BasicsEdit
In primo luogo, alcuni vocaboli:
| attivazione | = valore di stato del neurone. Per i neuroni binari, questo è di solito 0 / 1 o +1 / -1. |
| CAM | = memoria indirizzabile del contenuto. Richiamo di una memoria da un modello parziale invece di un indirizzo di memoria. |
| convergenza | = stabilizzazione di un pattern di attivazione su una rete. In SL, convergenza significa stabilizzazione dei pesi& pregiudizi piuttosto che attivazioni. |
| discriminativo | = relativo ai compiti di riconoscimento. Chiamato anche analisi (in Teoria dei modelli), o inferenza. |
| energia | = una quantità macroscopica che descrive il modello di attivazione in una rete. (vedi sotto) |
| generalizzazione | = comportarsi con precisione su ingressi precedentemente non incontrati |
| generativo | = Macchina immaginata e richiamo compito. a volte chiamato sintesi (in Teoria dei modelli), mimetismo o falsi profondi. |
| inferenza | = la fase “run” (al contrario dell’allenamento). Durante l’inferenza, la rete esegue l’attività a cui è addestrata—riconoscendo un modello (SL) o creandone uno (UL). Di solito l’inferenza scende il gradiente di una funzione energetica. In contrasto con SL, la discesa del gradiente si verifica durante l’allenamento, NON l’inferenza. |
| visione artificiale | = apprendimento automatico sulle immagini. |
| NLP | = Elaborazione del linguaggio naturale. Apprendimento automatico delle lingue umane. |
| pattern | = attivazioni di rete che hanno un ordine interno in un certo senso, o che possono essere descritte in modo più compatto dalle funzionalità nelle attivazioni. Ad esempio, il modello di pixel di uno zero, che sia dato come dati o immaginato dalla rete, ha una caratteristica che è descrivibile come un singolo ciclo. Le caratteristiche sono codificate nei neuroni nascosti. |
| formazione | = la fase di apprendimento. Qui, la rete regola i suoi pesi& pregiudizi per imparare dagli input. |
Attività

I metodi UL di solito preparano una rete per attività generative piuttosto che per il riconoscimento, ma raggruppare le attività come supervisionate o meno può essere confuso. Ad esempio, il riconoscimento della grafia iniziato nel 1980 come SL. Poi nel 2007, UL viene utilizzato per innescare la rete per SL in seguito. Attualmente, SL ha riacquistato la sua posizione come il metodo migliore.
Training
Durante la fase di apprendimento, una rete non supervisionata cerca di imitare i dati forniti e utilizza l’errore nel suo output imitato per correggersi (ad es. i suoi pesi & pregiudizi). Questo assomiglia al comportamento mimetico dei bambini mentre imparano una lingua. A volte l’errore è espresso come una bassa probabilità che si verifichi l’output errato, o potrebbe essere espresso come uno stato di alta energia instabile nella rete.
Energia
Una funzione energetica è una misura macroscopica dello stato di una rete. Questa analogia con la fisica è ispirata dall’analisi di Ludwig Boltzmann dell’energia macroscopica di un gas dalle probabilità microscopiche del moto delle particelle p {{\displaystyle \propto }

eE/kT, dove k è la costante di Boltzmann e T è la temperatura. Nel RBM rete la relazione p = e-e / Z, dove p & E variare oltre ogni possibile pattern di attivazione e Z = ∑ A l l A P a t t e r a n s {\displaystyle \sum _{AllPatterns}}

e-e(pattern). Per essere più precisi, p(a) = e-E (a) / Z, dove a è un modello di attivazione di tutti i neuroni (visibili e nascosti). Quindi, le prime reti neurali portano il nome di Boltzmann Machine. Paul Smolensky chiama-E l’Armonia. Una rete cerca bassa energia che è alta Armonia.
Reti
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
 |
 autoencoder
|
 variazionali autoencoder
|
Boltzmann e di Helmholtz è venuto prima di reti neurali formulazioni, ma queste reti in prestito da loro analisi, in modo che queste reti portano il loro nome. Hopfield, tuttavia, ha contribuito direttamente a UL.
IntermediateEdit
Qui, le distribuzioni p(x) e q(x) saranno abbreviate come p e q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. E ‘ per lo più utilizzato in SL, ma merita una menzione qui. |
| 1982 | Ising variant Hopfield net descritto come CAMME e classificatori da John Hopfield. |
| 1983 | Variante di Ising Macchina di Boltzmann con neuroni probabilistici descritta da Hinton & Sejnowski dopo Sherington & Il lavoro di Kirkpatrick del 1975. |
| 1986 | Paul Smolensky pubblica la Teoria dell’Armonia, che è un RBM con praticamente la stessa funzione energetica di Boltzmann. Smolensky non ha dato uno schema di formazione pratica. Hinton ha fatto a metà degli anni 2000 |
| 1995 | Schmidthuber introduce il neurone LSTM per le lingue. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| Probabilità | |
| cdf | = funzione di distribuzione cumulativa. l’integrale del pdf. La probabilità di avvicinarsi a 3 è l’area sotto la curva tra 2.9 e 3.1. |
| divergenza contrastiva | = un metodo di apprendimento in cui si abbassa l’energia sui modelli di allenamento e aumenta l’energia sui modelli indesiderati al di fuori del set di allenamento. Questo è molto diverso dalla divergenza KL, ma condivide una formulazione simile. |
| valore atteso | = E(x) = ∑ x {\displaystyle \sum _{x}}
 x * p(x). Questo è il valore medio, o valore medio. Per l’ingresso continuo x, sostituire la somma con un integrale. |
| variabile latente | = una quantità non osservata che aiuta a spiegare i dati osservati. ad esempio, un’infezione influenzale (non osservata) può spiegare perché una persona starnutisce (osservata). Nelle reti neurali probabilistiche, i neuroni nascosti agiscono come variabili latenti, sebbene la loro interpretazione latente non sia esplicitamente nota. |
| = funzione di densità di probabilità. La probabilità che una variabile casuale assume un certo valore. Per il pdf continuo, p (3) = 1/2 può ancora significare che c’è quasi zero possibilità di raggiungere questo valore esatto di 3. Razionalizziamo questo con il cdf. | |
| stocastico | = si comporta secondo una formula di densità di probabilità ben descritta. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. È il massimo lavoro reversibile che può essere eseguito da un sistema di calore a temperatura e pressione costanti. energia libera G = calore * temperatura di entropia |
| informazioni | = la quantità di informazione di un messaggio x = -log p(x) |
| KLD | = relativa entropia. Per le reti probabilistiche, questo è l’analogo dell’errore tra input & imitato output. La divergenza di Kullback-Liebler (KLD) misura la deviazione di entropia di 1 distribuzione da un’altra distribuzione. KLD( p, q) = x x {\displaystyle \sum _{x}}
p * log (p / q ). In genere, p riflette i dati di input, q riflette l’interpretazione della rete e KLD riflette la differenza tra i due. |
Confronto delle Reti.
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE | |
|---|---|---|---|---|---|---|
| utilizzo & personaggi | CAM, traveling salesman problem | CAM. La libertà di connessione rende questa rete difficile da analizzare. | pattern recognition (MNIST, riconoscimento vocale) | immaginazione, mimetismo | lingua: scrittura creativa, traduzione. Visione: migliorare le immagini sfocate | generare dati realistici |
| neurone | stato binario deterministico. Attivazione = { 0 (o -1) se x è negativo, 1 altrimenti } | binario stocastico Neurone di Hopfield | binario stocastico. Esteso a valore reale a metà degli anni 2000 | binario, sigmoid | lingua: LSTM. visione: campi ricettivi locali. di solito reale valore di attivazione relu. | |
| connessioni | 1 strato con pesi simmetrici. Nessuna auto-connessione. | 2 strati. 1-nascosto & 1-visibile. pesi simmetrici. | 2 strati. pesi simmetrici. nessuna connessione laterale all’interno di uno strato. | 3 strati: pesi asimmetrici. 2 reti combinate in 1. | 3 strati. L’input è considerato un livello anche se non ha pesi in entrata. strati ricorrenti per PNL. convoluzioni feedforward per la visione. input & output hanno lo stesso numero di neuroni. | 3-strati: ingresso, encoder, distribuzione campionatore decoder. il campionatore non è considerato uno strato (e) |
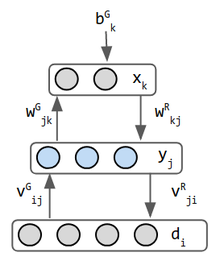
| inferenza & energia | l’energia è data dalla misura di probabilità di Gibbs : E = 1 2 ∑ i , j w j s s j + ∑ i q i s i {\displaystyle E=-{\frac {1}{2}}\sum _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\sum _{i}{\theta _{i}}{s_{i}}}
 |
← stesso | ← stesso | ridurre al minimo KL divergenza | inferenza è solo di tipo feed-forward. le reti UL precedenti correvano avanti E indietro | minimizza error = reconstruction error – KLD |
| training | Δwij = si*sj, per +1/-1 neurone | Δwij = e*(pij – p’ij). Questo deriva dalla riduzione al minimo di KLD. e = tasso di apprendimento, p’ = predetto e p = distribuzione effettiva. | contrastiva divergenza w/ Gibbs Sampling | veglia-sonno 2 fase di formazione | indietro propagare l’errore di ricostruzione | riparametrizzare stato nascosto per backprop |
| forza | assomiglia a sistemi fisici in modo che eredita le loro equazioni | <– stesso. i neuroni nascosti agiscono come rappresentazione interna del mondo esterno | schema di allenamento più veloce e pratico rispetto alle macchine Boltzmann | leggermente anatomico. analizzabili w/ teoria dell’informazione & meccanica statistica | ||
| debolezza | hopfield | difficile treno a causa di connessioni laterali | RBM | Helmholtz |
Specifiche Reti.
Qui, si evidenziano alcune caratteristiche di ogni rete. Ferromagnetismo ispirato reti Hopfield, macchine Boltzmann, e meccanismi. Un neurone corrisponde a un dominio di ferro con momenti magnetici binari Su e Giù, e le connessioni neurali corrispondono all’influenza del dominio l’una sull’altra. Le connessioni simmetriche consentono una formulazione energetica globale. Durante l’inferenza la rete aggiorna ogni stato utilizzando la funzione passo di attivazione standard. I pesi simmetrici garantiscono la convergenza a un modello di attivazione stabile.
Reti Hopfield sono utilizzati come CAMME e sono garantiti per stabilirsi ad un qualche modello. Senza pesi simmetrici, la rete è molto difficile da analizzare. Con la giusta funzione energetica, una rete convergerà.
Macchine Boltzmann sono reti Hopfield stocastici. Il loro valore di stato è campionato da questo pdf come segue: supponiamo che un neurone binario fires con la probabilità di Bernoulli p(1) = 1/3 e riposa con p(0) = 2/3. Un campione da esso prendendo un numero casuale uniformemente distribuito y e collegandolo alla funzione di distribuzione cumulativa invertita, che in questo caso è la funzione di passo con soglia a 2/3. La funzione inversa = {0 if x<= 2/3, 1 if x> 2/3}
Le macchine Helmholtz sono le prime ispirazioni per gli encoder Auto Variazionali. E ‘ 2 reti combinate in uno-pesi in avanti opera riconoscimento e pesi all’indietro implementa immaginazione. È forse la prima rete a fare entrambe le cose. Helmholtz non ha lavorato in machine learning, ma ha ispirato la visione di “statistical inference engine la cui funzione è quella di dedurre probabili cause di input sensoriale” (3). il neurone binario stocastico emette una probabilità che il suo stato sia 0 o 1. L’input dei dati non è normalmente considerato un livello, ma nella modalità di generazione della macchina Helmholtz, il livello dati riceve input dallo strato intermedio ha pesi separati per questo scopo, quindi è considerato un livello. Quindi questa rete ha 3 livelli.
Variational Autoencoder (VAE) sono ispirati da macchine Helmholtz e combina rete probabilità con reti neurali. Un Autoencoder è una rete CAM a 3 strati, in cui lo strato intermedio dovrebbe essere una rappresentazione interna dei modelli di input. I pesi sono chiamati phi& theta piuttosto che W e V come in Helmholtz-una differenza estetica. La rete neurale del codificatore è una distribuzione di probabilità qφ(z|x) e la rete del decodificatore è pθ (x|z). Queste 2 reti qui possono essere completamente collegate o utilizzare un altro schema NN.
Apprendimento hebbiano, ARTE, SOM
L’esempio classico di apprendimento non supervisionato nello studio delle reti neurali è il principio di Donald Hebb, cioè i neuroni che sparano insieme collegano insieme. Nell’apprendimento hebbiano, la connessione è rinforzata indipendentemente da un errore, ma è esclusivamente una funzione della coincidenza tra i potenziali d’azione tra i due neuroni. Una versione simile che modifica i pesi sinaptici prende in considerazione il tempo tra i potenziali d’azione (plasticità dipendente da spike-timing o STDP). È stato ipotizzato che l’apprendimento hebbiano sia alla base di una serie di funzioni cognitive, come il riconoscimento dei pattern e l’apprendimento esperienziale.
Tra i modelli di reti neurali, la mappa auto-organizzante (SOM) e la teoria della risonanza adattiva (ART) sono comunemente utilizzate negli algoritmi di apprendimento non supervisionati. Il SOM è un’organizzazione topografica in cui le posizioni vicine nella mappa rappresentano input con proprietà simili. Il modello ART consente al numero di cluster di variare con la dimensione del problema e consente all’utente di controllare il grado di somiglianza tra i membri degli stessi cluster mediante una costante definita dall’utente chiamata parametro di vigilanza. Le reti ART sono utilizzate per molte attività di riconoscimento dei pattern, come il riconoscimento automatico dei target e l’elaborazione del segnale sismico.