Tutti gli utenti del database conoscono le normali funzioni aggregate che operano su un’intera tabella e vengono utilizzate con una clausola GROUP BY. Ma pochissime persone usano le funzioni della finestra in SQL. Questi operano su un insieme di righe e restituiscono un singolo valore aggregato per ogni riga.
Il vantaggio principale dell’utilizzo delle funzioni della finestra rispetto alle normali funzioni aggregate è: Le funzioni finestra non fanno sì che le righe vengano raggruppate in una singola riga di output, le righe mantengono le loro identità separate e un valore aggregato verrà aggiunto a ciascuna riga.
Diamo un’occhiata a come funzionano le funzioni della finestra e poi vediamo alcuni esempi di utilizzo in pratica per essere sicuri che le cose siano chiare e anche come SQL e output si confrontino con quello per le funzioni SUM ().
Come sempre assicurati di aver eseguito il backup completo, specialmente se stai provando nuove cose con il tuo database.
Introduzione alle funzioni della finestra
Le funzioni della finestra operano su un insieme di righe e restituiscono un singolo valore aggregato per ogni riga. La finestra term descrive l’insieme di righe nel database su cui opererà la funzione.
Definiamo la Finestra (insieme di righe su cui operano le funzioni) usando una clausola OVER (). Discuteremo di più sulla clausola OVER() nell’articolo qui sotto.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Quando includerai TUTTO, conterà tutti i valori inclusi quelli duplicati. DISTINCT non è supportato in window functions
expression
La colonna di destinazione o l’espressione su cui operano le funzioni. In altre parole, il nome della colonna per la quale abbiamo bisogno di un valore aggregato. Ad esempio, una colonna contenente importo dell’ordine in modo che possiamo vedere gli ordini totali ricevuti.
OVER
Specifica le clausole finestra per le funzioni aggregate.
PARTITION BY partition_list
Definisce la finestra (insieme di righe su cui opera la funzione window) per le funzioni window. Dobbiamo fornire un campo o un elenco di campi per la partizione dopo la clausola PARTITION BY. Più campi devono essere separati da una virgola come al solito. Se PARTITION BY non è specificato, il raggruppamento verrà eseguito sull’intera tabella e i valori verranno aggregati di conseguenza.
ORDINA PER order_list
Ordina le righe all’interno di ogni partizione. Se ORDER BY non è specificato, ORDER BY utilizza l’intera tabella.
Esempi
Creiamo una tabella e inseriamo record fittizi per scrivere ulteriori query. Esegui sotto il codice.
Funzioni aggregate della finestra
SUM ()
Conosciamo tutti la funzione aggregata SUM (). Fa la somma del campo specificato per il gruppo specificato (come città, stato, paese ecc.) o per l’intera tabella se il gruppo non è specificato. Vedremo quale sarà l’output della funzione di aggregazione regolare SUM() e della funzione di aggregazione Window SUM ().
Il seguente è un esempio di una funzione di aggregazione regolare SUM (). Somma l’importo dell’ordine per ogni città.
È possibile vedere dal set di risultati che una funzione aggregata regolare raggruppa più righe in una singola riga di output, il che fa perdere la propria identità alle singole righe.
|
1
2
3
4
|
SELEZIONARE la città, SUM(order_amount) total_order_amount
DA . RAGGRUPPA PER città
|

Questo non accade con le funzioni di aggregazione delle finestre. Le righe mantengono la loro identità e mostrano anche un valore aggregato per ogni riga. Nell’esempio seguente la query fa la stessa cosa, ovvero aggrega i dati per ogni città e mostra la somma dell’importo totale dell’ordine per ciascuno di essi. Tuttavia, la query ora inserisce un’altra colonna per l’importo totale dell’ordine in modo che ogni riga mantenga la sua identità. La colonna contrassegnata grand_total è la nuova colonna nell’esempio seguente.
AVG ()
AVG o Average funziona esattamente allo stesso modo con una funzione Window.
La seguente query ti darà l’importo medio dell’ordine per ogni città e per ogni mese (anche se per semplicità abbiamo utilizzato solo i dati in un mese).
Specifichiamo più di una media specificando più campi nell’elenco delle partizioni.
Vale anche la pena notare che è possibile utilizzare espressioni negli elenchi come MONTH(order_date) come mostrato nella query sottostante. Come sempre puoi rendere queste espressioni complesse come vuoi purché la sintassi sia corretta!
Dall’immagine sopra, possiamo chiaramente vedere che in media abbiamo ricevuto ordini di 12.333 per Arlington city per aprile, 2017.
Importo medio dell’ordine = Importo totale dell’ordine/Ordini totali
= (20,000 + 15,000 + 2,000) / 3
= 12,333
È inoltre possibile utilizzare la combinazione di SUM ()& COUNT() funzione per calcolare una media.
MIN ()
La funzione di aggregazione MIN() troverà il valore minimo per un gruppo specificato o per l’intera tabella se il gruppo non è specificato.
Ad esempio, stiamo cercando l’ordine più piccolo (ordine minimo) per ogni città che useremmo la seguente query.
MAX ()
Proprio come le funzioni MIN() ti danno il valore minimo, la funzione MAX() identificherà il valore più grande di un campo specificato per un gruppo di righe specificato o per l’intera tabella se un gruppo non è specificato.
troviamo l’ordine più grande (importo massimo dell’ordine) per ogni città.
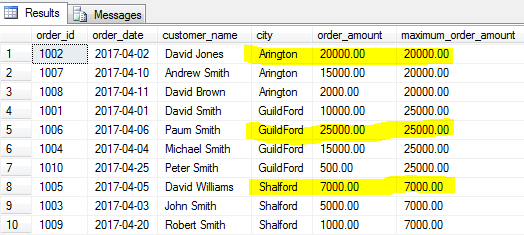
COUNT ()
La funzione COUNT() conterà i record / righe.
Si noti che DISTINCT non è supportato con la funzione window COUNT() mentre è supportato per la funzione COUNT () regolare. DISTINCT aiuta a trovare i valori distinti di un campo specificato.
Ad esempio, se vogliamo vedere quanti clienti hanno effettuato un ordine ad aprile 2017, non possiamo contare direttamente tutti i clienti. È possibile che lo stesso cliente abbia effettuato più ordini nello stesso mese.
COUNT (customer_name) ti darà un risultato errato in quanto conterà i duplicati. Considerando che COUNT (DISTINCT customer_name) ti darà il risultato corretto in quanto conta ogni cliente univoco solo una volta.
Valido per la funzione COUNT () regolare:
|
1
2
3
4
5
|
SELEZIONARE la città,COUNT(DISTINCT customer_name) number_of_customers
DA .
GRUPPO PER città
|
Non valido per la funzione window COUNT ():
La query di cui sopra con la funzione Window vi darà sotto errore.
Ora, troviamo l’ordine totale ricevuto per ogni città utilizzando la funzione window COUNT ().
Classificazione delle funzioni della finestra
Proprio come le funzioni di aggregazione della finestra aggregano il valore di un campo specificato, le funzioni di classificazione classificano i valori di un campo specificato e li classificano in base al loro rango.
L’uso più comune delle funzioni di classificazione è trovare i record top (N) in base a un determinato valore. Ad esempio, i 10 dipendenti più pagati, i 10 studenti classificati, i 50 ordini più grandi, ecc.
Sono supportate le seguenti funzioni di CLASSIFICAZIONE:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE ()
Discutiamole una per una.
RANK ()
La funzione RANK () viene utilizzata per dare un rango univoco a ciascun record in base a un valore specificato, ad esempio stipendio, importo dell’ordine ecc.
Se due record hanno lo stesso valore, la funzione RANK() assegnerà lo stesso rango a entrambi i record saltando il rango successivo. Ciò significa-se ci sono due valori identici al rango 2, assegnerà lo stesso rango 2 a entrambi i record e quindi salterà il rango 3 e assegnerà il rango 4 al record successivo.
Classifichiamo ogni ordine in base all’importo dell’ordine.
|
1
2
3
4
5
|
SELEZIONARE order_id,order_date customer_name,città,
RANK() OVER(ORDER BY order_amount DESC)
DA .
|
Dall’immagine qui sopra, si può vedere che lo stesso rango (3) viene assegnato a due record identici (ciascuna con un importo dell’ordine di 15.000) e poi salta la prossima classifica (4) e assegnare rank 5 al record successivo.
DENSE_RANK ()
La funzione DENSE_RANK() è identica alla funzione RANK() tranne per il fatto che non salta alcun rank. Ciò significa che se vengono trovati due record identici, DENSE_RANK() assegnerà lo stesso rango a entrambi i record ma non salta, quindi salta il rango successivo.
Vediamo come funziona in pratica.
Come puoi vedere chiaramente sopra, lo stesso rango viene dato a due record identici (ognuno con lo stesso importo dell’ordine) e quindi il numero di rango successivo viene dato al record successivo senza saltare un valore di rango.
ROW_NUMBER ()
Il nome è auto-esplicativo. Queste funzioni assegnano un numero di riga univoco a ciascun record.
Il numero di riga verrà resettato per ogni partizione se è specificato PARTITION BY. Vediamo come ROW_NUMBER () funziona senza PARTITION BY e poi con PARTITION BY.
ROW_ NUMBER() senza PARTIZIONE DA
ROW_NUMBER () con PARTIZIONE DA
Si noti che abbiamo fatto la partizione sulla città. Ciò significa che il numero di riga viene ripristinato per ogni città e quindi riavvia nuovamente a 1. Tuttavia, l’ordine delle righe è determinato dall’importo dell’ordine in modo che per una data città l’importo dell’ordine maggiore sia la prima riga e quindi assegnato il numero di riga 1.
NTILE ()
NTILE() è una funzione finestra molto utile. Ti aiuta a identificare in quale percentile (o quartile, o qualsiasi altra suddivisione) cade una determinata riga.
Ciò significa che se si dispone di 100 righe e si desidera creare 4 quartili in base a un campo valore specificato, è possibile farlo facilmente e vedere quante righe cadono in ciascun quartile.
Vediamo un esempio. Nella query di seguito, abbiamo specificato che vogliamo creare quattro quartili in base all’importo dell’ordine. Vogliamo quindi vedere quanti ordini cadono in ogni quartile.
NTILE crea piastrelle in base alla seguente formula:
Numero di righe in ogni riquadro = numero di righe nel set di risultati / numero di tessere specificate
Ecco il nostro esempio, abbiamo un totale di 10 righe e 4 tessere sono specificate nella query, quindi il numero di righe in ogni riquadro sarà 2.5 (10/4). Come numero di righe dovrebbe essere il numero intero, non un decimale. SQL engine assegnerà 3 righe per i primi due gruppi e 2 righe per i restanti due gruppi.
Funzioni della finestra dei valori
LAG() e LEAD ()
Le funzioni LEAD() e LAG() sono molto potenti ma possono essere complesse da spiegare.
Poiché questo è un articolo introduttivo qui sotto stiamo guardando un esempio molto semplice per illustrare come usarli.
La funzione LAG consente di accedere ai dati della riga precedente nello stesso set di risultati senza l’uso di join SQL. Puoi vedere nell’esempio seguente, usando la funzione LAG abbiamo trovato la data dell’ordine precedente.
Script per trovare la data dell’ordine precedente utilizzando la funzione LAG ():
La funzione LEAD consente di accedere ai dati dalla riga successiva nello stesso set di risultati senza l’uso di join SQL. Puoi vedere nell’esempio qui sotto, usando la funzione LEAD abbiamo trovato la prossima data dell’ordine.
Script per trovare la data del prossimo ordine usando la funzione LEAD ():
FIRST_VALUE() e LAST_VALUE()
Queste funzioni aiutano a identificare il primo e l’ultimo record all’interno di una partizione o di un’intera tabella se PARTITION BY non è specificato.
Troviamo il primo e l’ultimo ordine di ogni città dal nostro set di dati esistente. Nota La clausola ORDER BY è obbligatoria per le funzioni FIRST_VALUE() e LAST_VALUE ()
Dall’immagine sopra, possiamo vedere chiaramente che il primo ordine ricevuto il 2017-04-02 e l’ultimo ordine ricevuto il 2017-04-11 per Arlington city e funziona allo stesso modo per altre città.
Link Utili
- Tipi di Backup & Strategie per SQL Database
- Articolo di TechNet la Clausola OVER
- Articolo di MSDN Su DENSE_RANK
Altri grandi articoli da Ben
Come SQL Server consente di selezionare un deadlock
Come Utilizzare le Funzioni Finestra
- Autore
- Post Recenti
Visualizza tutti i post di Ben Richardson
- Power BI: Waterfall Charts and Combined Visuals – January 19, 2021
- Potenza BI: Formattazione condizionale e colori dei dati in azione-14 gennaio 2021
- Power BI: importazione di dati da SQL Server e MySQL – 12 gennaio 2021