BasicsEdit
za Prvé, některé slovní zásoby:
| aktivace | = hodnota stavu neuronu. U binárních neuronů je to obvykle 0 / 1 nebo +1 / -1. |
| CAM | = obsah adresovatelná paměť. Vyvolání paměti částečným vzorem místo adresy paměti. |
| konvergence | = stabilizace aktivačního vzoru v síti. V SL konvergence znamená stabilizaci závaží & zkreslení spíše než aktivace. |
| diskriminační | = vztahující se k rozpoznávacím úkolům. Také se nazývá analýza (v teorii vzorů) nebo inference. |
| energie | = makroskopická veličina popisující aktivační vzorec v síti. (viz níže) |
| generalizace | = chová přesně na dříve osn setkal vstupy |
| generativní | = Stroj představit a připomenout úkol. někdy se nazývá syntéza (v teorii vzorů), mimikry nebo hluboké padělky. |
| inference | = fáze“ běhu “ (na rozdíl od tréninku). Během odvození síť provádí úkol, na který je vyškolena-buď rozpozná vzor (SL), nebo jej vytvoří (UL). Obvykle odvození sestupuje gradient energetické funkce. Na rozdíl od SL dochází k gradientnímu sestupu během tréninku, nikoli k závěru. |
| strojové vidění | = strojové učení na obrázcích. |
| NLP | = zpracování přirozeného jazyka. Strojové učení lidských jazyků. |
| vzor | = síťová aktivace, která má vnitřní pořádek v nějaký smysl, nebo to může být popsán více kompaktně tím, že funkce ve aktivací. Například pixelový vzor nuly, ať už je dán jako data nebo si představuje síť, má funkci, kterou lze popsat jako jednu smyčku. Funkce jsou zakódovány ve skrytých neuronech. |
| školení | = fáze učení. Zde síť upravuje své váhy & zkreslení, aby se poučila ze vstupů. |
Úkoly

UL obvykle připravují síť spíše pro generativní úkoly než pro rozpoznávání, ale seskupování úkolů pod dohledem nebo ne může být mlhavé. Například rozpoznávání rukopisu začalo v 80. letech jako SL. Pak v roce 2007, UL se používá k prime sítě pro SL později. V současné době SL získala svou pozici lepší metody.
Školení
Během fáze učení, bez dozoru, síť se snaží napodobit údajů, to je dáno a využívá chyby v jeho napodobil výstup opravit sám (např. jeho váhy & zkreslení). To se podobá mimikrickému chování dětí, když se učí jazyk. Někdy je chyba vyjádřena jako nízká pravděpodobnost, že dojde k chybnému výstupu, nebo může být vyjádřena jako nestabilní vysokoenergetický stav v síti.
energie
energetická funkce je makroskopickým měřítkem stavu sítě. Tato analogie s fyzikou je inspirován Ludwig Boltzmann je analýza plynu‘ makroskopické energie z mikroskopického pravděpodobnosti částice pohybu p ∝ {\displaystyle \propto }

eE/kT, kde k je Boltzmannova konstanta a T je teplota. V MKP sítě vztah je p = e-E / Z, kde p & E vary přes všechny možné aktivační vzor a Z = ∑ l l P a t t e r n y {\displaystyle \sum _{AllPatterns}}

e -E(vzor). Přesněji řečeno, p (A) = e-E (a) / Z, kde a je aktivační vzorec všech neuronů(viditelných i skrytých). Proto rané neuronové sítě nesou název Boltzmannův stroj. Paul Smolensky volá-E harmonii. Síť hledá nízkou energii, což je vysoká harmonie.
Sítě
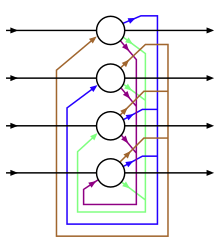
| Hopfield | Boltzmann | MKP | Helmholtzova | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
 |
 autoencoder
|
 variační autoencoder
|
Boltzmann a Helmholtzova přišel před neuronové sítě formulace, ale tyto sítě půjčil si od jejich analýzy, tak tyto sítě nesou jejich jména. Hopfield však přímo přispěl k UL.
meziprodukt
zde budou distribuce p (x) a q(x) zkráceny jako p A q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. To je většinou používán v SL, ale zaslouží zmínku zde. |
| 1982 | Ising variant Hopfield net popsal jako vačky a klasifikátory John Hopfield. |
| 1983 | Ising varianta Boltzmannův stroj s pravděpodobnostní neurony popsal Hinton & Sejnowski následující Sherington & Kirkpatrick 1975 práce. |
| 1986 | Paul Smolensky vydává Harmonie Teorie, která je MKP s prakticky stejnou Boltzmannův energetické funkce. Smolenský nedal praktický výcvikový program. Hinton udělal v polovině-2000s |
| 1995 | Schmidthuber zavádí LSTM neuron pro jazyky. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| Pravděpodobnost | |
| cdf | = kumulativní distribuční funkce. integrál pdf. Pravděpodobnost přiblížení se k 3 je plocha pod křivkou mezi 2,9 a 3,1. |
| kontrastivní divergence | = učební metoda, kdy jeden snižuje energii na trénink vzory a vyvolává energii na nežádoucí vzory mimo trénovací množiny. To je velmi odlišné od KL-divergence, ale sdílí podobné znění. |
| očekávaná hodnota | = E(x) = ∑ x {\displaystyle \sum _{x}}
 x * p(x). Toto je střední hodnota nebo průměrná hodnota. Pro spojitý vstup x nahraďte součet integrálem. |
| latentní proměnná | = nepozorovaná veličina, která pomáhá vysvětlit pozorovaná data. například chřipková infekce (nepozorovaná) může vysvětlit, proč člověk kýchá (pozorováno). V pravděpodobnostních neuronových sítích působí skryté neurony jako latentní proměnné, i když jejich latentní interpretace není explicitně známa. |
| = funkce hustoty pravděpodobnosti. Pravděpodobnost, že náhodná proměnná nabývá určité hodnoty. Pro kontinuální pdf, p (3) = 1/2 může stále znamenat, že je téměř nulová šance na dosažení této přesné hodnoty 3. Racionalizujeme to pomocí cdf. | |
| stochastic | = chová se podle dobře popsaného vzorce hustoty pravděpodobnosti. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Je to maximální reverzibilní práce, která může být prováděna tepelným systémem při konstantní teplotě a tlaku. volná energie G = teplo – teplota * entropie |
| informace | = informace, výši zprávu x = -log p(x) |
| – | = relativní entropie. Pro pravděpodobnostní sítě je to analog chyby mezi vstupem & napodobený výstup. Divergence Kullback-Liebler (KLD) měří entropickou odchylku 1 distribuce od jiné distribuce. KLD(p,q) = ∑ x {\displaystyle \sum _{x}}
p * log( p / q ). Obvykle p odráží vstupní data, q odráží interpretaci sítě a KLD odráží rozdíl mezi nimi. |
Srovnání Sítí,
| Hopfield | Boltzmann | MKP | Helmholtzova | Autoencoder | VAE | |
|---|---|---|---|---|---|---|
| použití & osobnosti | CAM, problém obchodního cestujícího | CAM. Svoboda připojení ztěžuje analýzu této sítě. | rozpoznávání vzorů (MNIST, rozpoznávání řeči) | imaginace, mimikry | jazyk: kreativní psaní, překlad. Vize: vylepšení rozmazaných obrázků | generovat realistická data |
| neuron | deterministický binární stav. Aktivace = { 0 (nebo -1), pokud je x záporné, 1 jinak } | stochastické binární Hopfield neuronu | stochastické binární. Rozšířeno na reálné hodnoty v polovině 2000s | binární, sigmoid | jazyk: LSTM. vize: místní vnímavá pole. obvykle real valu aktivace. | |
| připojení | 1-vrstva se symetrickými váhami. Žádné vlastní spojení. | 2 vrstvy. 1-skrytý & 1-viditelný. symetrické váhy. | 2 vrstvy. symetrické váhy. žádné boční spojení uvnitř vrstvy. | 3 vrstvy: asymetrické váhy. 2 sítě sloučeny do 1. | 3 vrstvy. Vstup je považován za vrstvu, i když nemá žádné příchozí váhy. opakující se vrstvy pro NLP. dopředné konvoluce pro vidění. vstup & výstup má stejný počet neuronů. | 3-vrstvy: vstup, kodér, dekodér distribučního sampleru. sampler není považována za vrstvu (e) |
| závěr & energie | energie je dána tím, že Gibbs pravděpodobnost opatření : E = − 1 2 ∑ i , j w i j y j + ∑ jsem θ i y i {\displaystyle E=-{\frac {1}{2}}\sum _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\sum _{i}{\theta _{i}}{s_{i}}}
 |
← stejné | ← stejné | minimalizaci KL divergence | závěr je pouze posuv. předchozí UL sítí běžel dopředu A dozadu | minimalizovat chyby = rekonstrukce chyba – KLD |
| školení | Δwij = si*sj, +1/-1 neuronu | Δwij = e*(pij – p’ij). To je odvozeno z minimalizace KLD. e = míra učení, p ‚ = predikované a p = skutečné rozdělení. | kontrastivní divergence w/ Gibbs Sampling | wake-spánku 2 fáze vzdělávání | zadní šířit rekonstrukce chyba | reparameterize skryté státu pro backprop |
| pevnost | podobá fyzikální systémy, takže to dědí jejich rovnice | <— stejné. skryté neurony působí jako vnitřní reprezentace vnějšího světa | rychlejší praktičtější tréninkové schéma než Boltzmannovy stroje | mírně anatomické. analyzovatelný w/ teorie informace & statistické mechaniky | ||
| slabost | hopfield | tvrdě trénovat v důsledku boční připojení | MKP | Helmholtzova |
Konkrétní Sítě
Tady, jsme se poukázat na některé vlastnosti jednotlivých sítí. Feromagnetismus inspiroval Hopfieldovy sítě, Boltzmannovy stroje a MKP. Neuron odpovídá železné doméně s binárními magnetickými momenty nahoru a dolů a neurální spojení odpovídají vzájemnému vlivu domény. Symetrické připojení umožňuje globální formulaci energie. Během odvození síť aktualizuje každý stav pomocí standardní funkce aktivačního kroku. Symetrické váhy zaručují konvergenci ke stabilnímu aktivačnímu vzoru.
Hopfieldovy sítě se používají jako kamery a je zaručeno, že se usadí na nějakém vzoru. Bez symetrických závaží je síť velmi těžko analyzovatelná. Se správnou energetickou funkcí se síť sblíží.
Boltzmannovy stroje jsou stochastické Hopfieldovy sítě. Jejich stav se hodnota vzorku z tohoto pdf takto: předpokládejme, že binární neuron vyšle s Bernoulliho pravděpodobnost p(1) = 1/3 a spočívá s p(0) = 2/3. Jeden vzorků z to tím, že ROVNOMĚRNĚ náhodné číslo y, a připojíte jej do inverzní kumulativní distribuční funkci, což v tomto případě je funkce krok thresholded na 2/3. Inverzní funkce = { 0, pokud x <= 2/3, 1, pokud je x > 2/3 }
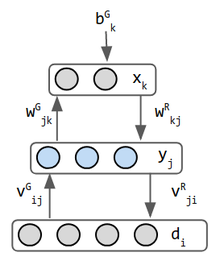
Helmholtzova stroje jsou rané inspirace pro Variační Auto Snímačů. Jsou to 2 sítě kombinované do jednoho-dopředná závaží operují rozpoznávání a zpětná závaží implementují představivost. Je to možná první síť, která dělá obojí. Helmholtz nepracoval ve strojovém učení, ale inspiroval pohled na „statistický inferenční motor, jehož funkcí je odvodit pravděpodobné příčiny smyslového vstupu“ (3). stochastický binární neuron vydává pravděpodobnost, že jeho stav je 0 nebo 1. Vstup dat se obvykle nepovažuje za vrstvu, ale v režimu generování stroje Helmholtz, datová vrstva přijímá vstup ze střední vrstvy má pro tento účel samostatné váhy, takže se považuje za vrstvu. Proto má tato síť 3 vrstvy.
variační Autoencoder (VAE) je inspirován stroji Helmholtz a kombinuje pravděpodobnostní síť s neuronovými sítěmi. Autoencoder je 3VRSTVÁ CAM síť, kde střední vrstva má být nějakou vnitřní reprezentací vstupních vzorů. Váhy jsou pojmenovány phi & theta spíše než W A V jako v Helmholtz-kosmetický rozdíl— Kódovací neuronová síť je distribuce pravděpodobnosti qφ (z|x) a dekodérová síť je pθ (x / z). Tyto 2 sítě zde mohou být plně připojeny nebo použít jiné schéma NN.
Hebbian Learning, ART, SOM
klasický příklad učení bez učitele ve studiu neuronových sítí je Donald Hebb principu, to znamená, že neurony, které společně oheň drátu dohromady. V Hebbian learning, spojení je vyztužený bez ohledu na chyby, ale je výhradně funkcí shoda mezi akční potenciály mezi dvěma neurony. Podobná verze, která modifikuje synaptické váhy, bere v úvahu čas mezi akčními potenciály (plasticita závislá na spike-timing nebo STDP). Předpokládá se, že hebbovské učení je základem řady kognitivních funkcí, jako je rozpoznávání vzorů a zkušenostní učení.
mezi modely neuronových sítí se samoorganizující mapa (SOM) a teorie adaptivní rezonance (ART) běžně používají v algoritmech učení bez dozoru. SOM je topografická organizace, ve které Blízká místa na mapě představují vstupy s podobnými vlastnostmi. ART model umožňuje počet shluků měnit s velikostí problému a umožňuje uživateli ovládat stupeň podobnosti mezi členy stejných shluků pomocí uživatelem definované konstanty zvané parametr vigilance. Umělecké sítě se používají pro mnoho úloh rozpoznávání vzorů, jako je automatické rozpoznávání cílů a zpracování seismických signálů.