ansigtsgenkendelse — trin for trin
lad os tackle dette problem et trin ad gangen. For hvert trin lærer vi om en anden maskinlæringsalgoritme. Jeg vil ikke forklare hver eneste algoritme fuldstændigt for at forhindre, at dette bliver til en bog, men du lærer de vigtigste ideer bag hver enkelt, og du lærer, hvordan du kan opbygge dit eget ansigtsgenkendelsessystem i Python ved hjælp af OpenFace og dlib.
Trin 1: At finde alle ansigterne
det første skridt i vores pipeline er ansigtsgenkendelse. Det er klart, at vi er nødt til at finde ansigterne på et fotografi, før vi kan prøve at skelne dem fra hinanden!
Hvis du har brugt et kamera i de sidste 10 år, har du sikkert set ansigtsgenkendelse i aktion:

ansigtsgenkendelse er en fantastisk funktion til kameraer. Når kameraet automatisk kan udvælge ansigter, kan det sørge for, at alle ansigter er i fokus, før det tager billedet. Men vi bruger det til et andet formål — at finde de områder af billedet, vi vil videregive til næste trin i vores pipeline.ansigtsgenkendelse gik mainstream i begyndelsen af 2000 ‘ erne, da Paul Viola og Michael Jones opfandt en måde at opdage ansigter, der var hurtige nok til at køre på billige kameraer. Der findes dog meget mere pålidelige løsninger nu. Vi skal bruge en metode opfundet i 2005 kaldet Histogram af orienterede gradienter — eller bare HOG for kort.
for at finde ansigter i et billede starter vi med at gøre vores billede sort/hvidt, fordi vi ikke har brug for farvedata for at finde ansigter:

så ser vi på hvert enkelt billede i vores billede en ad gangen. For hvert enkelt punkt, vi ønsker at se på de punkter, der direkte omgiver det:

vores mål er at finde ud af, hvor mørkt det aktuelle punkt er sammenlignet med de punkter, der omgiver det direkte. Så vil vi tegne en pil, der viser i hvilken retning billedet bliver mørkere:

Hvis du gentager denne proces for hvert enkelt punkt på billedet, ender du med, at hvert punkt bliver erstattet af en pil. Disse pile kaldes gradienter, og de viser strømmen fra lys til mørk over hele billedet:
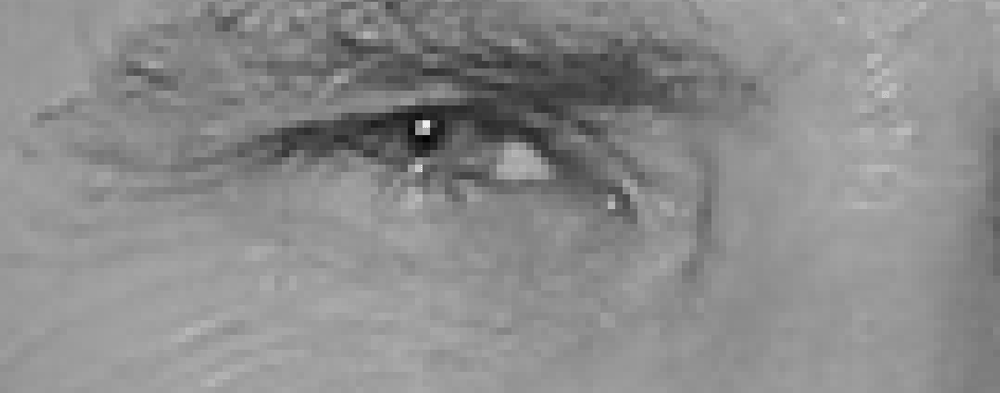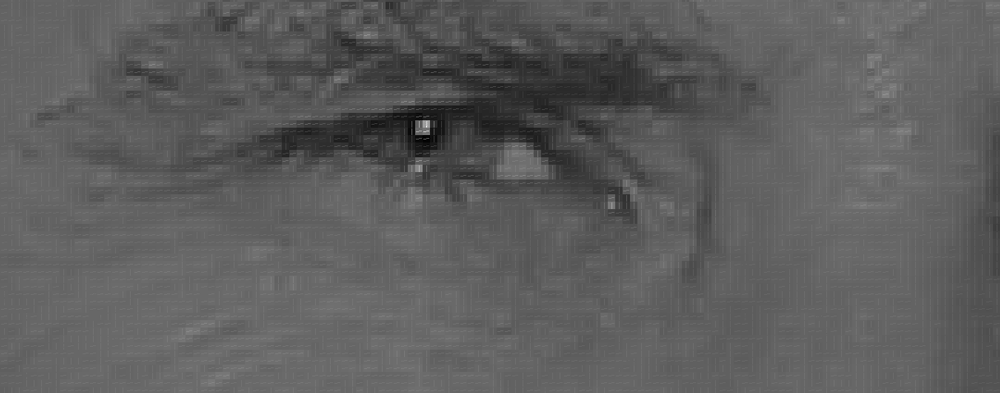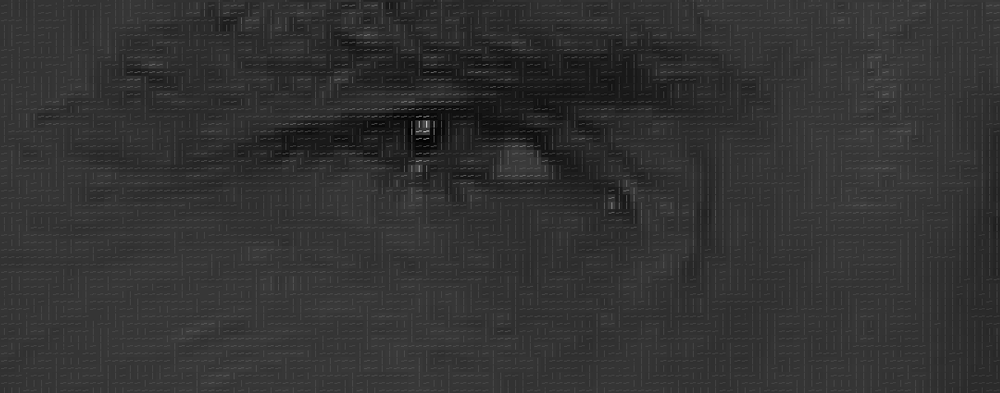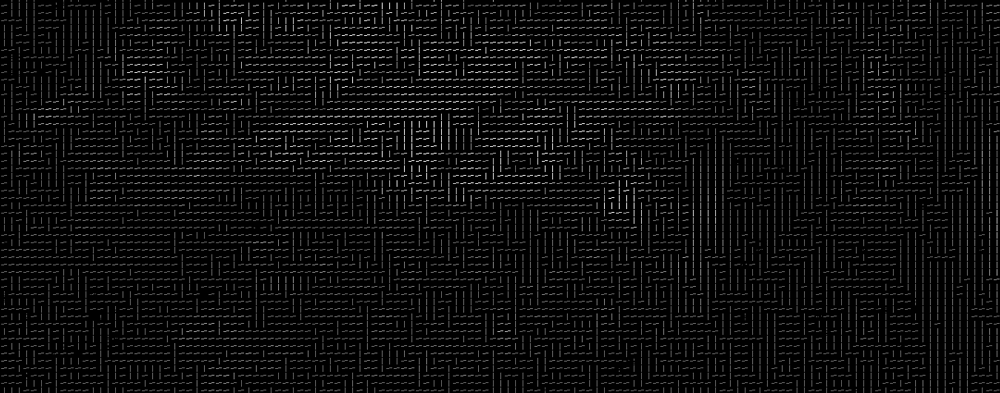
dette kan virke som en tilfældig ting at gøre, men der er en rigtig god grund til at erstatte billedpunkterne med gradienter. Hvis vi analyserer billedpunkter direkte, vil virkelig mørke billeder og virkelig lyse billeder af den samme person have helt forskellige billedværdier. Men ved kun at overveje den retning, som lysstyrken ændrer sig, vil både virkelig mørke billeder og virkelig lyse billeder ende med den samme nøjagtige repræsentation. Det gør problemet meget lettere at løse!
men at gemme gradienten for hvert enkelt punkt giver os alt for mange detaljer. Vi ender med at savne skoven for træerne. Det ville være bedre, hvis vi bare kunne se den grundlæggende strøm af lyshed/mørke på et højere niveau, så vi kunne se billedets grundlæggende mønster.
for at gøre dette vil vi opdele billedet i små firkanter på 16h16 billedpunkter hver. I hver firkant tæller vi op, hvor mange gradienter der peger i hver hovedretning (hvor mange peger op, peger op-højre, peger til højre osv.). Så erstatter vi den firkant i billedet med pilens retninger, der var de stærkeste.
slutresultatet er, at vi forvandler det originale billede til en meget enkel repræsentation, der fanger den grundlæggende struktur af et ansigt på en enkel måde:

for At finde ansigter i denne HOG billede, vi alle skal gøre, er at finde en del af vores image, der ser mest ligner en kendt HOG mønster, der blev udvundet fra en masse andre uddannelse ansigter:

ved Hjælp af denne teknik, vi kan nu nemt finde ansigter i et billede:

Hvis du vil prøve dette trin ud selv ved hjælp af Python og dlib, her er kode, der viser, hvordan du genererer og ser hog repræsentationer af billeder.
Trin 2: poserer og projicerer ansigter
Puha, vi isolerede ansigterne i vores billede. Men nu er vi nødt til at beskæftige sig med det problem, Ansigter vendte forskellige retninger ser helt anderledes til en computer:
for at redegøre for dette vil vi forsøge at kæde hvert billede, så øjnene og læberne altid er på prøvepladsen i billedet. Dette vil gøre det meget lettere for os at sammenligne ansigter i de næste trin.
for at gøre dette skal vi bruge en algoritme kaldet face landmark estimation. Der er mange måder at gøre dette på, men vi vil bruge den tilgang, der blev opfundet i 2014 af Vahid Kasemi og Josephine Sullivan.
grundideen er, at vi vil komme med 68 specifikke punkter (kaldet landemærker), der findes på hvert ansigt — toppen af hagen, ydersiden af hvert øje, indersiden af hvert øjenbryn osv. Derefter træner vi en maskinlæringsalgoritme for at kunne finde disse 68 specifikke punkter på ethvert ansigt:

Her er resultatet af at lokalisere 68 ansigt landemærker på vores testbillede:
nu hvor vi ved, at øjnene og munden er, roterer vi simpelthen, skalerer og forskyder billedet, så øjnene og munden er centreret så godt som muligt. Vi vil ikke lave nogen fancy 3D-kæde, fordi det ville introducere forvrængninger i billedet. Vi vil kun bruge grundlæggende billedtransformationer som rotation og skala, der bevarer parallelle linjer (kaldet affine transformationer):

Nu, uanset hvordan lyset er vendt, vi er i stand til center øjnene og munden er i nogenlunde samme position i billedet. Dette vil gøre vores næste skridt meget mere præcist.
Hvis du vil prøve dette trin selv ved hjælp af Python og dlib, her er koden til at finde ansigt landemærker, og her er koden til at transformere billedet ved hjælp af disse landemærker.
Trin 3: Kodning ansigter
nu er vi til kødet af problemet — faktisk fortæller ansigter fra hinanden. Det er her tingene bliver virkelig interessante!
den enkleste tilgang til ansigtsgenkendelse er direkte at sammenligne det ukendte ansigt, vi fandt i Trin 2, med alle de billeder, vi har af mennesker, der allerede er tagget. Når vi finder et tidligere mærket ansigt, der ligner vores ukendte ansigt, skal det være den samme person. Virker som en ret god ide, ikke?
der er faktisk et stort problem med denne tilgang. Et sted som Facebook med milliarder af brugere og en billion fotos kan umuligt løbe gennem hvert tidligere tagget ansigt for at sammenligne det med hvert nyligt uploadet billede. Det ville tage alt for lang tid. De skal kunne genkende ansigter i millisekunder, ikke timer.
hvad vi har brug for er en måde at udtrække et par grundlæggende målinger fra hvert ansigt. Derefter kunne vi måle vores ukendte ansigt på samme måde og finde det kendte ansigt med de nærmeste målinger. For eksempel kan vi måle størrelsen på hvert øre, afstanden mellem øjnene, næsens længde osv. Hvis du nogensinde har set et dårligt kriminalitetsprogram som CSI, ved du hvad jeg taler om:
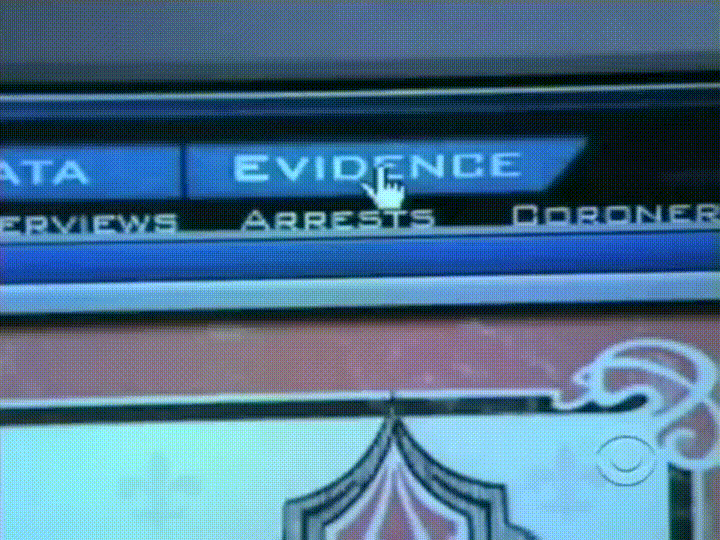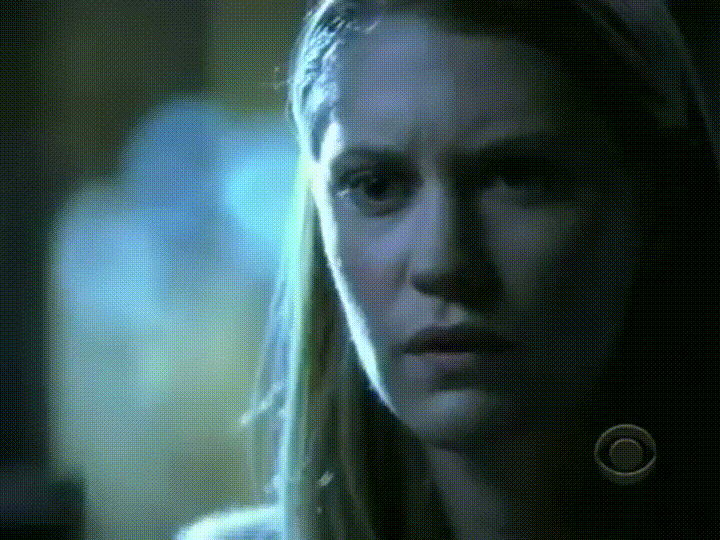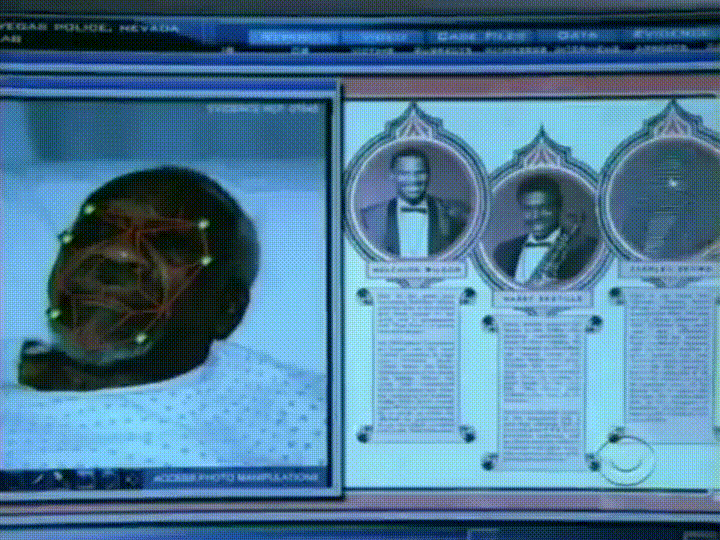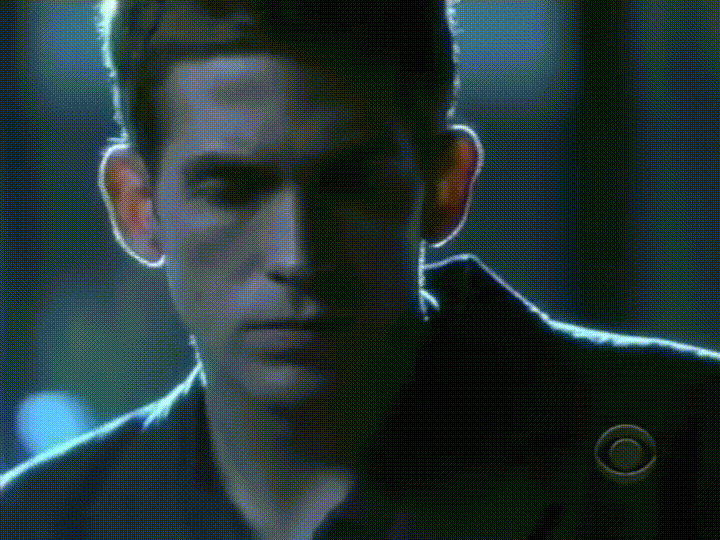
den mest pålidelige måde at måle et ansigt på
Ok, så hvilke målinger skal vi indsamle fra hvert ansigt for at opbygge vores kendte ansigtsdatabase? Øre størrelse? Næse længde? Øjenfarve? Noget andet?
det viser sig, at de målinger, der synes indlysende for os mennesker (som øjenfarve), ikke rigtig giver mening for en computer, der ser på individuelle billedpunkter i et billede. Forskere har opdaget, at den mest nøjagtige tilgang er at lade computeren finde ud af målingerne for at samle sig selv. Dyb læring gør et bedre stykke arbejde end mennesker med at finde ud af, hvilke dele af et ansigt der er vigtige at måle.
løsningen er at træne et dybt indviklet neuralt netværk (ligesom vi gjorde i Del 3). Men i stedet for at træne netværket til at genkende billedobjekter, som vi gjorde sidste gang, skal vi træne det til at generere 128 målinger for hvert ansigt.
træningsprocessen fungerer ved at se på 3 ansigtsbilleder ad gangen:
- indlæs et træningsansigtsbillede af en kendt person
- indlæs et andet billede af den samme kendte person
- indlæs et billede af en helt anden person
så ser algoritmen på de målinger, den i øjeblikket genererer for hvert af disse tre billeder. Det så tweaks det neurale netværk, der lidt, så at det gør, at de målinger, det genererer til #1 og #2 er lidt tættere på og samtidig sikre, at målinger til #2 og #3 er lidt længere fra hinanden:

Efter at gentage dette trin millioner af gange for millioner af billeder af tusindvis af forskellige mennesker, neurale netværk lærer til pålideligt at generere 128 målinger for hver person. Alle ti forskellige billeder af den samme person skal give omtrent de samme målinger.
Machine learning folk kalder de 128 målinger af hvert ansigt en indlejring. Ideen om at reducere komplicerede rådata som et billede til en liste over computergenererede tal kommer meget op i maskinindlæring (især i sprogoversættelse). Den nøjagtige tilgang til ansigter, vi bruger, blev opfundet i 2015 af forskere hos Google, men der findes mange lignende tilgange.
kodning af vores ansigtsbillede
denne proces med at træne et indviklet neuralt netværk til output ansigtsindlejringer kræver en masse data og computerkraft. Selv med et dyrt NVidia Telsa-videokort tager det cirka 24 timers kontinuerlig træning for at få god nøjagtighed.
men når netværket er blevet trænet, kan det generere målinger for ethvert ansigt, selv dem, det aldrig har set før! Så dette trin skal kun udføres en gang. Heldig for os gjorde de fine folk på openface allerede dette, og de offentliggjorde flere uddannede netværk, som vi direkte kan bruge. Tak Brandon Amos og team!
så alt, hvad vi skal gøre os selv, er at køre vores ansigtsbilleder gennem deres forududdannede netværk for at få de 128 målinger for hvert ansigt. Her er målingerne til vores testbillede:

så hvilke dele af ansigtet måler disse 128 tal nøjagtigt? Det viser sig, at vi ikke har nogen anelse. Det betyder ikke rigtig noget for os. Alt, hvad vi bryr os om, er, at netværket genererer næsten de samme tal, når man ser på to forskellige billeder af den samme person.
Hvis du selv vil prøve dette trin, giver OpenFace et lua-script, der genererer indlejringer af alle billeder i en mappe og skriver dem til en csv-fil. Du styrer det sådan her.
Trin 4: Find personens navn fra kodningen
dette sidste trin er faktisk det nemmeste trin i hele processen. Alt, hvad vi skal gøre, er at finde den person i vores database med kendte personer, der har de nærmeste målinger til vores testbillede.
Du kan gøre det ved hjælp af en hvilken som helst grundlæggende maskinindlæringsklassificeringsalgoritme. Ingen fancy dybe læringstricks er nødvendige. Vi bruger en simpel lineær SVM-klassifikator, men mange klassificeringsalgoritmer kunne fungere.
alt, hvad vi skal gøre, er at træne en klassifikator, der kan tage målingerne fra et nyt testbillede og fortæller, hvilken kendt person der er den nærmeste kamp. At køre denne klassifikator tager millisekunder. Resultatet af klassifikatoren er navnet på personen!
så lad os prøve vores system. Først trænede jeg en klassifikator med indlejringerne på omkring 20 billeder hver af vil Ferrell, Chad Smith og Jimmy Falon: