
In questo tutorial, imparerete di Regressione Logistica. Qui saprai cos’è esattamente la regressione logistica e vedrai anche un esempio con Python. La regressione logistica è un argomento importante dell’apprendimento automatico e cercherò di renderlo il più semplice possibile.
All’inizio del XX secolo, la regressione logistica è stata utilizzata principalmente in biologia dopo questo, è stata utilizzata in alcune applicazioni di scienze sociali. Se sei curioso, potresti chiedere dove dovremmo usare la regressione logistica? Quindi usiamo la regressione logistica quando la nostra variabile indipendente è categorica.
Esempi:
- Per prevedere se una persona comprerà un’auto (1) o (0)
- Per sapere se il tumore è maligno (1) o (0)
Consideriamo ora uno scenario in cui devi classificare se una persona comprerà un’auto o meno. In questo caso, se usiamo la regressione lineare semplice, dovremo specificare una soglia su cui è possibile eseguire la classificazione.
Diciamo che la classe effettiva è la persona che comprerà l’auto, e il valore continuo previsto è 0.45 e la soglia che abbiamo considerato è 0.5, quindi questo punto di dati sarà considerato come la persona non comprerà l’auto e questo porterà alla previsione sbagliata.
Quindi concludiamo che non possiamo usare la regressione lineare per questo tipo di problema di classificazione. Come sappiamo la regressione lineare è limitata, quindi ecco la regressione logistica in cui il valore varia rigorosamente da 0 a 1.
Semplice Regressione Logistica:
Uscita: 0 o 1
Ipotesi: K = W * X + B
hΘ(x) = sigma(K)
Funzione Sigmoidea:


Tipi di regressione logistica:
Regressione logistica binaria
Solo due possibili risultati(Categoria).
Esempio: La persona comprerà una macchina o no.
Regressione logistica multinomiale
Più di due categorie possibili senza ordinare.
Regressione logistica ordinale
Più di due categorie possibili con l’ordinazione.
Esempio del mondo reale con Python:
Ora risolveremo un problema del mondo reale con la regressione logistica. Abbiamo un set di dati con 5 colonne, ovvero: ID utente, Sesso, età, Stima e acquisto. Ora dobbiamo costruire un modello in grado di prevedere se sul parametro dato una persona comprerà un’auto o meno.
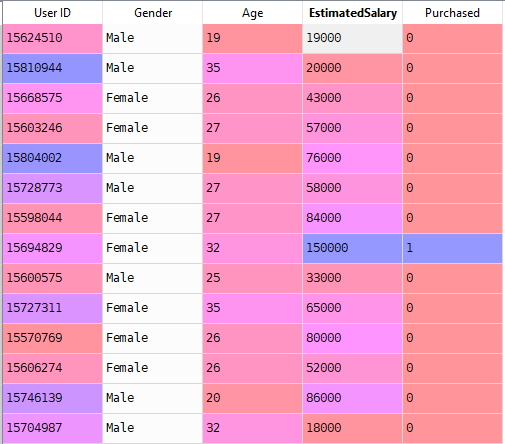
Passi per costruire il modello:
1. Importing the libraries
Qui importeremo le librerie che saranno necessarie per costruire il modello.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
Importeremo il nostro set di dati in una variabile (ad esempio dataset) usando panda.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
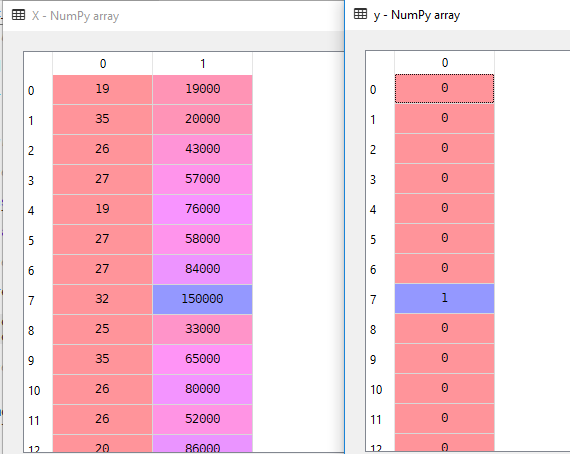
Nel nostro set di Dati prenderemo in considerazione l’Età e EstimatedSalary come variabile Indipendente e Acquistato come Variabile Dipendente.
X = dataset.iloc].valuesy = dataset.iloc.valuesQui X è variabile indipendente e y è variabile dipendente.
3. Splitting the Data set into the Training Set and Test Set
Ora divideremo il nostro set di dati in Dati di allenamento e dati di test. I dati di allenamento verranno utilizzati per addestrare il nostro modello logistico e i dati di test verranno utilizzati per convalidare il nostro modello. Useremo Sklearn per dividere i nostri dati. Importeremo train_test_split da sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
Ora le faremo caratteristica scala a scala nostri dati tra 0 e 1 per ottenere una migliore precisione.
Qui il ridimensionamento è importante perché c’è un’enorme differenza tra Età e stima.
- Importazione StandardScaler da sklearn.pre-elaborazione
- Poi fare un’istanza sc_X dell’oggetto StandardScaler
- Quindi adattare e trasformare X_train e trasformare X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Ora potremo costruire il nostro classificatore (Logistica).
- Importa LogisticRegression da sklearn.linear_model
- Crea un classificatore di istanza dell’oggetto LogisticRegression e dai
random_state = 0 per ottenere lo stesso risultato ogni volta. - Ora usa questo classificatore per adattare X_train e y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Saluti!! Dopo aver eseguito il comando precedente avrai un classificatore in grado di prevedere se una persona comprerà un’auto o meno.
Ora usa il classificatore per fare la previsione per il set di dati di test e trovare la precisione usando la matrice di confusione.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)Ora avremo y_pred

Ora siamo in grado di utilizzare y_test (Risultato) e y_pred ( Risultato Previsto) per ottenere la precisione del nostro modello.
7. Making the Confusion Matrix
Usando la matrice di confusione possiamo ottenere la precisione del nostro modello.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)Si otterrà una matrice cm .

Utilizzare cm per calcolare la precisione come mostrato di seguito:
Accuracy = ( cm + cm) /(Total test data points)

Qui stiamo ottenendo una precisione dell ‘ 89 % . Salute!! stiamo ottenendo una buona precisione.
Infine, visualizzeremo il risultato del set di allenamento e il risultato del set di test. Useremo matplotlib per tracciare il nostro set di dati.
Visualizzare il Set di Training risultato
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()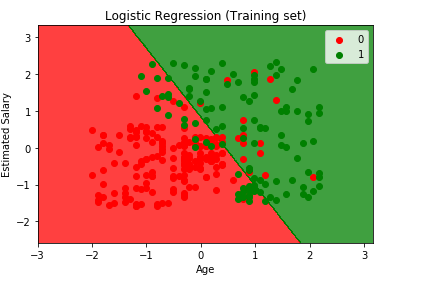
Visualizzare il Set di Test risultato
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Ora È possibile costruire il proprio classificatore per la Regressione Logistica.
Grazie!! Continua a codificare !!
Nota: Questo è un guest post e l’opinione in questo articolo è dello scrittore ospite. Se avete problemi con uno qualsiasi degli articoli pubblicati sul sito www.post di mercato.com please contact at [email protected]
Advertisement
