BasicsEdit
első, néhány szókincs:
| aktiválás | = állapot a neuron értéke. A bináris neuronok esetében ez általában 0 / 1 vagy +1 / -1. |
| CAM | = tartalom címezhető memória. Memória visszahívása részleges mintával a memóriacím helyett. |
| konvergencia | = egy aktivációs minta stabilizálása a hálózaton. Az SL-ben a konvergencia a súlyok stabilizálását jelenti & torzítások, nem pedig aktiválások. |
| diszkriminatív | = felismerési feladatokkal kapcsolatos. Más néven elemzés (ban ben Mintaelmélet), vagy következtetés. |
| energia | = a hálózat aktiválási mintázatát leíró makroszkopikus mennyiség. (lásd alább) |
| általánosítás | = pontosan viselkedik a korábban nem tapasztalt bemeneteken |
| generatív | = gép által elképzelt és visszahívott feladat. néha szintézis (a Mintaelméletben), mimika vagy mély hamisítványok. |
| következtetés | = a” Futtatás ” fázis (szemben a képzéssel). A következtetés során a hálózat elvégzi azt a feladatot, amelyre kiképezték—vagy felismerve egy mintát (SL), vagy létrehozva egyet (UL). A következtetés általában egy energiafunkció gradiensét ereszkedik le. Az SL-vel ellentétben a gradiens ereszkedés edzés közben történik, nem következtetés. |
| gépi látás | = gépi tanulás a képeken. |
| NLP | = természetes nyelvi feldolgozás. Az emberi nyelvek gépi tanulása. |
| minta | = olyan hálózati aktivációk, amelyek bizonyos értelemben belső sorrenddel rendelkeznek, vagy amelyek tömörebben leírhatók az aktiválások jellemzőivel. Például a nulla pixelmintája, függetlenül attól, hogy adatként adják-e meg, vagy a hálózat képzeli-e el, rendelkezik egy olyan funkcióval, amely egyetlen hurokként leírható. A funkciókat a rejtett neuronok kódolják. |
| képzés | = a tanulási fázis. Itt a hálózat beállítja a súlyokat & torzítások tanulni a bemenetek. |
feladatok

az UL módszerek általában generatív feladatokra készítenek hálózatot, nem pedig felismerésre, de a feladatok felügyeltként történő csoportosítása homályos lehet. Például a kézírás-felismerés az 1980-as években SL néven indult. Aztán 2007-ben az UL-t használják az SL hálózatának alapozására. Jelenleg SL visszanyerte pozícióját, mint a jobb módszer.
képzés
a tanulási szakaszban egy felügyelet nélküli hálózat megpróbálja utánozni a megadott adatokat, és a mimikált kimenet hibáját használja a kijavításhoz (pl. súlya & torzítások). Ez hasonlít a gyermekek mimikri viselkedésére, amikor nyelvet tanulnak. Néha a hibát alacsony valószínűséggel fejezik ki, hogy a hibás kimenet bekövetkezik, vagy instabil nagy energiájú állapotként fejezhető ki a hálózatban.
energia
az energiafunkció a hálózat állapotának makroszkopikus mértéke. Ezt a fizikával való analógiát Ludwig Boltzmann egy gáz makroszkopikus energiájának elemzése ihlette, amely a részecskemozgás mikroszkopikus valószínűségeiből származik p .. .. {\displaystyle \ propto }

eE/kT, ahol k a Boltzmann-állandó és T a hőmérséklet. Az RBM hálózatban a reláció p = e-E / Z, ahol p & e minden lehetséges aktiválási mintában változik, és Z = A L L P A t T E r n s {\displaystyle \sum _{AllPatterns}}

E-E(minta). Pontosabban, p(A) = e-E(a) / Z, ahol a az összes idegsejt aktivációs mintája (látható és rejtett). Ezért a korai neurális hálózatok a Boltzmann-gép nevet viselik. Paul Smolensky hívja-e a harmóniát. A hálózat alacsony energiát keres, ami magas harmónia.
hálózatok
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
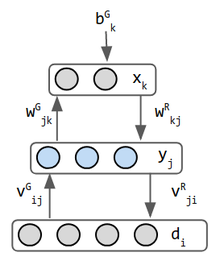 |
 autoencoder
|
 variációs autoencoder
|
Boltzmann és Helmholtz megelőzték a neurális hálózatok formuláit, de ezek a hálózatok az elemzéseikből kölcsönöztek, így ezek a hálózatok viselik a nevüket. Hopfield azonban közvetlenül hozzájárult UL.
IntermediateEdit
itt a p(x) és q(x) eloszlások rövidítése p és q lesz.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Leginkább az SL-ben használják, de itt említést érdemel. |
| 1982 | Ising variáns Hopfield net le, mint bütykök és osztályozók John Hopfield. |
| 1983 | Ising variáns Boltzmann gép valószínűségi neuronok által leírt Hinton & Sejnowski következő Sherington & Kirkpatrick ‘ s 1975 munka. |
| 1986 | Paul Smolensky közzéteszi a Harmóniaelméletet, amely egy RBM gyakorlatilag ugyanazzal a Boltzmann energiafunkcióval. Smolensky nem adott gyakorlati képzési rendszert. Hinton a 2000-es évek közepén |
| 1995 | Schmidthuber bemutatja az LSTM neuront a nyelvek számára. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| valószínűség | |
| CDF | = kumulatív eloszlási függvény. a PDF integrálja. A 3 közelébe jutás valószínűsége a görbe alatti terület 2,9 és 3,1 között. |
| kontrasztív divergencia | = olyan tanulási módszer, ahol az ember csökkenti az energiát a képzési mintákon, és növeli az energiát a nem kívánt mintákon a képzési készleten kívül. Ez nagyon különbözik a KL-divergenciától, de hasonló megfogalmazással rendelkezik. |
| várható érték | = e(x) = ++ x {\displaystyle \sum _{x}}
 x * p(x). Ez az átlagos érték vagy az átlagos érték. Folyamatos x bemenet esetén cserélje ki az összegzést egy integrálra. |
| látens változó | = nem megfigyelt mennyiség, amely segít megmagyarázni a megfigyelt adatokat. például egy influenzafertőzés (észrevétlen) megmagyarázhatja, hogy az ember miért tüsszent (megfigyelt). Ban ben valószínűségi neurális hálózatok, a rejtett neuronok látens változóként működnek, bár látens értelmezésük nem kifejezetten ismert. |
| = valószínűségi sűrűségfüggvény. Annak a valószínűsége, hogy egy véletlen változó vesz egy bizonyos értéket. Folyamatos pdf esetén a p(3) = 1/2 még mindig azt jelentheti, hogy közel nulla esély van a 3 pontos értékének elérésére. Ezt racionalizáljuk a cdf-el. | |
| sztochasztikus | = egy jól leírt valószínűségi sűrűségi képlet szerint viselkedik. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Ez a legnagyobb reverzibilis munka, amelyet egy hőrendszer végezhet állandó hőmérsékleten és nyomáson. szabad energia G = hő-hőmérséklet * entrópia |
| információ | = az üzenet információmennyisége x = -log p(x) |
| KLD | = relatív entrópia. Valószínűségi hálózatok esetén ez a bemenet közötti hiba analógja & utánzott kimenet. A Kullback-Liebler divergencia (KLD) az entrópia eltérését méri 1 Eloszlás egy másik eloszlástól. KLD (p, q)=\\displaystyle\sum _{x}}
p * log( p / q). Jellemzően p tükrözi a bemeneti adatokat, q tükrözi a hálózat értelmezését, a KLD pedig a kettő közötti különbséget. |
hálózatok összehasonlítása
| Hopfield | Boltzmann | RBM | Helmholtz | autoencoder | Vae | |
|---|---|---|---|---|---|---|
| használat & figyelemre méltó | cam, utazó eladó probléma | cam. A kapcsolatok szabadsága megnehezíti a hálózat elemzését. | mintafelismerés (MNIST, beszédfelismerés) | képzelet, mimika | nyelv: kreatív írás, fordítás. Vision: a homályos képek javítása | reális adatokat generál |
| neuron | determinisztikus bináris állapot. Aktiválás = { 0 (vagy -1) Ha x negatív, 1 egyébként } | sztochasztikus bináris Hopfield neuron | sztochasztikus bináris. Kiterjesztett valós értékű közepén 2000-es | bináris, sigmoid | nyelv: LSTM. látomás: helyi befogadó mezők. általában valódi értékes relu aktiválás. | |
| kapcsolatok | 1 réteg szimmetrikus súlyokkal. Nincs önkapcsolat. | 2 rétegű. 1-rejtett & 1-látható. szimmetrikus súlyok. | 2 rétegű. szimmetrikus súlyok. nincs oldalirányú kapcsolat egy rétegen belül. | 3 réteg: aszimmetrikus súlyok. 2 hálózatok egyesítve 1. | 3 rétegű. A bemenet akkor is rétegnek tekinthető, ha nincs bejövő súlya. visszatérő rétegek az NLP számára. feedforward konvolúciók a látáshoz. bemenet & A kimenet azonos neuronszámmal rendelkezik. | 3 rétegű: bemenet, kódoló, elosztó mintavevő dekóder. a mintavevő nem tekinthető rétegnek (e) |
| következtetés & energia | az energiát Gibbs valószínűségi mértéke adja meg : E = − 1 2 db i , j w i j i s i s j + i b i b i s i {\displaystyle e=-{\frac {1}{2}}\sum _{I,j}{w_{IJ}{s_{i}}{s_{j}}}+\sum _{I}{\theta _{i}}{s_{i}}}
 |
^ ugyanaz | a KL divergencia minimalizálása | a következtetés csak továbbítás. a korábbi UL hálózatok előre-hátra futottak | minimalizálja a hibát = rekonstrukciós hiba – KLD | |
| képzés | Xiawij = si*SJ, a +1/-1 neuron | Xiawij = e*(pij – p ‘ IJ) számára. Ez a KLD minimalizálásából származik. e = tanulási arány, p ‘ = előrejelzett és P = tényleges Eloszlás. | contrastive divergence w/ Gibbs mintavétel | wake-sleep 2 fázis képzés | vissza propagálja a rekonstrukciós hiba | reparameterize rejtett állapotban backprop |
| erő | hasonlít a fizikai rendszerek, így örökli az egyenletek | <— ugyanaz. a rejtett neuronok a külső világ belső reprezentációjaként működnek | gyorsabb gyakorlati képzési rendszer, mint a Boltzmann gépek | enyhén anatómiai. elemezhető w/ információ elmélet & statisztikai mechanika | ||
| gyengeség | hopfield | nehéz a vonat miatt oldalirányú kapcsolatok | RBM | Helmholtz |
specifikus hálózatok
itt kiemeljük az egyes hálózatok néhány jellemzőjét. A ferromágnesesség inspirálta a Hopfield hálózatokat, a Boltzmann gépeket és az RBM-eket. A neuron egy vas doménnek felel meg, bináris mágneses momentumokkal felfelé és lefelé, az idegi kapcsolatok pedig a domén egymásra gyakorolt hatásának felelnek meg. A szimmetrikus kapcsolatok lehetővé teszik a globális energia megfogalmazását. A következtetés során a hálózat frissíti az egyes állapotokat a szokásos aktiválási lépés funkcióval. A szimmetrikus súlyok garantálják a stabil aktiválási mintához való konvergenciát.
Hopfield hálózatok használják bütykök és garantáltan rendezni egy bizonyos mintát. Szimmetrikus súlyok nélkül a hálózatot nagyon nehéz elemezni. A megfelelő energiafunkcióval a hálózat konvergál.
Boltzmann gépek sztochasztikus Hopfield hálók. Állapotuk értékét ebből a pdf-ből a következőképpen vesszük ki: tegyük fel, hogy egy bináris neuron P(1) = 1/3 Bernoulli valószínűséggel tüzel, és p(0) = 2/3-mal nyugszik. Az egyik mintát egy egyenletesen elosztott y véletlenszám felvételével, majd az invertált kumulatív eloszlásfüggvénybe dugva, amely ebben az esetben a 2/3-os küszöbön álló lépésfüggvény. Az inverz függvény = { 0 if x <=2/3, 1 if x > 2/3 }
A Helmholtz gépek a variációs automatikus kódolók korai inspirációi. Ez 2 hálózatok egyesítve egy-előre súlyok működik felismerés és hátra súlyok megvalósítja képzelet. Talán ez az első hálózat, amely mindkettőt megteszi. Helmholtz nem dolgozott a gépi tanulásban, de inspirálta a “statisztikai következtetési motor nézetét, amelynek feladata az érzékszervi bemenet valószínű okainak következtetése” (3). a sztochasztikus bináris neuron azt a valószínűséget adja ki, hogy állapota 0 vagy 1. Az adatbevitelt általában nem tekintik rétegnek, de Helmholtz gépgenerálási módban Az adatréteg a középső rétegtől kap bemenetet, erre a célra külön súlyokkal rendelkezik, tehát rétegnek tekintik. Ezért ez a hálózat 3 rétegből áll.
variációs Autoencoder (VAE) ihlette Helmholtz gépek és egyesíti valószínűségi hálózat neurális hálózatok. Az Autoencoder egy 3 rétegű CAM hálózat,ahol a középső réteg állítólag a bemeneti minták belső ábrázolása. A súlyok neve phi & theta, nem pedig W és V, mint Helmholtzban—kozmetikai különbség. A kódoló neurális hálózat egy valószínűségi eloszlás Q(Z|x), a dekóder hálózat pedig P(X|z). Ez a 2 hálózat itt teljesen összekapcsolható, vagy használhat egy másik NN sémát.
Hebbian Learning, ART, som
a felügyelet nélküli tanulás klasszikus példája a neurális hálózatok tanulmányozásában Donald Hebb elve, vagyis az idegsejtek, amelyek együtt tüzelnek, összekapcsolódnak. A Hebbian tanulásban a kapcsolat a hibától függetlenül megerősödik, de kizárólag a két neuron közötti akciós potenciál egybeesésének függvénye. A szinaptikus súlyokat módosító hasonló változat figyelembe veszi az akciós potenciálok közötti időt (tüske-időzítéstől függő plaszticitás vagy STDP). Feltételezték, hogy a Hebbian tanulás számos kognitív funkció alapját képezi, mint például a mintafelismerés és a tapasztalati tanulás.
a neurális hálózati modellek közül az önszerveződő térképet (Som) és az adaptív rezonancia elméletet (Art) gyakran használják felügyelet nélküli tanulási algoritmusokban. A SOM egy topográfiai szervezet, amelyben a térkép közeli helyei hasonló tulajdonságokkal rendelkező bemeneteket képviselnek. Az ART modell lehetővé teszi, hogy a klaszterek száma a probléma méretétől függően változzon, és lehetővé teszi a felhasználó számára, hogy az azonos klaszterek tagjai közötti hasonlóság mértékét egy felhasználó által definiált állandó, az úgynevezett vigilance paraméter segítségével szabályozza. Az ART hálózatokat számos mintafelismerési feladathoz használják, mint például az automatikus célfelismerés és a szeizmikus jelfeldolgozás.