minden adatbázis-felhasználó ismeri a rendszeres összesített függvényeket, amelyek egy teljes táblán működnek, és egy GROUP BY záradékkal vannak ellátva. De nagyon kevés ember használja az Ablakfunkciókat az SQL – ben. Ezek sorok halmazán működnek, és minden sorhoz egyetlen összesített értéket adnak vissza.
az Ablakfüggvények használatának fő előnye a szokásos összesített függvényekkel szemben: Az ablakfüggvények nem okoznak sorokat egyetlen kimeneti sorba csoportosítva, a sorok megtartják külön identitásukat, és minden sorhoz összesített értéket adnak.
vessünk egy pillantást az Ablakfunkciók működésére, majd nézzünk meg néhány példát a gyakorlatban való használatára, hogy megbizonyosodjunk arról, hogy a dolgok világosak-e, és hogy az SQL és a kimenet hogyan hasonlítható össze a SUM() függvényekkel.
mint mindig, győződjön meg róla, hogy teljesen biztonsági másolatot készít, különösen, ha új dolgokat próbál ki az adatbázisával.
Bevezetés Az Ablakfunkciókba
az Ablakfunkciók sorok halmazán működnek, és minden sorhoz egyetlen összesített értéket adnak vissza. A kifejezés ablak leírja az adatbázis azon sorait, amelyeken a funkció működni fog.
az ablakot (sorok halmaza, amelyeken a funkciók működnek) egy OVER() záradék segítségével határozzuk meg. Az alábbi cikkben többet fogunk megvitatni az OVER() záradékról.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Ha tartalmazza az összes fog számolni az összes értéket, beleértve a duplikált is. DISTINCT nem támogatott ablakfüggvények
expression
az a céloszlop vagy kifejezés, amelyen a függvények működnek. Más szavakkal, annak az oszlopnak a neve, amelyhez összesített értékre van szükségünk. Például egy oszlop, amely a megrendelés összegét tartalmazza, így láthatjuk az összes beérkezett megrendelést.
OVER
megadja az összesített függvények ablakzáradékait.
PARTITION BY partition_list
meghatározza az ablakot (azon sorok halmazát, amelyeken az ablak funkció működik) az ablakfüggvényekhez. Meg kell adnunk egy mezőt vagy mezők listáját a partíció után PARTITION BY záradék. Több mezőt vesszővel kell elválasztani a szokásos módon. Ha a PARTITION BY nincs megadva, akkor a csoportosítás a teljes táblán történik, és az értékek ennek megfelelően összesítésre kerülnek.
ORDER_LIST
rendezi a sorokat az egyes partíciókon belül. Ha a sorrend nincs megadva, a sorrend a teljes táblázatot használja.
példák
hozzunk létre táblát és illesszünk be dummy rekordokat további lekérdezések írásához. Futtassa a kód alatt.
összesítő ablak függvények
SUM ()
mindannyian ismerjük a SUM () összesítő függvényt. Ez nem az összeg a megadott területen meghatározott csoport (mint a város, állam, ország stb.) vagy az egész táblára, Ha a csoport nincs megadva. Látni fogjuk, hogy mi lesz a kimenete regular SUM() aggregate függvény és window SUM() aggregate függvény.
a következő példa egy regular SUM () aggregate függvényre. Összegzi az egyes városok rendelési összegét.
az eredményhalmazból látható, hogy egy szabályos összesítő függvény több sort csoportosít egyetlen kimeneti sorba, ami az egyes sorok identitásának elvesztését okozza.
|
1
2
3
4
|
válasszon várost, összeget(order_amount) total_order_amount
tól től . Csoport város szerint
|

Ez nem történik meg az ablak összesített funkcióival. A sorok megőrzik identitásukat, és minden sorhoz összesített értéket is mutatnak. Az alábbi példában a lekérdezés ugyanezt teszi, nevezetesen összesíti az egyes városok adatait, és megmutatja az egyes városok teljes rendelési összegének összegét. A lekérdezés azonban most beszúr egy másik oszlopot a teljes rendelési összeghez, így minden sor megőrzi identitását. A grand_total jelöléssel ellátott oszlop az alábbi példa új oszlopa.
AVG()
az AVG vagy az Average pontosan ugyanúgy működik egy Ablakfunkcióval.
a következő lekérdezés megadja az átlagos rendelési összeget minden városban és minden hónapban (bár az egyszerűség kedvéért csak egy hónap adatait használtuk fel).
egynél több átlagot adunk meg több mező megadásával a partíciós listában.
azt is érdemes megjegyezni, hogy a listákban olyan kifejezéseket használhat, mint a hónap(order_date) az alábbi lekérdezés szerint. Mint valaha, ezeket a kifejezéseket olyan összetetté teheti, amennyit csak akar, mindaddig, amíg a szintaxis helyes!
a fenti képből világosan láthatjuk, hogy átlagosan 12 333 megrendelést kaptunk Arlington city-re 2017 áprilisára.
átlagos rendelési összeg = teljes rendelési összeg / összes megrendelés
= (20,000 + 15,000 + 2,000) / 3
= 12,333
az átlag kiszámításához használhatja a sum() & COUNT() függvény kombinációját is.
MIN ()
A MIN () aggregate függvény megtalálja a minimális értéket egy adott csoporthoz vagy az egész táblához, ha a csoport nincs megadva.
például a legkisebb megrendelést (minimális sorrendet) keressük minden városban, amelyet a következő lekérdezést használnánk.
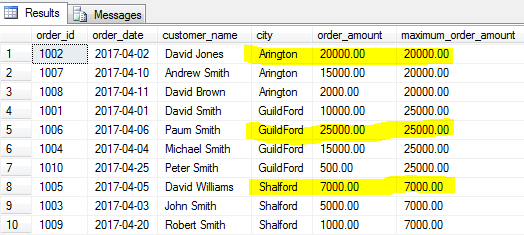
MAX()
ahogy a MIN() függvények megadják a minimális értéket, a MAX() függvény azonosítja a megadott mező legnagyobb értékét egy adott sorcsoporthoz vagy az egész táblához, ha egy csoport nincs megadva.
keressük meg az egyes városok legnagyobb megrendelését (maximális rendelési összeget).
COUNT()
a COUNT() függvény számolja a rekordokat / sorokat.
vegye figyelembe, hogy a distinct nem támogatott a window COUNT() funkcióval, míg a regular COUNT () függvény támogatja. A DISTINCT segít megtalálni egy adott mező különböző értékeit.
például, ha meg akarjuk nézni, hogy hány ügyfél adott le megrendelést 2017 áprilisában, nem tudjuk közvetlenül számolni az összes ügyfelet. Lehetséges, hogy ugyanaz az ügyfél több megrendelést adott le ugyanabban a hónapban.
COUNT (customer_name) hibás eredményt ad, mivel duplikátumokat fog számolni. Míg a COUNT (DISTINCT customer_name) megadja a helyes eredményt, mivel minden egyedi ügyfelet csak egyszer számít.
a regular COUNT() függvényre érvényes:
|
1
2
3
4
5
|
válassza ki a várost,szám(különálló ügyfél_név) number_of_customers
tól től .
csoport város szerint
|
érvénytelen az ablakszám() függvényhez:
a fenti lekérdezés az ablak funkcióval az alábbi hibát adja meg.
most keressük meg az egyes városokhoz kapott teljes megrendelést a window COUNT() függvény segítségével.
rangsorolási Ablakfüggvények
ahogy az ablakösszesítő függvények összesítik egy adott mező értékét, a rangsorolási függvények rangsorolják a megadott mező értékeit, és rangsorolják őket rangjuk szerint.
a rangsorolási függvények leggyakoribb használata a felső (N) rekordok megkeresése egy bizonyos érték alapján. Például, felső 10 legjobban fizetett alkalmazottak, felső 10 rangsorolt hallgatók, felső 50 legnagyobb megrendelések stb.
a következő támogatott rangsorolási függvények:
RANK (), DENSE_RANK (), ROW_NUMBER (), NTILE ()
beszéljük meg őket egyenként.
RANK ()
A RANK () függvény egyedi rangot ad minden rekordnak egy meghatározott érték alapján, például fizetés, megrendelés összege stb.
Ha két rekordnak ugyanaz az értéke, akkor a RANK() függvény ugyanazt a rangot rendeli mindkét rekordhoz A következő rang kihagyásával. Ez azt jelenti – ha két azonos érték van a 2. rangsorban, akkor ugyanazt a 2.rangot rendeli mindkét rekordhoz, majd kihagyja a 3. rangot, és a 4. rangot rendeli a következő rekordhoz.
rangsoroljuk az egyes megrendeléseket a megrendelés összege szerint.
|
1
2
3
4
5
|
select order_id,order_date,customer_name,City,
rang() vége(order_amount desc szerinti sorrend)
tól től .
|
a fenti képen látható, hogy ugyanaz a Rang (3) van hozzárendelve két azonos rekordhoz (mindegyiknek van egy rendelési összege 15,000), majd kihagyja a következő rangot (4), és hozzárendeli az 5.rangot a következő rekordhoz.
DENSE_RANK ()
a DENSE_RANK () függvény megegyezik a RANK () függvénnyel, azzal a különbséggel, hogy nem hagy ki semmilyen rangot. Ez azt jelenti, hogy ha két azonos rekordot találunk, akkor a DENSE_RANK() ugyanazt a rangot rendeli mindkét rekordhoz, de nem hagyja ki, majd kihagyja a következő rangot.
lássuk, hogyan működik ez a gyakorlatban.
amint fent jól látható, ugyanazt a rangot kapja két azonos rekord (mindegyik azonos rendelési összeggel rendelkezik), majd a következő rangszámot kapja a következő rekordnak anélkül, hogy kihagyná a rangértéket.
ROW_NUMBER ()
a név magától értetődő. Ezek a függvények minden rekordhoz egyedi sorszámot rendelnek.
minden partíció sorszáma visszaáll, ha a PARTITION BY meg van adva. Lássuk, hogyan működik a ROW_NUMBER() partíció nélkül, majd a partíció által.
ROW_ NUMBER () partíció nélkül
ROW_NUMBER() partícióval
vegye figyelembe, hogy a partíciót a városban végeztük. Ez azt jelenti, hogy a sorszám minden városban visszaáll, így újra 1-nél újraindul. A sorok sorrendjét azonban a rendelési összeg határozza meg, így bármely adott város esetében a legnagyobb rendelési összeg lesz az első sor, így az 1.sorszám lesz hozzárendelve.
NTILE ()
NTILE () egy nagyon hasznos ablak funkció. Segít azonosítani, hogy egy adott sor melyik percentilisbe (vagy kvartilisbe vagy bármely más felosztásba) esik.
Ez azt jelenti, hogy ha 100 sor van, és 4 kvartilt szeretne létrehozni egy megadott értékmező alapján, akkor ezt könnyen megteheti, és láthatja, hogy hány sor esik az egyes kvartilisekbe.
nézzünk egy példát. Az alábbi lekérdezésben meghatároztuk, hogy négy kvartilt akarunk létrehozni a megrendelés összege alapján. Ezután szeretnénk látni, hogy hány megrendelés esik az egyes kvartilisekbe.
az NTILE a következő képlet alapján hoz létre csempéket:
sorok száma az egyes lapkákban = az eredményhalmaz sorainak száma / a megadott lapok száma
itt van a példa, összesen 10 sorunk van, és 4 lapka van megadva a lekérdezésben, így az egyes lapok sorainak száma 2,5 (10/4) lesz. Mivel a Sorok száma legyen egész szám, nem tizedes. Az SQL engine 3 sort rendel az első két csoporthoz, a fennmaradó két csoporthoz pedig 2 sort.
érték ablak függvények
LAG() és LEAD()
LEAD() és LAG() függvények nagyon erősek, de bonyolultan megmagyarázhatók.
mivel ez egy bevezető cikk az alábbiakban, egy nagyon egyszerű példát vizsgálunk, hogy bemutassuk, hogyan kell használni őket.
a LAG funkció lehetővé teszi az előző sor adatainak elérését ugyanabban az eredményhalmazban SQL illesztések használata nélkül. Az alábbi példában láthatja, a LAG funkció használatával megtaláltuk az előző megrendelés dátumát.
parancsfájl az előző megrendelés dátumának megkereséséhez a LAG() függvény használatával:
a LEAD funkció lehetővé teszi az adatok elérését ugyanazon eredménykészlet következő sorából SQL illesztések használata nélkül. Az alábbi példában láthatja, a LEAD funkció használatával megtaláltuk a következő megrendelés dátumát.
parancsfájl a következő sorrend dátumának megkereséséhez a LEAD() függvény használatával:
FIRST_VALUE() és LAST_VALUE () ezek a funkciók segítenek azonosítani az első és az utolsó rekordot egy partíción vagy a teljes táblán belül, ha a PARTITION BY nincs megadva.
keressük meg az egyes városok első és utolsó sorrendjét a meglévő adatkészletünkből. Megjegyzés: a rendelési záradék kötelező a FIRST_VALUE() és a LAST_VALUE () függvényeknél
a fenti képen jól látható, hogy az első megrendelés 2017-04-02-én, az utolsó megrendelés pedig 2017-04-11-ben érkezett Arlington city esetében, és ugyanúgy működik más városokban is.
hasznos linkek
- Backup típusok& stratégiák SQL adatbázisok
- TechNet cikket A OVER záradék
- MSDN cikket DENSE_RANK
egyéb nagy cikkek Ben
hogyan SQL Server kiválaszt egy holtpont áldozat
hogyan kell használni az ablak funkciók
- szerző
- legutóbbi hozzászólások
Ben Richardson összes hozzászólásának megtekintése
- Power BI: vízesés diagramok és kombinált látvány – január 19, 2021
- Power BI: Feltételes formázás és adatszínek működés közben-január 14, 2021
- Power BI: Adatok importálása SQL Server és MySQL – január 12, 2021