arcfelismerés-lépésről lépésre
kezeljük ezt a problémát lépésről lépésre. Minden lépésnél megismerünk egy másik gépi tanulási algoritmust. Nem fogok minden egyes algoritmust teljesen megmagyarázni, hogy ez ne váljon könyvvé, de megtanulod a fő ötleteket mindegyik mögött, és megtanulod, hogyan lehet saját arcfelismerő rendszert építeni Pythonban az OpenFace és a dlib használatával.
1. lépés: Az összes Arc megtalálása
a folyamat első lépése az arcfelismerés. Nyilvánvalóan meg kell találnunk az arcokat egy fényképen, mielőtt megpróbálnánk megkülönböztetni őket!
Ha az elmúlt 10 évben bármilyen kamerát használt, akkor valószínűleg látta az arcfelismerést működés közben:

az arcfelismerés nagyszerű funkció a kamerák számára. Amikor a fényképezőgép automatikusan ki tudja választani az arcokat, a kép elkészítése előtt ellenőrizheti, hogy az összes arc fókuszban van-e. De más célra fogjuk használni — megtalálni a kép azon területeit, amelyeket át akarunk adni a csővezeték következő lépésének.
az arcfelismerés a 2000-es évek elején terjedt el, amikor Paul Viola és Michael Jones feltalálta az arcok észlelésének olyan módját, amely elég gyors volt ahhoz, hogy olcsó kamerákkal fusson. Most azonban sokkal megbízhatóbb megoldások léteznek. Egy 2005 — ben feltalált módszert fogunk használni, az úgynevezett orientált gradiensek Hisztogramja-vagy röviden csak HOG.
ahhoz, hogy arcokat találjunk egy képen, először fekete-fehérré tesszük a képünket, mert nincs szükségünk színes adatokra az arcok megtalálásához:

ezután egyenként nézzük meg a kép minden egyes pixelét. Minden egyes Pixelhez meg akarjuk nézni azokat a pixeleket, amelyek közvetlenül körülveszik:

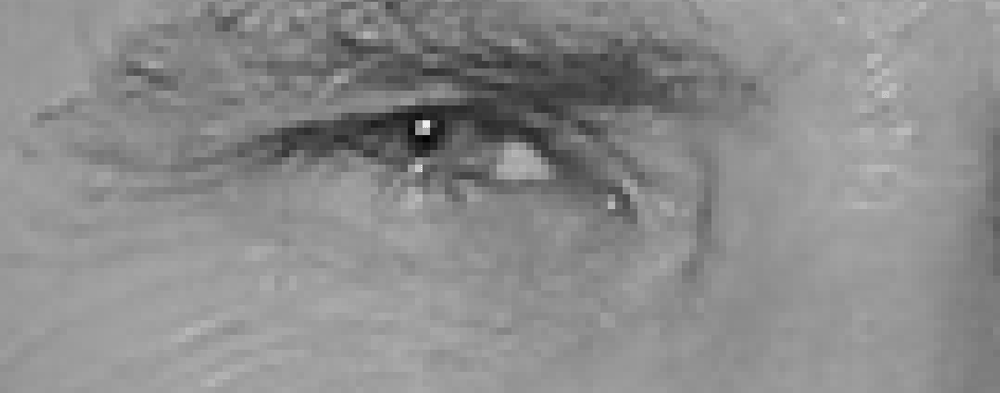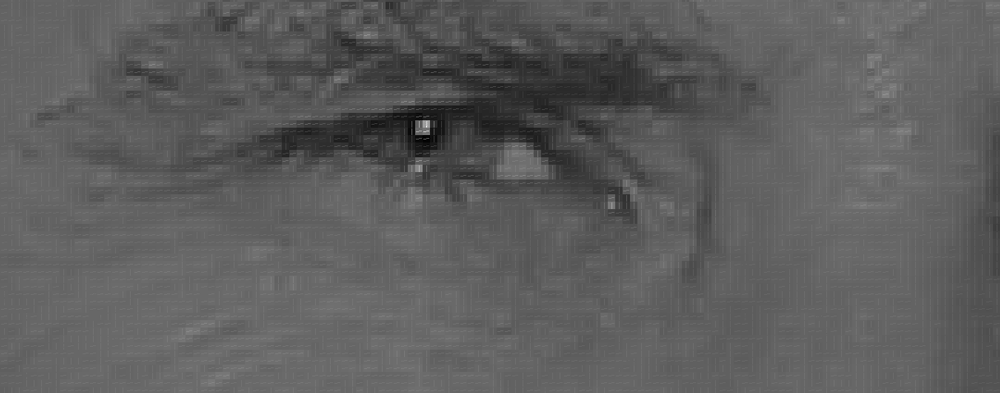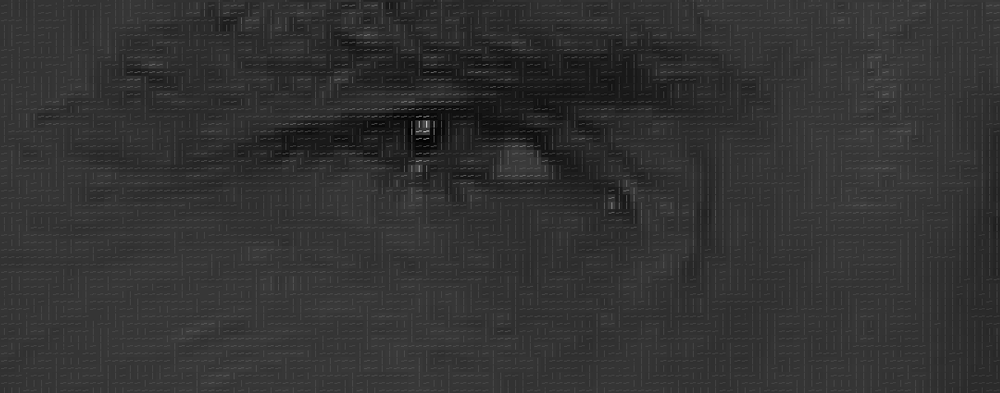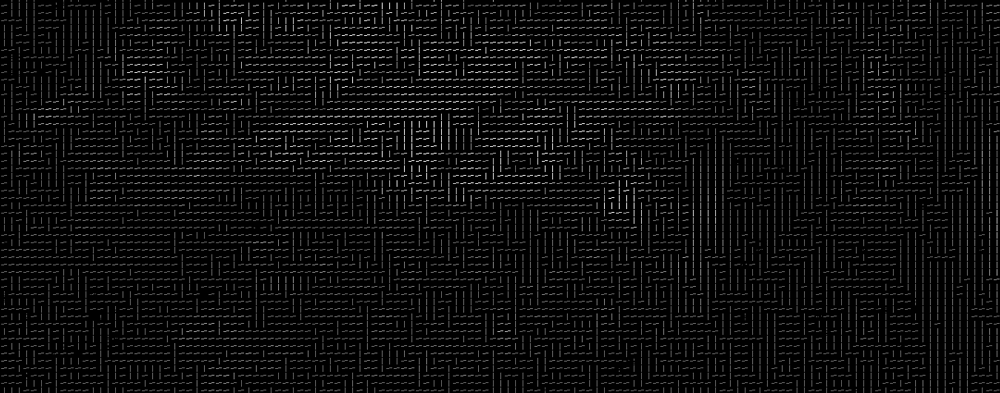
célunk, hogy kitaláljuk, mennyire sötét az aktuális pixel a közvetlenül körülvevő pixelekhez képest. Ezután egy nyilat akarunk rajzolni, amely megmutatja, hogy a kép melyik irányba sötétedik:

ha csak ezt az egy pixelt és a hozzáérő pixeleket nézzük, a kép egyre sötétebb felé a jobb felső.
ha megismétli ezt a folyamatot a kép minden egyes pixelére, akkor minden pixelt egy nyíl vált ki. Ezeket a nyilakat gradienseknek nevezzük, amelyek a fénytől a sötétig terjedő áramlást mutatják az egész képen:
Ez véletlenszerű dolognak tűnhet, de nagyon jó ok van arra, hogy a képpontokat színátmenetekkel helyettesítsük. Ha közvetlenül elemezzük a pixeleket, akkor az ugyanazon személy nagyon sötét és nagyon világos képeinek teljesen eltérő pixelértékei lesznek. De ha csak a fényerő változásának irányát vesszük figyelembe, mind az igazán sötét, mind az igazán fényes képek ugyanazt a pontos ábrázolást kapják. Ez sokkal könnyebben megoldja a problémát!
de a gradiens mentése minden egyes Pixelhez túl sok részletet ad nekünk. A végén hiányzik az erdő a fák miatt. Jobb lenne, ha csak egy magasabb szinten látnánk a világosság/sötétség alapvető áramlását, hogy láthassuk a kép alapvető mintáját.
ehhez a képet 16×16 képpontos kis négyzetekre bontjuk. Minden négyzetben megszámoljuk, hogy hány gradiens mutat az egyes fő irányokban(hány pont felfelé, pont felfelé-jobbra, pont jobbra stb.). Ezután a képen ezt a négyzetet a legerősebb nyíl irányokkal helyettesítjük.
a végeredmény az, hogy az eredeti képet egy nagyon egyszerű ábrázolássá alakítjuk, amely egyszerű módon rögzíti az arc alapvető szerkezetét:

ahhoz, hogy arcokat találjunk ebben a DISZNÓKÉPBEN, csak annyit kell tennünk, hogy megtaláljuk a képünk azon részét, amely a legjobban hasonlít egy ismert DISZNÓMINTÁHOZ, amelyet egy csomó más edzési arcból vontak ki:

ezzel a technikával most könnyen megtalálhatjuk az arcokat bármilyen képen:

ha ki akarod próbálni ezt a lépést a python és a dlib használatával, itt van a kód, amely megmutatja, hogyan lehet létrehozni és megtekinteni a képek hog reprezentációit.
2. lépés: arcok pózolása és kivetítése
Huh, elkülönítettük az arcokat a képünkön. De most meg kell foglalkozni a problémával, hogy arcok fordult különböző irányokba néz teljesen más, mint a számítógép:
ennek érdekében minden képet megpróbálunk úgy hajlítani, hogy a szemek és az ajkak mindig a kép mintahelyén legyenek. Ez sokkal könnyebbé teszi számunkra az arcok összehasonlítását a következő lépésekben.
ehhez egy face landmark becslés nevű algoritmust fogunk használni. Ennek sokféle módja van, de azt a megközelítést fogjuk használni, amelyet 2014-ben Vahid Kazemi és Josephine Sullivan talált ki.
Az alapötlet az, hogy 68 konkrét pontot (úgynevezett tereptárgyakat) fogunk felállítani, amelyek minden arcon léteznek — az áll teteje, az egyes szemek külső széle, az egyes szemöldök belső széle stb. Ezután kiképezünk egy gépi tanulási algoritmust, hogy képes legyen megtalálni ezeket a 68 konkrét pontot bármely arcon:

a 68 tereptárgy, amelyet minden arcon megtalálunk. Ezt a képet Brandon Amos, a CMU készítette, aki az OpenFace-en dolgozik.
itt van az eredmény a helyüket a 68 arc tereptárgyak a teszt kép: