Hvad er regulært udtryk i Python?
et regulært udtryk (RE) i et programmeringssprog er en speciel tekststreng, der bruges til at beskrive et søgemønster. Det er yderst nyttigt til at udtrække oplysninger fra tekst som kode, filer, log, regneark eller endda dokumenter.
mens du bruger Python regulære udtryk den første ting er at genkende er, at alt er hovedsagelig et tegn, og vi skriver mønstre til at matche en bestemt sekvens af tegn også kaldet streng. Ascii eller latinske bogstaver er dem, der er på dine tastaturer, og Unicode bruges til at matche den fremmede tekst. Det omfatter cifre og tegnsætning og alle specialtegn som $#@!%, osv.
i denne Python Regeks tutorial, vil vi lære –
- Regulært udtryk syntaks
- eksempel på B+ og ^ udtryk
- eksempel på \S udtryk i re.opdel funktion
- ved hjælp af regulære udtryksmetoder
- ved hjælp af re.match ()
- find mønster i tekst (re.søg ())
- ved hjælp af re.Findall til tekst
- Python flag
- eksempel på re.M eller Multiline flag
for eksempel kunne et Python regulært udtryk fortælle et program at søge efter specifik tekst fra strengen og derefter udskrive resultatet i overensstemmelse hermed. Udtryk kan omfatte
- teksttilpasning
- gentagelse
- forgrening
- mønster-sammensætning osv.
Regulært udtryk eller Regeks i Python betegnes som RE (REs, regeks eller regeks mønster) importeres gennem re modul. Python understøtter regulært udtryk gennem biblioteker. Regeks i Python understøtter forskellige ting som modifikatorer, identifikatorer og hvide rum tegn.
| identifikatorer | modifikatorer | hvide mellemrum | Escape påkrævet |
|---|---|---|---|
| \d= ethvert tal (et ciffer) | \D repræsenterer et ciffer.Tidligere: \d{1,5} det vil erklære ciffer mellem 1,5 som 424,444,545 osv. | \n = ny linje | . + * ? $ ^ () {} | \ |
| \D= Alt andet end et tal (et ikke-cifret) | + = matcher 1 eller flere | \s= mellemrum | |
| \s = mellemrum (fane,mellemrum,ny linje osv.) | ? = matches 0 or 1 | \t =tab | |
| \S= anything but a space | * = 0 or more | \e = escape | |
| \w = letters ( Match alphanumeric character, including “_”) | $ match end of a string | \r = carriage return | |
| \W =anything but letters ( Matches a non-alphanumeric character excluding “_”) | ^ match start of a string | \f= form feed | |
| . = anything but letters (periods) | | matches either or x/y | —————– | |
| \b = any character except for new line | = range or “variance” | —————- | |
| \. | = denne mængde af foregående kode | —————– |
Regulært udtryk(re) syntaks
import re
- “re” modul inkluderet med Python primært brugt til streng søgning og manipulation
- bruges også ofte til hjemmeside “skrabning” (uddrag stort mængde data fra hjemmesider)
vi begynder ekspressionsvejledningen med denne enkle øvelse ved at bruge udtrykkene (B+) og (^).
eksempel på B + og ^ udtryk
- “^”: Dette udtryk matcher starten på en streng
- “v+”: dette udtryk matcher det alfanumeriske tegn i strengen
Her vil vi se et Python-Regekseksempel på, hvordan vi kan bruge V+ og ^ udtryk i vores kode. Vi dækker funktionen re.findall () i Python, senere i denne tutorial, men i et stykke tid fokuserer vi simpelthen på \H+ og \^ udtryk.
for eksempel for vores streng “guru99, uddannelse er sjovt”, hvis vi udfører koden med V+ og^, vil den give output”guru99″.
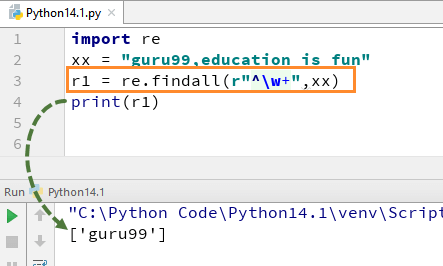
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print(r1)
husk, hvis du fjerner +tegn fra V+, ændres output, og det vil kun give det første tegn i det første bogstav, dvs.
eksempel på \S udtryk i re.split-funktion
- “s”: dette udtryk bruges til at oprette et mellemrum i strengen
for at forstå, hvordan denne Regeks i Python fungerer, begynder vi med et simpelt Python-Regekseksempel på en split-funktion. I eksemplet har vi delt hvert ord ved hjælp af ” re.split ” funktion og samtidig har vi brugt udtryk \s, der gør det muligt at parse hvert ord i strengen separat.

når du udfører denne kode, giver den dig output .
lad nu se, hvad der sker, hvis du fjerner “\” fra s. der er ikke noget ‘s’ Alfabet i output, det skyldes, at vi har fjernet ‘\’ fra strengen, og det evaluerer “s” som et almindeligt tegn og deler således ordene, uanset hvor det finder “s” i strengen.
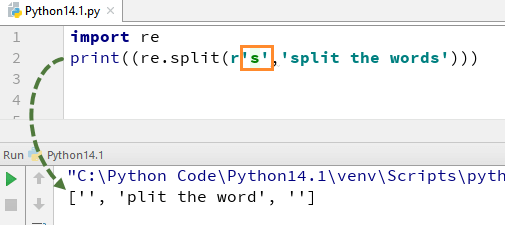
tilsvarende er der serier af andre Python regulære udtryk, som du kan bruge på forskellige måder i Python som \d,\d,$,\., \ b osv.
Her er den komplette kode
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print((re.split(r'\s','we are splitting the words')))print((re.split(r's','split the words')))
Dernæst vil vi se de typer metoder, der bruges med regulært udtryk i Python.
brug af regulære udtryksmetoder
“re” – pakken indeholder flere metoder til faktisk at udføre forespørgsler på en inputstreng. Vi vil se metoderne til re i Python:
- re.match ()
- re.søg ()
- re.findall ()
Bemærk: baseret på de regulære udtryk tilbyder Python to forskellige primitive operationer. Matchmetoden kontrollerer kun for en kamp i begyndelsen af strengen, mens søgning kontrollerer for en kamp hvor som helst i strengen.
re.match ()
re.match () funktion af re i Python vil søge regulære udtryk mønster og returnere den første forekomst. Metoden Python Regeks Match kontrollerer for en kamp kun i begyndelsen af strengen. Så hvis en kamp findes i den første linje, returnerer den matchobjektet. Men hvis der findes et match i en anden linje, returnerer funktionen Python-Regeks Match null.
overvej for eksempel følgende kode for Python re.match () funktion. Udtrykket “h+ “og” \H ” vil matche ordene, der begynder med bogstavet ‘g’, og derefter identificeres alt, hvad der ikke startes med ‘g’. For at kontrollere match for hvert element i listen eller strengen, vi kører forloop i denne Python re.match () eksempel.

re.Søg (): Find mønster i tekst
re.Søg () funktion vil søge regulære udtryk mønster og returnere den første forekomst. I modsætning til Python re.match (), det vil kontrollere alle linjer i inputstrengen. Python re.Søg () funktion returnerer et match objekt, når mønsteret er fundet og “null” hvis mønsteret ikke findes
for at bruge Søg() funktion, skal du importere Python re modul først og derefter udføre koden. Python re.Søg () funktion tager “mønster” og”tekst”til at scanne fra vores vigtigste streng
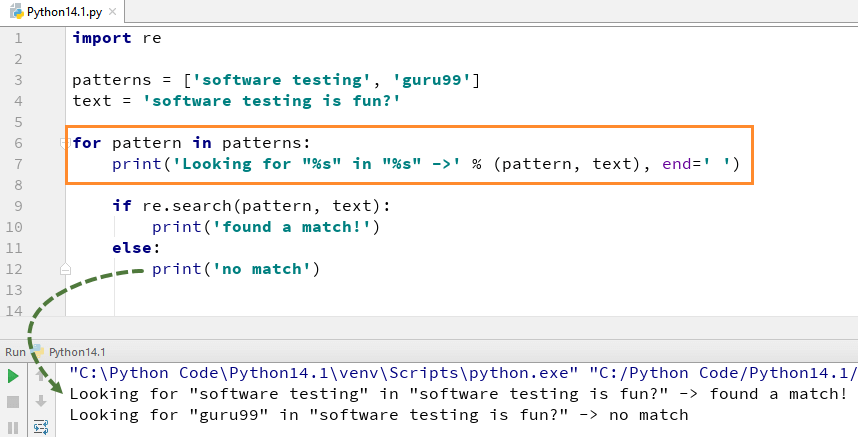
for eksempel her ser vi efter to bogstavelige strenge “programmel testing” “guru99”, i en tekststreng “programmel Testing is fun”. For “programmel test” fandt vi kampen dermed det returnerer output af Python re.søg () eksempel som” fundet et match”, mens vi for ordet” guru99 “ikke kunne findes i streng, hvorfor det returnerer output som”ingen match”.
re.findall ()
findall () modul bruges til at søge efter “alle” forekomster, der matcher et givet mønster. I modsætning hertil vil search () modul kun returnere den første forekomst, der matcher det angivne mønster. findall () vil gentage over alle linjer i filen og vil returnere alle ikke-overlappende matches af mønster i et enkelt trin.
for eksempel har vi her en liste over e-mail-adresser, og vi ønsker, at alle e-mail-adresser skal hentes fra listen, vi bruger metoden re.findall () i Python. Det vil finde alle de e-mail-adresser fra listen.
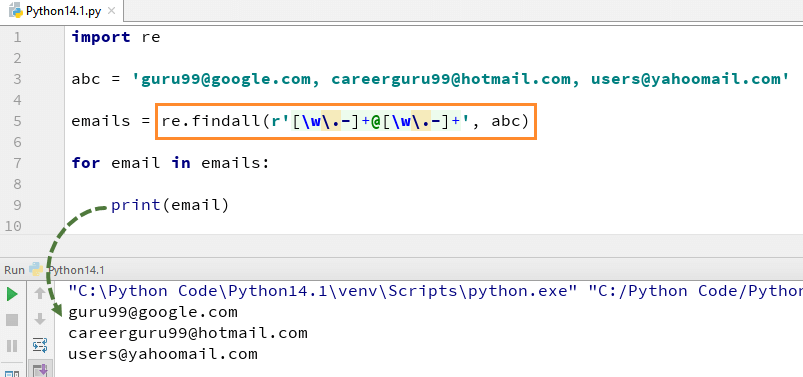
Her er den komplette kode for eksempel af re.findall ()
import relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print((z.groups())) patterns = text = 'software testing is fun?'for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!')else: print('no match')abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print(email)
Python Flags
mange Python Regeks metoder og Regeks funktioner tager et valgfrit argument kaldet flag. Dette flag kan ændre betydningen af den givne Python Regeks mønster. For at forstå disse vil vi se et eller to eksempler på disse Flag.
Various flags used in Python includes
| Syntax for Regex Flags | What does this flag do |
|---|---|
| Make begin/end consider each line | |
| It ignores case | |
| Make | |
| Make { \w,\W,\b,\B} follows Unicode rules | |
| Make {\w,\W,\b,\B} follow locale | |
| Allow comment in Regex |
Example of re.M eller Multiline flag
i multiline matcher mønstertegnet det første tegn i strengen og begyndelsen af hver linje (følger umiddelbart efter hver ny linje). Mens udtryk lille ” V ” bruges til at markere rummet med tegn. Når du kører koden, udskriver den første variabel “k1″ kun tegnet ” g ” for ord guru99, mens når du tilføjer flylinjeflag, henter den de første tegn af alle elementerne i strengen.
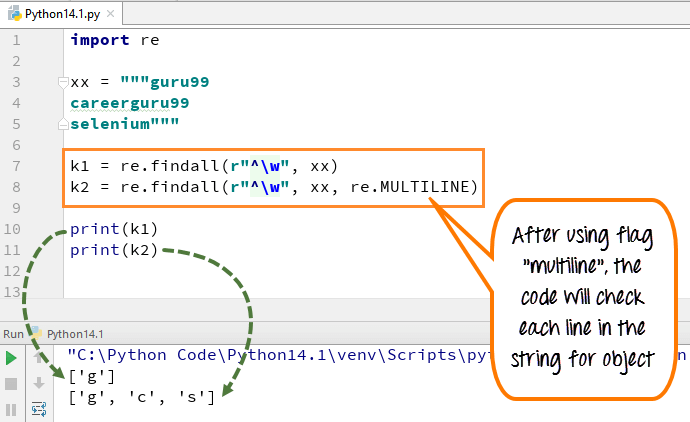
Her er koden
import rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print(k1)print(k2)
- vi erklærede Variablen for streng ” guru99…. careerguru99….selen “
- Kør koden uden at bruge flag multiline, det giver output kun ‘ g ‘fra linjerne
- Kør koden med flag “multiline”, når du udskriver’ k2 ‘giver det output som’ g’,’ c ‘og’ s ‘
- så forskellen Vi kan se efter og før du tilføjer flere linjer i ovenstående eksempel.
ligeledes kan du også bruge andre Python flag som re.U (Unicode), re.L (Følg locale), re.(Tillad kommentar) osv.
Python 2 eksempel
ovenstående koder er Python 3 eksempler, hvis du ønsker at køre i Python 2 kan du overveje følgende kode.
# Example of w+ and ^ Expressionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print r1# Example of \s expression in re.split functionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print (re.split(r'\s','we are splitting the words'))print (re.split(r's','split the words'))# Using re.findall for textimport relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print(z.groups()) patterns = text = 'software testing is fun?'for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!'else: print 'no match'abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print email# Example of re.M or Multiline Flagsimport rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print k1print k2
Resume
et regulært udtryk i et programmeringssprog er en speciel tekststreng, der bruges til at beskrive et søgemønster. Det omfatter cifre og tegnsætning og alle specialtegn som $#@!%, osv. Udtryk kan omfatte bogstavelig
- teksttilpasning
- gentagelse
- forgrening
- mønster-sammensætning osv.
i Python betegnes et regulært udtryk som RE (REs, regeks eller regeks mønster) er indlejret gennem Python re modul.
- “re” modul inkluderet med Python primært bruges til streng søgning og manipulation
- bruges også ofte til hjemmeside “skrabning” (uddrag stor mængde data fra hjemmesider)
- regulære udtryk metoder omfatter re.match (), re.søg ()& re.findall ()
- andre Python-regeksudskiftningsmetoder er sub() og subn (), som bruges til at erstatte matchende strenge i re
- Python-Flag mange Python-Regeks-metoder og Regeksfunktioner tager et valgfrit argument kaldet flag
- dette flag kan ændre betydningen af det givne Regeks mønster
- forskellige Python-flag, der bruges i Regeks-metoder, er re.M, re.Jeg, re.S osv.