
“der er tre typer løgne – løgne, forbandede løgne, falske statistikker, falske statistikker løgne og statistik.”- Benjamin Disraeli
statistiske analyser har historisk været en gæv af de højteknologiske og avancerede erhvervsindustrier, og i dag er de vigtigere end nogensinde. Med stigningen i avanceret teknologi og globaliserede operationer giver statistiske analyser virksomheder et indblik i at løse markedets ekstreme usikkerheder. Undersøgelser fremmer informeret beslutningstagning, sunde vurderinger og handlinger udført på vægten af beviser, ikke antagelser.
da virksomheder ofte er tvunget til at følge et vanskeligt at fortolke markedskort, kan statistiske metoder hjælpe med den planlægning, der er nødvendig for at navigere i et landskab fyldt med huller, faldgruber og fjendtlig konkurrence. Statistiske undersøgelser kan også hjælpe med markedsføring af varer eller tjenester og med at forstå de enkelte målmarkeder unikke værdidrivere. I den digitale tidsalder forbedres og udnyttes disse muligheder kun yderligere gennem implementering af avanceret teknologi og business intelligence-programmer. Hvis alt dette er sandt, hvad er problemet med statistik?
faktisk er der ikke noget problem i sig selv – men der kan være. Statistikker er berygtede for deres evne og potentiale til at eksistere som vildledende og dårlige data.
Hvad er en vildledende statistik?
vildledende statistik er simpelthen misusage – målrettet eller ej – af en numerisk data. Resultaterne giver en vildledende information til modtageren, som derefter mener noget galt, hvis han eller hun ikke bemærker fejlen eller ikke har det fulde databillede.
i betragtning af vigtigheden af data i dagens hurtigt udviklende digitale verden er det vigtigt at være fortrolig med det grundlæggende i vildledende statistik og tilsyn. Som en øvelse i due diligence vil vi gennemgå nogle af de mest almindelige former for misbrug af statistikker og forskellige alarmerende (og desværre almindelige) vildledende statistikeksempler fra det offentlige liv.
er statistikker pålidelige?
73.6% af statistikkerne er falske. Virkelig? Nej, det er selvfølgelig et sammensat nummer (selvom en sådan undersøgelse ville være interessant at vide-men igen kunne have alle de fejl, det forsøger på samme tid at påpege). Statistisk pålidelighed er afgørende for at sikre analysens præcision og gyldighed. For at sikre, at pålideligheden er høj, er der forskellige teknikker, der skal udføres – først af dem er kontroltestene, der skal have lignende resultater, når man reproducerer et eksperiment under lignende forhold. Disse kontrolforanstaltninger er vigtige og bør være en del af ethvert eksperiment eller undersøgelse – desværre er det ikke altid tilfældet.
mens tal ikke lyver, kan de faktisk bruges til at vildlede med halve sandheder. Dette er kendt som ” misbrug af statistik.”Det antages ofte, at misbrug af statistikker er begrænset til de personer eller virksomheder, der søger at opnå fortjeneste ved at fordreje sandheden, det være sig økonomi, uddannelse eller massemedier.
imidlertid er fortællingen om halve sandheder gennem undersøgelse ikke kun begrænset til matematiske amatører. En undersøgelsesundersøgelse fra 2009 af Dr. Daniele Fanelli fra University of Edinburgh viste, at 33,7% af de undersøgte forskere indrømmede tvivlsom forskningspraksis, herunder ændring af resultater for at forbedre resultaterne, subjektiv datatolkning, tilbageholdelse af analytiske detaljer og droppe observationer på grund af tarmfølelser…. Forskere!
selvom tal ikke altid behøver at være fabrikeret eller vildledende, er det klart, at selv samfund mest betroede numeriske portvagter ikke er immune over for den uforsigtighed og bias, der kan opstå med statistiske fortolkningsprocesser. Der er forskellige måder, hvordan statistikker kan være vildledende, som vi vil detaljerede senere. Den mest almindelige er selvfølgelig korrelation versus årsagssammenhæng, der altid udelader en anden (eller to eller tre) faktor, der er den faktiske årsag til problemet. At drikke te øger diabetes med 50%, og skaldethed øger risikoen for hjerte-kar-sygdomme op til 70%! Glemte vi at nævne mængden af sukker, der blev lagt i teen, eller det faktum, at skaldethed og alderdom er relateret – ligesom hjerte-kar-sygdomsrisici og alderdom?
så kan statistik manipuleres? Det kan de. Lyver tal? Du kan være dommer.
hvordan statistikker kan være vildledende

husk, misbrug af statistikker kan være utilsigtet eller målrettet. Mens en ondsindet hensigt at sløre linjer med vildledende statistikker helt sikkert vil forstørre bias, hensigt er ikke nødvendig for at skabe misforståelser. Misbrug af statistikker er et meget bredere problem, der nu gennemsyrer gennem flere brancher og studieretninger. Her er et par potentielle uheld, der ofte fører til misbrug:
- defekt afstemning
den måde, hvorpå spørgsmål formuleres, kan have en enorm indflydelse på den måde, et publikum besvarer dem på. Specifikke formuleringsmønstre har en overbevisende effekt og får respondenterne til at svare på en forudsigelig måde. For eksempel på en afstemning, der søger skatteudtalelser, lad os se på de to potentielle spørgsmål:
– tror du, at du skal beskattes, så andre borgere ikke behøver at arbejde?- Tror du, at regeringen skal hjælpe de mennesker, der ikke kan finde arbejde?
disse to spørgsmål vil sandsynligvis fremkalde langt forskellige svar, selvom de beskæftiger sig med det samme emne for statsstøtte. Dette er eksempler på ” indlæste spørgsmål.”
en mere præcis måde at formulere spørgsmålet på ville være, ” støtter du regeringens bistandsprogrammer til arbejdsløshed?”eller, (endnu mere neutralt)” Hvad er dit synspunkt med hensyn til arbejdsløshedshjælp?”
de to sidstnævnte eksempler på de originale spørgsmål eliminerer enhver slutning eller forslag fra polleren og er således betydeligt mere upartiske. En anden uretfærdig metode til afstemning er at stille et spørgsmål, men forud for det med en betinget erklæring eller en kendsgerning. Opholder sig med vores eksempel, ville det se sådan ud: “i betragtning af de stigende omkostninger til middelklassen, støtter du Offentlige bistandsprogrammer?”
en god tommelfingerregel er altid at tage afstemning med et saltkorn og forsøge at gennemgå de spørgsmål, der faktisk blev præsenteret. De giver stor indsigt, ofte mere end svarene.
- fejlbehæftede korrelationer
problemet med korrelationer er dette: hvis du måler nok variabler, vil det til sidst se ud til, at nogle af dem korrelerer. Da en ud af tyve uundgåeligt vil blive betragtet som signifikant uden nogen direkte sammenhæng, kan undersøgelser manipuleres (med nok data) til at bevise en sammenhæng, der ikke eksisterer, eller som ikke er signifikant nok til at bevise årsagssammenhæng.
for at illustrere dette punkt yderligere, lad os antage, at en undersøgelse har fundet en sammenhæng mellem en stigning i bilulykker i staten Ny York i juni måned (A) og en stigning i bjørneangreb i staten Ny York i juni måned (B).
det betyder, at der sandsynligvis vil være seks mulige forklaringer:
– bilulykker (a) forårsager bjørneangreb (B)- Bjørneangreb (B) forårsager bilulykker (A) og bjørneangreb (B) forårsager delvist hinanden – bilulykker (A) og bjørneangreb (B) er forårsaget af en tredje faktor (C) – Bjørneangreb (B)) er forårsaget af en tredje faktor (C), der korrelerer med bilulykker (a) – korrelationen er kun chance
enhver fornuftig person ville let identificere det faktum, at bilulykker ikke forårsager Bjørneangreb. Hver er sandsynligvis et resultat af en tredje faktor, det vil sige: en øget befolkning på grund af den høje turistsæson i juni måned. Det ville være absurd at sige, at de forårsager hinanden… og det er netop derfor, det er vores eksempel. Det er let at se en sammenhæng.
men hvad med årsagssammenhæng? Hvad hvis de målte variabler var forskellige? Hvad hvis det var noget mere troværdigt, som alderdom og alderdom? Det er klart, at der er en sammenhæng mellem de to, men er der årsagssammenhæng? Mange ville fejlagtigt antage, Ja, udelukkende baseret på styrken af korrelationen. Træd forsigtigt, for enten bevidst eller uvidende, korrelationsjagt vil fortsat eksistere inden for statistiske undersøgelser.
- datafiskeri
dette vildledende dataeksempel kaldes også” datamudring ” (og relateret til fejlbehæftede korrelationer). Det er en data mining-teknik, hvor ekstremt store datamængder analyseres med det formål at opdage forhold mellem datapunkter. At søge et forhold mellem data er ikke et misbrug af data i sig selv, imidlertid, at gøre det uden en hypotese er.
datamudring er en selvbetjenende teknik, der ofte anvendes til det uetiske formål at omgå traditionelle data mining teknikker for at søge yderligere data konklusioner, der ikke eksisterer. Dette betyder ikke, at der ikke er nogen ordentlig brug af data mining, da det faktisk kan føre til overraskende outliers og interessante analyser. Imidlertid, oftere end ikke, datamudring bruges til at antage eksistensen af datarelationer uden yderligere undersøgelse.
ofte resulterer datafiskeri i undersøgelser, der er meget publiceret på grund af deres vigtige eller outlandish fund. Disse undersøgelser modsiges meget snart af andre vigtige eller outlandish fund. Disse falske korrelationer forlader ofte offentligheden meget forvirret og søger efter svar vedrørende betydningen af årsagssammenhæng og korrelation.
ligeledes er en anden almindelig praksis med data udeladelsen, hvilket betyder, at efter at have set på et stort datasæt med svar, vælger du kun dem, der understøtter dine synspunkter og fund, og udelader dem, der modsiger det. Som nævnt i begyndelsen af denne artikel har det vist sig, at en tredjedel af forskerne indrømmede, at de havde tvivlsom forskningspraksis, herunder tilbageholdelse af analytiske detaljer og ændring af resultater…! Men så igen står vi over for en undersøgelse, der i sig selv kunne falde ind i disse 33% af tvivlsom praksis, defekt afstemning, selektiv bias… Det bliver svært at tro på nogen analyse!
- vildledende datavisualisering
indsigtsfulde grafer og diagrammer inkluderer meget grundlæggende, men væsentlige, gruppering af elementer. Uanset hvilke typer datavisualisering du vælger at bruge, skal den formidle:
– de anvendte skalaer – startværdien (nul eller på anden måde)- beregningsmetoden (f.eks. datasæt og tidsperiode)
fraværende disse elementer skal visuelle datarepræsentationer ses med et saltkorn under hensyntagen til de almindelige datavisualiseringsfejl, man kan lave. Mellemliggende datapunkter bør også identificeres og kontekst angives, hvis det vil tilføre værdi til de fremlagte oplysninger. Med den stigende afhængighed af intelligent løsningsautomatisering til sammenligninger af variable datapunkter bør bedste praksis (dvs.design og skalering) implementeres inden sammenligning af data fra forskellige kilder, datasæt, tidspunkter og placeringer.
- målrettet og selektiv bias
det sidste af vores mest almindelige eksempler på misbrug af statistikker og vildledende data er måske den mest alvorlige. Målrettet bias er det bevidste forsøg på at påvirke datafund uden selv at fejle professionel ansvarlighed. Bias er mest sandsynligt at tage form af data udeladelser eller justeringer.
den selektive bias er lidt mere diskret for hvem læser ikke de små linjer. Det falder normalt ned på prøven af de undersøgte personer. For eksempel, arten af den undersøgte gruppe: at spørge en klasse universitetsstuderende om den lovlige drikkealder, eller en gruppe pensionister om ældreplejesystemet. Du ender med en statistisk fejl kaldet “selektiv bias”.
- brug af procentvis ændring i kombination med en lille stikprøvestørrelse
en anden måde at skabe vildledende statistik på, også forbundet med valget af prøve diskuteret ovenfor, er størrelsen af prøven. Når et eksperiment eller en undersøgelse ledes på en fuldstændig ikke signifikant stikprøvestørrelse, vil resultaterne ikke kun være ubrugelige, men måden at præsentere dem på – nemlig som procentdele – vil være fuldstændig vildledende.
at stille et spørgsmål til en stikprøvestørrelse på 20 personer, hvor 19 svarer “ja” (=95% siger ja) versus at stille det samme spørgsmål til 1.000 mennesker og 950 svarer “ja” (=95% også): gyldigheden af procentdelen er helt klart ikke den samme. At give udelukkende procentdelen af ændringer uden det samlede antal eller stikprøvestørrelse vil være fuldstændig vildledende. hkdc ‘s tegneserie illustrerer dette meget godt for at vise, hvordan den” hurtigst voksende ” påstand er en helt relativ marketing tale:

ligeledes påvirkes den nødvendige stikprøvestørrelse af den slags spørgsmål, du stiller, den statistiske signifikans, du har brug for (klinisk undersøgelse vs forretningsundersøgelse) og den statistiske teknik. Hvis du udfører en kvantitativ analyse, er prøvestørrelser under 200 personer normalt ugyldige.
vildledende Statistikeksempler i det virkelige liv
nu hvor vi har gennemgået flere af de mest almindelige metoder til misbrug af data, lad os se på forskellige digitale alderseksempler på vildledende statistik på tværs af tre forskellige, men relaterede spektre: medier og politik, reklame og videnskab. Mens visse emner, der er anført her, sandsynligvis vil vække følelser afhængigt af ens synspunkt, er deres optagelse kun til datademonstrationsformål.
- eksempler på vildledende statistik i medierne og politik
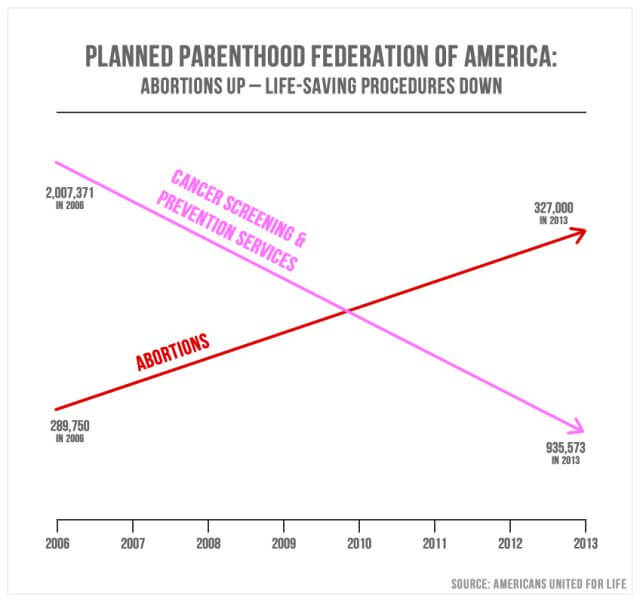
vildledende statistikker i medierne er ret almindelige. Den Sept. 29, 2015, spurgte republikanere fra den amerikanske Kongres Cecile Richards, præsidenten for Planned Parenthood, om misbrug af $500 millioner i årlig føderal finansiering. Ovenstående graf / diagram blev præsenteret som et vægtpunkt.
repræsentant Jason Chaffetts fra Utah forklarede: “i pink er det reduktionen i brysteksamenerne, og den røde er stigningen i aborterne. Det er det, der sker i din organisation.”
baseret på diagrammets struktur ser det faktisk ud til at vise, at antallet af aborter siden 2006 oplevede en betydelig vækst, mens antallet af kræftscreeninger faldt væsentligt. Hensigten er at formidle et skift i fokus fra kræftundersøgelser til abort. Diagrampunkterne ser ud til at indikere, at 327.000 aborter er større i iboende værdi end 935.573 kræftundersøgelser. Endnu, nærmere undersøgelse vil afsløre, at diagrammet ikke har nogen defineret y-akse. Dette betyder, at der ikke er nogen definerbar begrundelse for placeringen af de synlige målelinjer.
Politifact, en fact checking advocacy hjemmeside, gennemgik Rep. Ved hjælp af en klart defineret skala er her, hvordan informationen ser ud:

og som dette med en anden gyldig skala:
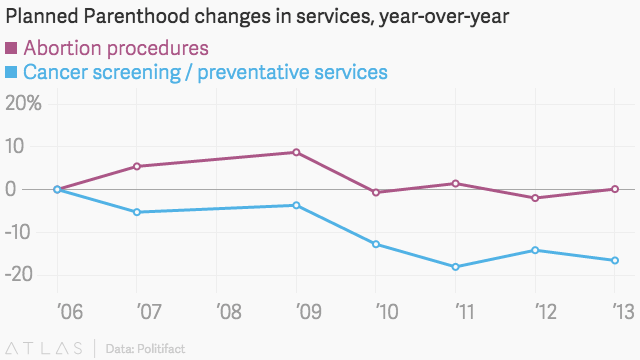
når det er placeret inden for en klart defineret skala, bliver det tydeligt, at mens antallet af kræftscreeninger faktisk er faldet, overstiger det stadig langt antallet af abortprocedurer, der udføres årligt. Som sådan er dette et godt vildledende statistikeksempel, og nogle kunne argumentere for bias i betragtning af at diagrammet ikke stammer fra kongresmedlemmet, men fra amerikanerne United For Life, en gruppe mod abort. Dette er blot et af mange eksempler på vildledende statistikker i medierne og politik.
- vildledende statistik i reklame

i 2007 blev Colgate bestilt af Advertising Standards Authority (ASA) i Storbritannien for at opgive deres påstand: “mere end 80% af tandlægerne anbefaler Colgate.”Det pågældende slogan var placeret på et reklametavle i Storbritannien og blev anset for at være i strid med Britiske reklameregler.
påstanden, der var baseret på undersøgelser af tandlæger og hygiejnister udført af producenten, viste sig at være forkert repræsentativ, da det gjorde det muligt for deltagerne at vælge et eller flere tandpastamærker. ASA erklærede, at påstanden “… ville forstås af læserne at betyde, at 80 procent af tandlægerne anbefaler Colgate ud over andre mærker, og de resterende 20 procent vil anbefale forskellige mærker.”
ASA fortsatte, ” fordi vi forstod, at en anden konkurrents brand blev anbefalet næsten lige så meget som Colgate-mærket af de undersøgte tandlæger, konkluderede vi, at påstanden vildledende antydede 80 procent af tandlæger anbefaler Colgate tandpasta frem for alle andre mærker.”ASA hævdede også, at de scripts, der blev brugt til undersøgelsen, informerede deltagerne om, at forskningen blev udført af et uafhængigt forskningsfirma, som i sagens natur var falsk.
baseret på de misbrugsteknikker, vi dækkede, er det sikkert at sige, at denne dårlige off-hand-teknik fra Colgate er et klart eksempel på vildledende statistik i reklame og ville falde under defekt afstemning og direkte bias.
- vildledende statistik inden for videnskab
ligesom abort er global opvarmning et andet politisk ladet emne, der sandsynligvis vil vække følelser. Det sker også for at være et emne, der er kraftigt godkendt af både modstandere og fortalere via undersøgelser. Lad os se på nogle af beviserne for og imod.
det er generelt aftalt, at den globale gennemsnitstemperatur i 1998 var 58,3 grader Fahrenheit. Dette er ifølge NASA ‘ s Goddard Institute for Space Studies. I 2012 blev den globale gennemsnitstemperatur målt til 58,2 grader. Det hævdes derfor af modstandere af global opvarmning, at da der var et 0,1 graders fald i den globale gennemsnitstemperatur over en 14-årig periode, afvises den globale opvarmning.
nedenstående graf er den, der oftest henvises til for at modbevise den globale opvarmning. Det demonstrerer ændringen i lufttemperatur (Celsius) fra 1998 til 2012.
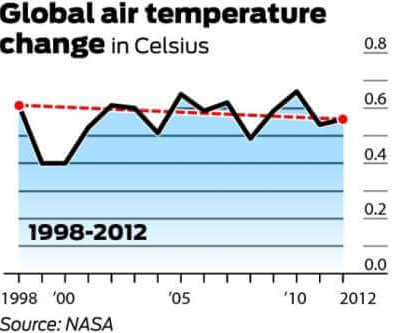
det er værd at nævne, at 1998 var et af de hotteste år på rekord på grund af en unormalt stærk el ni-vindstrøm. Det er også værd at bemærke, at da der er en stor grad af variation i klimasystemet, måles temperaturer typisk med mindst en 30-årig cyklus. Nedenstående diagram udtrykker den 30-årige ændring i globale gennemsnitstemperaturer.
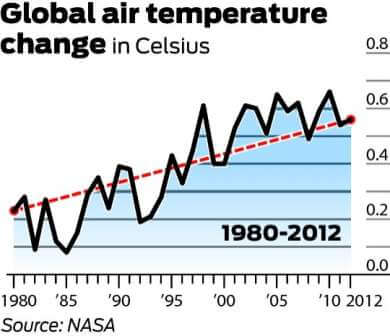
og nu se på tendensen fra 1900 til 2012: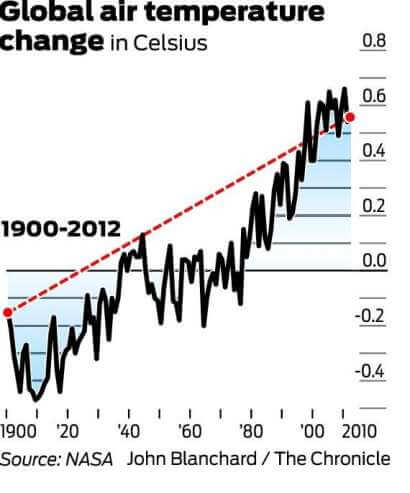
mens de langsigtede data kan synes at afspejle et plateau, maler det klart et billede af gradvis opvarmning. Derfor, ved hjælp af den første graf, og kun den første Graf, at modbevise den globale opvarmning er en perfekt vildledende statistik eksempel.
Sådan læses statistik med Afstand
en første god ting ville naturligvis være at stå foran en ærlig undersøgelse/eksperiment/forskning – vælg den, du har under dine øjne–, der har anvendt de korrekte teknikker til indsamling og fortolkning af data. Men du kan ikke vide, før du stiller dig selv et par spørgsmål og analyserer de resultater, du har mellem dine hænder.
som iværksætter og tidligere konsulent Mark Suster rådgiver i en artikel, bør du undre dig over, hvem der gjorde den primære forskning i analysen. Uafhængig universitetsstudiegruppe, lab-tilknyttet forskerteam, konsulentfirma? Derfra stammer naturligvis spørgsmålet: hvem betalte dem? Da ingen arbejder gratis, er det altid interessant at vide, hvem der sponsorerer forskningen. Ligeledes, hvad er motiverne bag forskningen? Hvad forsøgte forskeren eller statistikerne at finde ud af? Endelig, hvor stor var prøvesættet, og hvem var en del af det? Hvor inkluderende var det?
dette er vigtige spørgsmål at overveje og besvare, før de spredes overalt skæve eller partiske resultater – selvom det sker hele tiden på grund af forstærkning. Et typisk eksempel på forstærkning sker ofte med aviser og journalister, der tager et stykke data og har brug for at gøre det til overskrifter – således ofte ud af dets oprindelige kontekst. Ingen køber et magasin, hvor det hedder, at næste år vil det samme ske på det danske marked som i år – selvom det er sandt. Redaktører, klienter og folk vil have noget nyt, ikke noget de ved; derfor ender vi ofte med et forstærkningsfænomen, der bliver gentaget og mere end det burde.
misbrug af statistik-En oversigt
til spørgsmålet ” Kan statistik manipuleres?”, vi kan adressere 6 metoder, der ofte bruges-med vilje eller ej – der skæver analysen og resultaterne. Her er almindelige typer misbrug af statistikker:
- defekt polling
- fejlbehæftede korrelationer
- Datafiskeri
- vildledende datavisualisering
- målrettet og selektiv bias
- brug af procentvis ændring i kombination med en lille prøvestørrelse
nu hvor du kender dem, vil det være lettere at få øje på dem og stille spørgsmålstegn ved alle de statistikker, der gives til dig hver dag. For at sikre, at du holder en vis afstand til de undersøgelser og undersøgelser, du læser, skal du huske de spørgsmål, du skal stille dig selv – hvem der undersøgte og hvorfor, hvem der betalte for det, hvad var prøven.
gennemsigtighed og datadrevne forretningsløsninger
selvom det er helt klart, at statistiske data har potentialet til at blive misbrugt, kan det også etisk drive markedsværdien i den digitale verden. Big data har evnen til at give virksomheder i den digitale tidsalder en køreplan for effektivitet og gennemsigtighed og til sidst rentabilitet. Avancerede teknologiløsninger som online rapporteringsprogrammer kan forbedre statistiske datamodeller og give virksomheder i den digitale tidsalder et skridt op på deres konkurrence.
uanset om det drejer sig om markedsinformation, kundeoplevelse eller forretningsrapportering, er fremtiden for data Nu. Pas på at anvende data ansvarligt, etisk og visuelt, og se din gennemsigtige virksomhedsidentitet vokse.