
Klassificeringsteknikker er en væsentlig del af maskinindlæring og data mining applikationer. 70% af problemerne inden for datalogi er klassificeringsproblemer. Der er mange klassificeringsproblemer, der er tilgængelige, men logistikregressionen er almindelig og er en nyttig regressionsmetode til løsning af det binære klassificeringsproblem. En anden kategori af klassificering er Multinomial klassificering, som håndterer de problemer, hvor flere klasser er til stede i målvariablen. For eksempel IRIS datasæt et meget berømt eksempel på klassificering i flere klasser. Andre eksempler er klassificering artikel / blog / dokument kategori.
logistisk Regression kan bruges til forskellige klassificeringsproblemer såsom spamdetektion. Diabetes forudsigelse, hvis en given kunde vil købe et bestemt produkt, eller vil de churn en anden konkurrent, om brugeren vil klikke på en given annonce link eller ej, og mange flere eksempler er i spanden.logistisk Regression er en af de mest enkle og almindeligt anvendte maskinlæringsalgoritmer til klassificering i to klasser. Det er let at implementere og kan bruges som basislinje for ethvert binært klassificeringsproblem. Dens grundlæggende grundlæggende begreber er også konstruktive i dyb læring. Logistisk regression beskriver og estimerer forholdet mellem en afhængig binær variabel og uafhængige variabler.
i denne vejledning lærer du følgende ting i logistisk Regression:
- Introduktion til logistisk Regression
- lineær Regression Vs. logistisk Regression
- maksimal Sandsynlighedsestimering Vs. almindelig mindst kvadratisk metode
- Hvordan fungerer logistisk Regression?
- modelbygning i Scikit-Lær
- Modelevaluering ved hjælp af Forvirringsmatrice.
- fordele og ulemper ved logistisk Regression
logistisk Regression
logistisk regression er en statistisk metode til forudsigelse af binære klasser. Resultatet eller målvariablen er dikotom i naturen. Dikotom betyder, at der kun er to mulige klasser. For eksempel kan det bruges til kræftdetekteringsproblemer. Det beregner sandsynligheden for en begivenhed forekomst.
det er et specielt tilfælde af lineær regression, hvor målvariablen er kategorisk. Det bruger en log af odds som den afhængige variabel. Logistic Regression predicts the probability of occurrence of a binary event utilizing a logit function.
Linear Regression Equation:
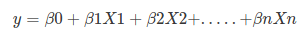
Where, y is dependent variable and x1, x2 … and Xn are explanatory variables.
Sigmoid Function:
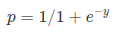
Apply Sigmoid function on linear regression:
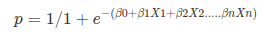
Properties of Logistic Regression:
- den afhængige variabel i logistisk regression følger Bernoulli Distribution.
- estimering sker gennem maksimal sandsynlighed.
- ingen R-firkant, model fitness beregnes gennem overensstemmelse, KS-statistik.
lineær Regression Vs. logistisk Regression
lineær regression giver dig en kontinuerlig output, men logistisk regression giver en konstant output. Et eksempel på den kontinuerlige produktion er huspris og aktiekurs. Eksempel på den diskrete output er at forudsige, om en patient har kræft eller ej, forudsige, om kunden vil churn. Lineær regression estimeres ved hjælp af almindelige mindste kvadrater (OLS), mens logistisk regression estimeres ved hjælp af maksimal Sandsynlighedsestimering (MLE) tilgang.

maksimal Sandsynlighedsestimering Vs. mindste kvadratisk metode
MLE er en” sandsynlighed ” maksimeringsmetode, mens OLS er en afstandsminimerende tilnærmelsesmetode. Maksimering af sandsynlighedsfunktionen bestemmer de parametre, der mest sandsynligt producerer de observerede data. Fra et statistisk synspunkt indstiller MLE middelværdien og variansen som parametre til bestemmelse af de specifikke parameterværdier for en given model. Dette sæt parametre kan bruges til at forudsige de nødvendige data i en normalfordeling.
almindelige estimater for mindste kvadrater beregnes ved at montere en regressionslinje på givne datapunkter, der har minimumssummen af de kvadratiske afvigelser (mindste kvadratfejl). Begge bruges til at estimere parametrene for en lineær regressionsmodel. MLE antager en fælles sandsynlighedsmassefunktion, mens OLS ikke kræver nogen stokastiske antagelser for at minimere afstanden.
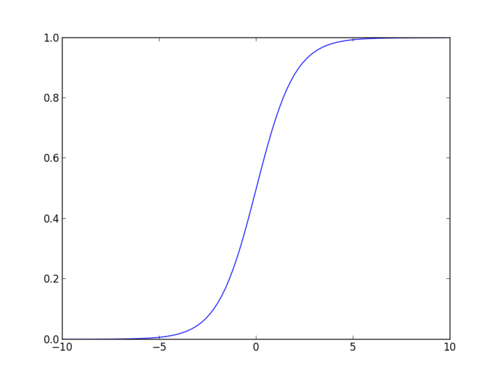
Sigmoid-funktion
sigmoid-funktionen, også kaldet logistisk funktion, giver en ‘S’ formet kurve, der kan tage ethvert reelt værdsat tal og kortlægge det til en værdi mellem 0 og 1. Hvis kurven går til positiv uendelighed, y forudsagt bliver 1, og hvis kurven går til negativ uendelighed, y forudsagt bliver 0. Hvis udgangen af sigmoid-funktionen er mere end 0,5, kan vi klassificere resultatet som 1 eller ja, og hvis det er mindre end 0.5, Vi kan klassificere det som 0 eller nej. Outputkan ikkefor eksempel: hvis output er 0,75, kan vi sige med hensyn til Sandsynlighed som: der er en 75 procent chance for, at patienten vil lide af kræft.
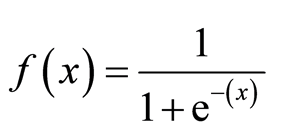
typer af logistisk regression
typer af logistisk regression:
- binær logistisk regression: målvariablen har kun to mulige resultater såsom spam eller ikke spam, kræft eller ingen kræft.Multinomial logistisk Regression: målvariablen har tre eller flere nominelle kategorier, såsom at forudsige typen af vin.
- ordinær logistisk Regression: målvariablen har tre eller flere ordinære kategorier såsom restaurant eller produktvurdering fra 1 til 5.
modelbygning i Scikit-Lær
lad os bygge diabetesforudsigelsesmodellen.
Her skal du forudsige diabetes ved hjælp af logistisk Regressionsklassifikator.
lad os først indlæse det krævede Pima Indian Diabetes datasæt ved hjælp af pandas’ Læs CSV-funktion. Du kan hente data fra følgende link: https://www.kaggle.com/uciml/pima-indians-diabetes-database
indlæser Data
#import pandasimport pandas as pdcol_names = # load datasetpima = pd.read_csv("pima-indians-diabetes.csv", header=None, names=col_names)pima.head()
valg af funktion
Her skal du opdele de givne kolonner i to typer variabler afhængig(eller målvariabel) og uafhængig variabel(eller funktionsvariabler).
#split dataset in features and target variablefeature_cols = X = pima # Featuresy = pima.label # Target variableopdeling af Data
for at forstå modelpræstation er det en god strategi at opdele datasættet i et træningssæt og et testsæt.
lad os opdele datasæt ved hjælp af funktionen train_test_split(). Du er nødt til at passere 3 parametre funktioner, mål, og test_set størrelse. Derudover kan du bruge random_state til at vælge poster tilfældigt.
# split X and y into training and testing setsfrom sklearn.cross_validation import train_test_splitX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=0)/home/admin/.local/lib/python3.5/site-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also, note that the interface of the new CV iterators is different from that of this module. This module will be removed in 0.20. "This module will be removed in 0.20.", DeprecationWarning)Her er datasættet opdelt i to dele i et forhold på 75:25. Det betyder, at 75% data vil blive brugt til model træning og 25% til model test.
modeludvikling og forudsigelse
Importer først det logistiske Regressionsmodul og opret et logistisk Regressionsklassificeringsobjekt ved hjælp af LogisticRegression () – funktion.
tilpas derefter din model på togsættet ved hjælp af fit() og udfør forudsigelse på testsættet ved hjælp af predict().
# import the classfrom sklearn.linear_model import LogisticRegression# instantiate the model (using the default parameters)logreg = LogisticRegression()# fit the model with datalogreg.fit(X_train,y_train)#y_pred=logreg.predict(X_test)Modelevaluering ved hjælp af Forvirringsmatrice
en forvirringsmatrice er en tabel, der bruges til at evaluere ydeevnen for en klassificeringsmodel. Du kan også visualisere udførelsen af en algoritme. Grundlaget for en forvirringsmatrice er antallet af korrekte og forkerte forudsigelser opsummeres klassemæssigt.
# import the metrics classfrom sklearn import metricscnf_matrix = metrics.confusion_matrix(y_test, y_pred)cnf_matrixarray(, ])Her kan du se forvirringsmatricen i form af array-objektet. Dimensionen af denne matrice er 2*2, fordi denne model er binær klassificering. Du har to klasser 0 og 1. Diagonale værdier repræsenterer nøjagtige forudsigelser, mens ikke-diagonale elementer er unøjagtige forudsigelser. I output er 119 og 36 faktiske forudsigelser, og 26 og 11 er forkerte forudsigelser.
visualisering af Forvirringsmatrice ved hjælp af Heatmap
lad os visualisere resultaterne af modellen i form af en forvirringsmatrice ved hjælp af matplotlib og seaborn.
Her vil du visualisere forvirringsmatricen ved hjælp af Heatmap.
# import required modulesimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlineclass_names= # name of classesfig, ax = plt.subplots()tick_marks = np.arange(len(class_names))plt.xticks(tick_marks, class_names)plt.yticks(tick_marks, class_names)# create heatmapsns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')ax.xaxis.set_label_position("top")plt.tight_layout()plt.title('Confusion matrix', y=1.1)plt.ylabel('Actual label')plt.xlabel('Predicted label')Text(0.5,257.44,'Predicted label')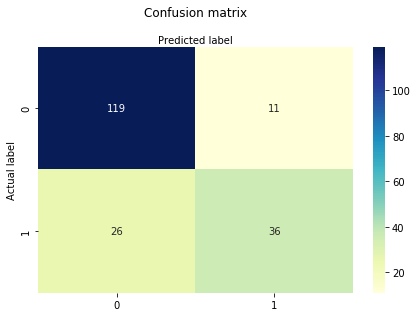
forvirringsmatrice evalueringsmålinger
lad os evaluere modellen ved hjælp af modelevalueringsmålinger som nøjagtighed, præcision og tilbagekaldelse.
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))print("Precision:",metrics.precision_score(y_test, y_pred))print("Recall:",metrics.recall_score(y_test, y_pred))Accuracy: 0.8072916666666666Precision: 0.7659574468085106Recall: 0.5806451612903226Nå, du har en klassificeringsgrad på 80%, betragtes som god nøjagtighed.
præcision: præcision handler om at være præcis, dvs.hvor præcis din model er. Med andre ord kan du sige, når en model gør en forudsigelse, hvor ofte det er korrekt. I dit forudsigelsestilfælde, når din logistiske regressionsmodel forudsagte patienter vil lide af diabetes, har patienterne 76% af tiden.
husk: hvis der er patienter, der har diabetes i testsættet, og din logistiske regressionsmodel kan identificere den 58% af tiden.
ROC Curve
Receiver Operating Characteristic(ROC) curve er et plot af den sande positive rate mod den falske positive rate. Det viser afvejningen mellem følsomhed og specificitet.
y_pred_proba = logreg.predict_proba(X_test)fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)auc = metrics.roc_auc_score(y_test, y_pred_proba)plt.plot(fpr,tpr,label="data 1, auc="+str(auc))plt.legend(loc=4)plt.show()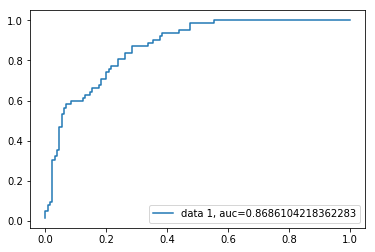
AUC score for sagen er 0,86. AUC score 1 repræsenterer perfekt klassifikator, og 0,5 repræsenterer en værdiløs klassifikator.
fordele
på grund af sin effektive og ligetil karakter kræver det ikke høj beregningskraft, let at implementere, let fortolkelig, brugt bredt af dataanalytiker og videnskabsmand. Det kræver heller ikke skalering af funktioner. Logistisk regression giver en sandsynlighedsscore for observationer.
ulemper
logistisk regression er ikke i stand til at håndtere et stort antal kategoriske træk / variabler. Det er sårbart over for overmontering. Kan heller ikke løse det ikke-lineære problem med den logistiske regression, hvorfor det kræver en transformation af ikke-lineære funktioner. Logistisk regression fungerer ikke godt med uafhængige variabler, der ikke er korreleret med målvariablen og er meget ens eller korreleret med hinanden.
konklusion
i denne vejledning dækkede du mange detaljer om logistisk Regression. Du har lært, hvad den logistiske regression er, hvordan man bygger respektive modeller, hvordan man visualiserer resultater og nogle af de teoretiske baggrundsoplysninger. Du dækkede også nogle grundlæggende begreber som sigmoid-funktionen, maksimal sandsynlighed, forvirringsmatrice, ROC-kurve.
forhåbentlig kan du nu bruge den logistiske Regressionsteknik til at analysere dine egne datasæt. Tak for at læse denne tutorial!
Hvis du gerne vil lære mere om logistisk Regression, skal du tage DataCamp ‘ s Foundations of Predictive Analytics i Python (Del 1) kursus.