
ebben az oktatóanyagban megtanulhatja a logisztikai regressziót. Itt megtudhatja, mi is pontosan a logisztikai regresszió, és láthat egy példát a Python-nal. A logisztikai regresszió a gépi tanulás fontos témája, és megpróbálom a lehető legegyszerűbbé tenni.
a huszadik század elején a logisztikai regressziót elsősorban a biológiában alkalmazták, ezt követően néhány társadalomtudományi alkalmazásban használták. Ha kíváncsi, megkérdezheti, hol kell használni a logisztikai regressziót? Tehát logisztikai regressziót használunk, amikor független változónk kategorikus.
példák:
- megjósolni, hogy egy személy vesz egy autót (1) vagy (0)
- tudni, hogy a daganat rosszindulatú (1) vagy (0)
most nézzük meg a forgatókönyvet, ahol meg kell osztályozni, hogy egy személy vesz egy autót, vagy sem. Ebben az esetben, ha egyszerű lineáris regressziót használunk, meg kell adnunk egy küszöböt, amelyen az osztályozás elvégezhető.
tegyük fel, hogy a tényleges osztály az a személy, aki megvásárolja az autót, és az előre jelzett folyamatos érték 0,45, az általunk figyelembe vett küszöb pedig 0.5, akkor ezt az adatpontot úgy kell tekinteni, mint az a személy, aki nem vásárolja meg az autót, és ez rossz előrejelzéshez vezet.
tehát arra a következtetésre jutunk, hogy nem használhatunk lineáris regressziót az ilyen típusú osztályozási problémákhoz. Mint tudjuk, a lineáris regresszió korlátozott, tehát itt jön a logisztikai regresszió, ahol az érték szigorúan 0-tól 1-ig terjed.
egyszerű logisztikai regresszió:
Kimenet: 0 vagy 1
hipotézis: K = W * X + B
H(x) = sigmoid(K)
Sigmoid funkció:


A logisztikai regresszió típusai:
bináris logisztikai regresszió
csak két lehetséges kimenetel(Kategória).
példa: a személy vesz egy autót, vagy sem.
multinomiális logisztikai regresszió
Több mint két kategória lehetséges rendelés nélkül.
ordinális logisztikai regresszió
Több mint két kategória lehetséges megrendeléssel.
valós példa Pythonnal:
most logisztikai regresszióval oldunk meg egy valós problémát. Van egy adathalmaz, amelynek 5 oszlopok nevezetesen: User ID, nem, életkor, EstimatedSalary és vásárolt. Most olyan modellt kell építenünk, amely megjósolhatja, hogy az adott paraméteren egy személy vásárol-e autót vagy sem.
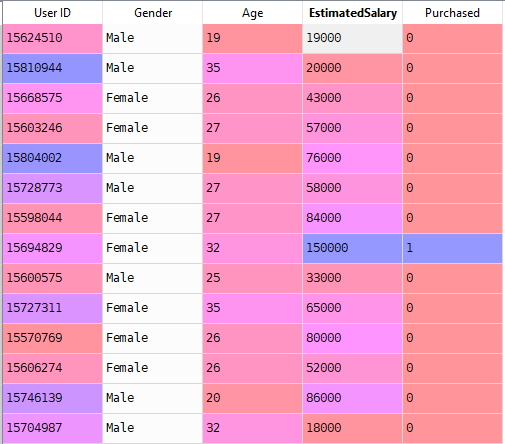
A modell felépítésének lépései:
1. Importing the libraries
itt importálunk könyvtárakat, amelyek szükségesek lesznek a modell felépítéséhez.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
Adatkészletünket egy változóba (azaz adatkészletbe) importáljuk pandák használatával.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
adatkészletünkben az életkorot és az estimatedsalary-t független változónak, a megvásárolt pedig függő változónak tekintjük.
X = dataset.iloc].valuesy = dataset.iloc.valuesitt X független változó, y pedig függő változó.
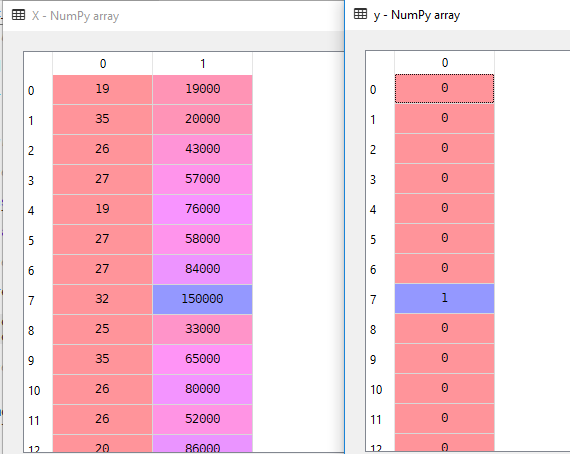
3. Splitting the Data set into the Training Set and Test Set
most az Adatkészletünket képzési és Tesztadatokra osztjuk. Képzési adatok fogják használni, hogy a vonat a
logisztikai modell és vizsgálati adatok fogják használni, hogy érvényesítse a modell. A Sklearn segítségével megosztjuk az adatainkat. Majd import train_test_split származó sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
most elvégezzük a funkció méretezését, hogy az adatainkat 0 és 1 között méretezzük a jobb pontosság érdekében.
itt a méretezés azért fontos, mert óriási különbség van az életkor és a becsült szint között.
- StandardScaler importálása a sklearn – ból.előfeldolgozás
- ezután készítsen sc_x példányt az objektum StandardScaler
- majd illessze be és alakítsa át az X_train-t és alakítsa át az X_test-et
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
most felépítjük osztályozónkat (logisztikai).
- Logisticregression importálása a sklearn-ból.linear_model
- készítsen egy példányosztályozót a LogisticRegression objektumról, és adja meg a
random_state = 0 értéket, hogy minden alkalommal ugyanazt az eredményt kapja. - most használja ezt az osztályozót, hogy illeszkedjen X_train és y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)egészségedre!! A fenti parancs végrehajtása után lesz egy osztályozó, amely megjósolhatja, hogy egy személy vásárol-e autót vagy sem.
most használja az osztályozót a Tesztadatkészlet előrejelzéséhez, és keresse meg a pontosságot a Confusion matrix segítségével.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)most megkapjuk y_pred

most már tudjuk használni y_test (tényleges eredmény) és y_pred ( várható eredmény), hogy a pontosság a modell.
7. Making the Confusion Matrix
a Zavartsági mátrix használatával megkaphatjuk modellünk pontosságát.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)kapsz egy mátrix cm-t .

használja a cm-t a pontosság kiszámításához az alábbiak szerint:
pontosság = (cm + cm) / (összes vizsgálati adatpont)

itt 89% – os pontosságot kapunk . Egészségedre!! jó pontosságot kapunk.
végül megjelenítjük az Edzéskészlet eredményét és a tesztkészlet eredményét. A matplotlib segítségével ábrázoljuk az Adathalmazunkat.
az edzés eredményének megjelenítése
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()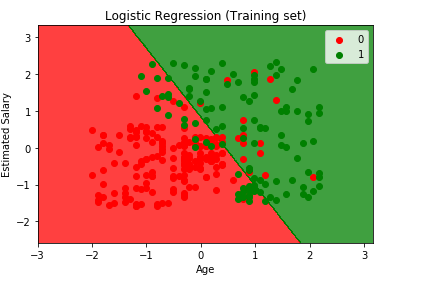
a teszt eredményének megjelenítése
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
most elkészítheti saját osztályozóját a logisztikai regresszióhoz.
köszönöm!! Kódolj Tovább !!
Megjegyzés: Ez egy vendég bejegyzés, és a vélemény ebben a cikkben a Vendég író. Ha bármilyen problémája van a www.marktechpost.com please contact at [email protected]
Advertisement
