
i denne vejledning lærer du logistisk regression. Her ved du, hvad der præcist er logistisk Regression, og du vil også se et eksempel med Python. Logistisk Regression er et vigtigt emne for maskinindlæring, og jeg vil forsøge at gøre det så enkelt som muligt.
i begyndelsen af det tyvende århundrede blev logistisk regression hovedsageligt brugt i biologi efter dette blev den brugt i nogle samfundsvidenskabelige applikationer. Hvis du er nysgerrig, kan du spørge, hvor vi skal bruge logistisk regression? Så vi bruger logistisk Regression, når vores uafhængige variabel er kategorisk.
eksempler:
- for at forudsige, om en person vil købe en bil (1) eller (0)
- for at vide, om tumoren er ondartet (1) eller (0)
lad os nu overveje et scenario, hvor du skal klassificere, om en person vil købe en bil eller ej. I dette tilfælde, hvis vi bruger simpel lineær regression, skal vi angive en tærskel, hvorpå klassificering kan udføres.
lad os sige, at den faktiske klasse er, at personen vil købe bilen, og den forudsagte kontinuerlige værdi er 0,45, og den tærskel, vi har overvejet, er 0.5, så vil dette datapunkt blive betragtet som personen ikke vil købe bilen, og dette vil føre til den forkerte forudsigelse.
så vi konkluderer, at vi ikke kan bruge lineær regression til denne type klassificeringsproblem. Som vi ved, er lineær regression afgrænset, så her kommer logistisk regression, hvor værdien strengt varierer fra 0 til 1.
simpel logistisk Regression:
Output: 0 eller 1
hypotese: K = H * * * + B
h-lys(h) = sigmoid(K)
sigmoid funktion:


typer af logistisk Regression:
binær logistisk Regression
kun to mulige resultater(Kategori).
eksempel: personen vil købe en bil eller ej.
Multinomial logistisk Regression
mere end to kategorier muligt uden bestilling.
ordinær logistisk Regression
mere end to kategorier muligt med bestilling.
virkelige eksempel med Python:
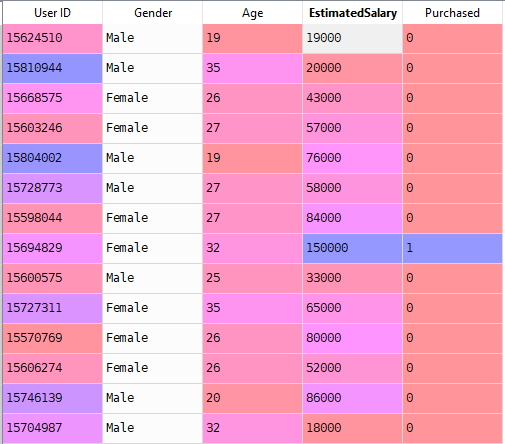
nu løser vi et virkeligt problem med logistisk Regression. Vi har et datasæt med 5 kolonner nemlig: bruger-ID, køn, alder, Estimatedlønning og købt. Nu skal vi bygge en model, der kan forudsige, om en person på den givne parameter vil købe en bil eller ej.
trin til at bygge modellen:
1. Importing the libraries
Her importerer vi biblioteker, som er nødvendige for at opbygge modellen.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
Vi importerer vores datasæt i en variabel (dvs.datasæt) ved hjælp af pandaer.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
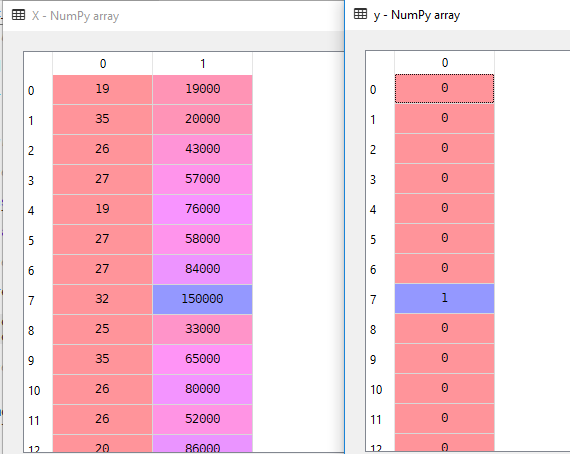
i vores datasæt betragter vi alder og estimatedlønning som uafhængig variabel og købt som afhængig variabel.
X = dataset.iloc].valuesy = dataset.iloc.valuesHer er uafhængig variabel og y er afhængig variabel.
3. Splitting the Data set into the Training Set and Test Set
nu deler vi vores datasæt i træningsdata og testdata. Træningsdata vil blive brugt til at træne vores logistiske model, og testdata vil blive brugt til at validere vores model. Vi bruger Sklearn til at opdele vores data. Vi importerer train_test_split fra sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
nu skal vi udføre funktionsskalering for at skalere vores data mellem 0 og 1 for at få bedre nøjagtighed.
her er skalering vigtig, fordi der er en enorm forskel mellem alder og EstimatedSalay.
- Importer StandardScaler fra sklearn.forbehandling
- lav derefter en forekomst af objektstandardskaleren
- tilpas derefter og transform S_train og transform S_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
nu bygger vi vores klassifikator (Logistik).
- Importer Logistikregression fra sklearn.linear_model
- lav en forekomstklassifikator af objektet LogisticRegression og giv
random_state = 0 for at få det samme resultat hver gang. - brug nu denne klassifikator til at passe til Y_train og y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)skål!! Når du har udført ovenstående kommando, har du en klassifikator, der kan forudsige, om en person vil købe en bil eller ej.
brug nu klassifikatoren til at forudsige Testdatasættet og finde nøjagtigheden ved hjælp af Forvirringsmatricen.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)nu får vi y_pred

nu kan vi bruge y_test (faktisk resultat) og y_pred ( forudsagt resultat) for at få nøjagtigheden af vores model.
7. Making the Confusion Matrix
Ved hjælp af Forvirringsmatrice kan vi få nøjagtigheden af vores model.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)Du får en matrice cm .

brug cm til at beregne nøjagtighed som vist nedenfor:
nøjagtighed = (cm + cm) /(Total test datapunkter)

Her får vi nøjagtighed på 89 % . Skål!! vi får en god nøjagtighed.
endelig vil vi visualisere vores træning sæt resultat og Test sæt resultat. Vi bruger matplotlib til at plotte vores datasæt.
visualisering af Træningssættets resultat
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()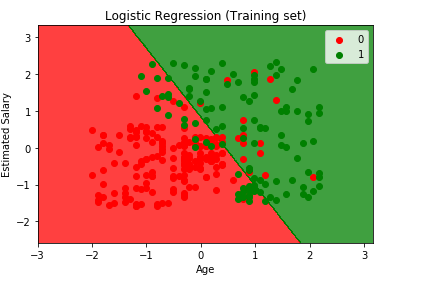
visualisering af Testsættets resultat
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
nu kan du opbygge din egen klassifikator til logistisk regression.
Tak!! Bliv Ved Med At Kode !!
Bemærk: Dette er et gæstepost, og udtalelsen i denne artikel er af gæsteforfatteren. Hvis du har problemer med nogen af de artikler, der er sendt på
Advertisement
