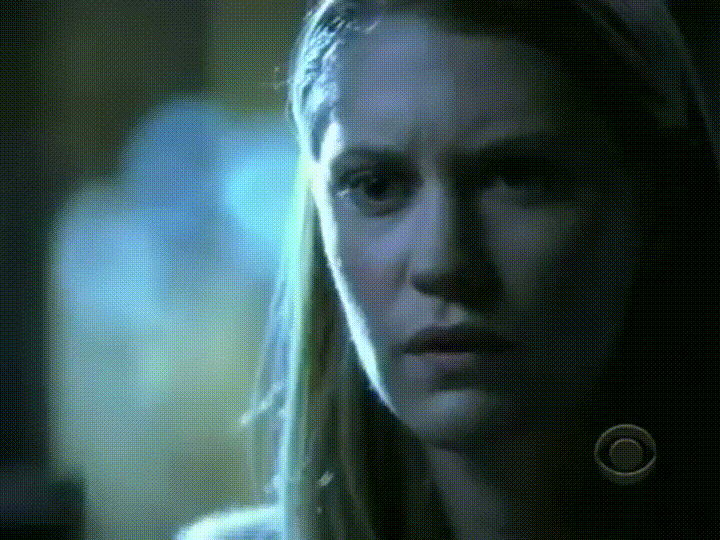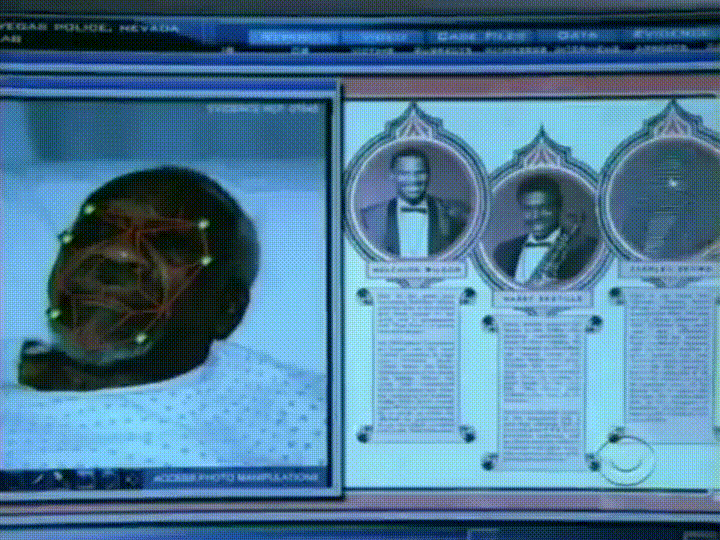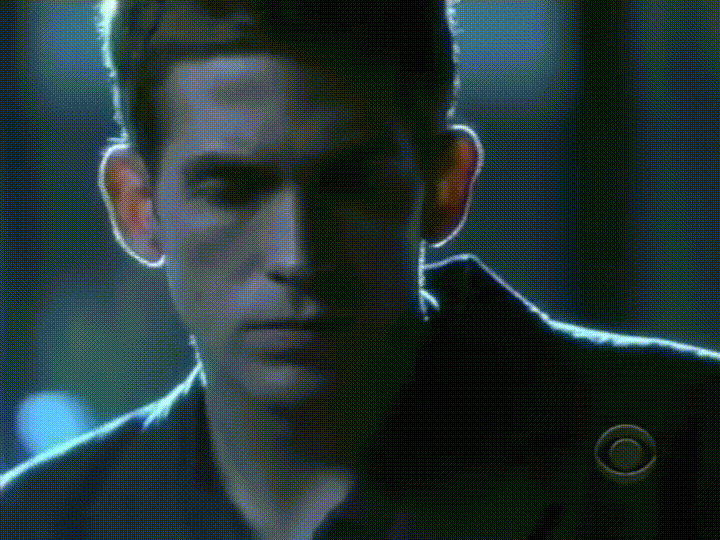
nejspolehlivější způsob, jak změřit plochu
Ok, takže měření by mělo shromažďujeme od sebe v tvář postavit naše známá tvář databáze? Velikost ucha? Délka nosu? Barva očí? Ještě něco?
ukazuje se, že měření, která se nám lidem zdají zřejmá (jako barva očí), nemají pro počítač, který se dívá na jednotlivé pixely v obraze, smysl. Vědci zjistili, že nejpřesnějším přístupem je nechat počítač zjistit měření, aby se sám shromáždil. Hluboké učení dělá lepší práci než lidé při zjišťování, které části obličeje jsou důležité měřit.
řešením je vycvičit hlubokou konvoluční neuronovou síť (stejně jako v části 3). Ale místo toho, školení, sítě rozpoznat obrázky objektů, jako jsme to udělali minule, budeme trénovat generovat 128 měření pro každý obličej.
tréninkový proces funguje tím, že při pohledu na 3 obrazy tváří najednou:
- Zatížení školení tvář obraz známé osoby
- Načíst další snímek téhož známá osoba
- Načíst obrázek úplně jiný člověk,
Pak se algoritmus podívá na měření je v současné době generování pro každý z těchto tří snímků. To pak vylepšení neuronové sítě mírně, takže to zajišťuje, že měření generuje pro #1 a #2 jsou o něco užší, zatímco ujistěte se, že měření pro #2 a #3 jsou mírně dál od sebe:

Po opakování tohoto kroku miliony krát za miliony obrázků z tisíce různých lidí, neuronové sítě učí spolehlivě generovat 128 měření pro každou osobu. Každých deset různých obrázků stejné osoby by mělo poskytnout zhruba stejná měření.
strojové učení lidé nazývají 128 měření každé tváře vložením. Myšlenka redukovat složitá surová data, jako je obrázek, na seznam počítačem generovaných čísel, přichází hodně ve strojovém učení (zejména v jazykovém překladu). Přesný přístup pro tváře, které používáme, byl vynalezen v roce 2015 výzkumníky společnosti Google, ale existuje mnoho podobných přístupů.
Kódování náš obličej obrázek
Tento proces školení konvoluční neuronové sítě výstup tvář embeddings vyžaduje hodně dat a napájení počítače. I s drahou grafickou kartou NVidia Telsa trvá dobrá přesnost přibližně 24 hodin nepřetržitého tréninku.
ale jakmile je síť vyškolena, může generovat měření pro jakoukoli tvář, dokonce i pro ty, které nikdy předtím neviděla! Tento krok je tedy třeba provést pouze jednou. Naštěstí pro nás, skvělí lidé v OpenFace to již udělali a zveřejnili několik vyškolených sítí,které můžeme přímo použít. Díky Brandon Amos a tým!
takže vše, co musíme udělat sami, je spustit naše snímky obličeje prostřednictvím jejich předem vyškolené sítě, abychom získali 128 měření pro každou tvář. Tady je měření pro náš test obrázek:

Takže, jaké části obličeje jsou tyto čísla 128 měření přesně? Ukázalo se, že nemáme tušení. Pro nás je to vlastně jedno. Vše, co nám záleží, je, že síť generuje téměř stejná čísla při pohledu na dva různé obrázky stejné osoby.
Pokud si chcete tento krok vyzkoušet sami, OpenFace poskytuje skript lua, který vygeneruje vložení všech obrázků do složky a zapíše je do souboru csv. Běž to takhle.
Krok 4: nalezení jména osoby z kódování
Tento poslední krok je ve skutečnosti nejjednodušším krokem v celém procesu. Jediné, co musíme udělat, je najít osobu v naší databázi známých lidí, která má nejbližší měření k našemu testovacímu obrazu.
můžete to udělat pomocí libovolného základního algoritmu klasifikace strojového učení. Nejsou potřeba žádné fantastické triky hlubokého učení. Použijeme jednoduchý lineární SVM klasifikátor, ale spousta klasifikačních algoritmů by mohla fungovat.
vše, co musíme udělat, je vycvičit klasifikátor, který dokáže provést měření z nového zkušebního obrazu a řekne, která známá osoba je nejbližší shoda. Spuštění tohoto klasifikátoru trvá milisekundy. Výsledkem klasifikátoru je jméno osoby!
tak pojďme vyzkoušet náš systém. Nejprve jsem trénoval klasifikátor s vložením asi 20 obrázků z každého z Will Ferrell, Chad Smith a Jimmy Falon: