顔認識—ステップバイステップ
この問題に一度に一歩ずつ取り組んでみましょう。 各ステップについて、異なる機械学習アルゴリズムについて学習します。 これが本にならないようにすべてのアルゴリズムを完全に説明するつもりはありませんが、それぞれの背後にある主なアイデアを学び、OpenFaceとdlibを使ステップ1
ステップ2
ステップ3: すべての顔を見つける
パイプラインの最初のステップは顔検出です。 明らかに私達は私達がそれらを離れて言うことを試みることができる前に写真の表面を見つける必要がある!あなたが過去10年間に任意のカメラを使用している場合は、おそらくアクションで顔検出を見てきました:

顔検出は、カメラのための素晴らしい機能です。 カメラが自動的に顔を選ぶことができるとき、それは写真を撮る前にすべての顔が焦点にあることを確認することができます。 しかし、私たちは別の目的のためにそれを使用します—私たちは私たちのパイプラインの次のステップに渡したい画像の領域を見つけます。
顔検出は、Paul ViolaとMichael Jonesが安価なカメラで実行するのに十分な速さの顔を検出する方法を発明した2000年代初頭に主流になりました。 しかし、はるかに信頼性の高い解決策が現在存在しています。 私たちは2005年に発明されたHistogram of Oriented Gradientsと呼ばれる方法を使用します。
画像内の顔を見つけるには、顔を見つけるためにカラーデータが必要ないため、画像を白黒にすることから始めます。

次に、画像内のすべてのピクセルを一度に1つずつ見ていきます。 すべての単一のピクセルについて、私たちはそれを直接囲むピクセルを見たいと思います:/div>現在のピクセルが直接それを囲むピクセルと比較されるどのように暗いうち。 次に、画像がどの方向に暗くなっているかを示す矢印を描画します:p>

画像内のすべてのピクセルに対してそのプロセスを繰り返すと、すべてのピクセルが矢印に置き換えられます。 これらの矢印はグラデーションと呼ばれ、画像全体の光から闇への流れを示します:/div>行うにはランダムなことが、グラデーションでピクセルを交換するための本当に良い理由があります。 ピクセルを直接分析すると、同じ人の本当に暗い画像と本当に明るい画像は全く異なるピクセル値を持ちます。 しかし、明るさが変化する方向だけを考慮することによって、本当に暗い画像と本当に明るい画像の両方が同じ正確な表現になります。 それは問題を解決するのがずっと簡単になります!
しかし、すべての単一のピクセルの勾配を保存すると、あまりにも多くの詳細が得られます。 私たちは木のために森を失ってしまいます。 画像の基本的なパターンを見ることができるように、明るさ/暗さの基本的な流れをより高いレベルで見ることができれば良いでしょう。
これを行うには、画像をそれぞれ16×16ピクセルの小さな正方形に分割します。 各正方形では、各主要な方向を指す勾配の数を数えます(上の点、上の点、右の点など)。 次に、画像内のその正方形を最強の矢印方向に置き換えます。最終的な結果は、元の画像を簡単な方法で顔の基本的な構造をキャプチャする非常に単純な表現に変換することです。

この手法を使用すると、任意の画像で顔を簡単に見つけることができます:/div>ここでは、画像のHOG表現を生成して表示する方法を示すコードを示します。
ステップ2:ポーズと顔を投影
Whew、私たちは私たちの画像内の顔を分離しました。 しかし、今、私たちは直面している問題に対処する必要があります別の方向は、コンピュータに全く異なって見える:P>

これを説明するために、目と唇が常に画像内のサンプルの場所になるように、各画像をワープしようとします。 これにより、次のステップで顔を比較するのがはるかに簡単になります。これを行うには、顔のランドマーク推定と呼ばれるアルゴリズムを使用します。
これを行うには、顔のランドマーク推定と呼ばれるアルゴ これを行う方法はたくさんありますが、2014年にVahid KazemiとJosephine Sullivanによって発明されたアプローチを使用します。
基本的な考え方は、顎の上部、各目の外側の端、各眉の内側の端など、すべての顔に存在する68の特定の点(ランドマークと呼ばれる)を考え出すことです。 次に、機械学習アルゴリズムを訓練して、これらの68個の特定の点を任意の面で見つけることができます:


目と口があることがわかったので、目と口ができるだけ中央に配置されるように、画像を回転、スケール、せん断するだけです。 それは画像に歪みを導入するので、私たちは、任意の空想の3dワープを行いません。 平行線を保持する回転やスケールのような基本的な画像変換(アフィン変換と呼ばれます)のみを使用します:/div>顔を回して、画像内でほぼ同じ位置にある目と口を中心にすることができます。 これにより、次のステップがより正確になります。Pythonとdlibを使用してこのステップを自分で試してみたい場合は、顔のランドマークを見つけるためのコードと、それらのランドマークを使用して画像を変換するためのコードを次に示します。ステップ3
ステップ3
ステップ3: Encoding Faces
今、私たちは問題の肉にあります—実際には顔を離れて伝えます。 これは物事が本当に面白くなる場所です!
顔認識の最も簡単なアプローチは、ステップ2で見つかった未知の顔を、すでにタグ付けされている人のすべての写真と直接比較することです。 私たちの未知の顔に非常によく似ている以前にタグ付けされた顔を見つけたとき、それは同じ人でなければなりません。 かなり良いアイデアのように思えますよね?
実際にはそのアプローチには大きな問題があります。 数十億人のユーザーと1兆枚の写真を持つFacebookのようなサイトは、以前のタグ付けされたすべての顔をループして、新しくアップロードされたすべての画像 それは時間がかかりすぎるだろう。 彼らは数時間ではなく、ミリ秒単位で顔を認識できる必要があります。私たちが必要とするのは、各面からいくつかの基本的な測定値を抽出する方法です。
私たちが必要とするのは、それぞれの面からいくつかの 次に、未知の顔を同じ方法で測定し、最も近い測定値で既知の顔を見つけることができます。 たとえば、各耳のサイズ、目の間隔、鼻の長さなどを測定することができます。 あなたがCSIのような悪い犯罪ショーを見たことがあるなら、あなたは私が話していることを知っています:
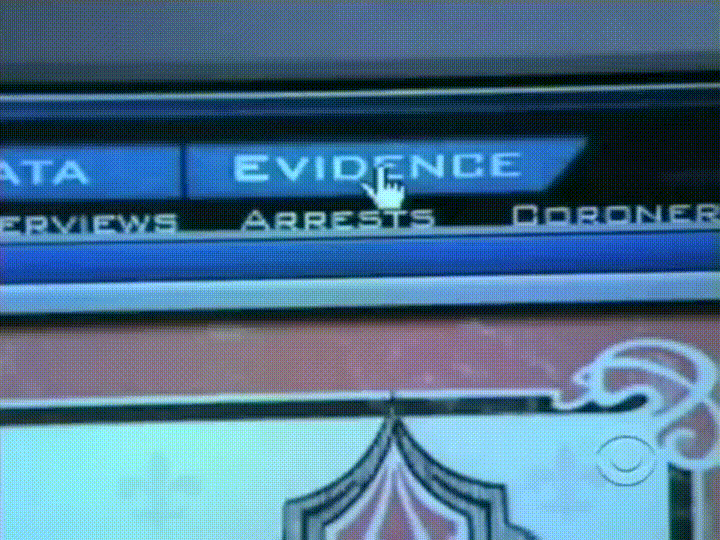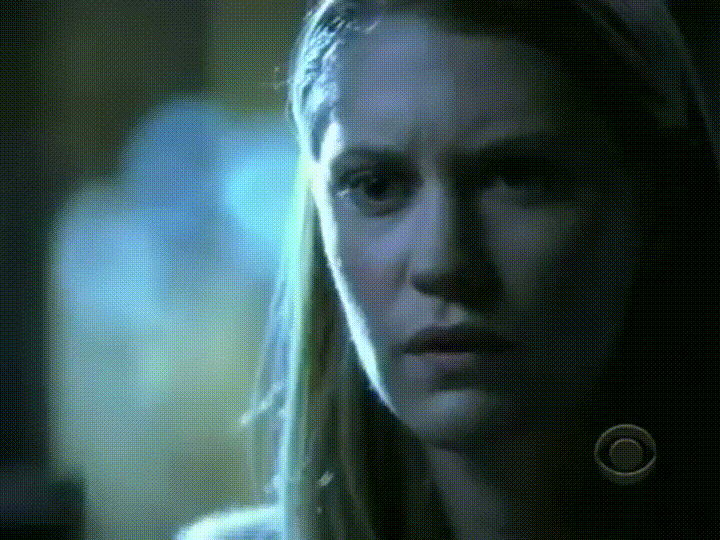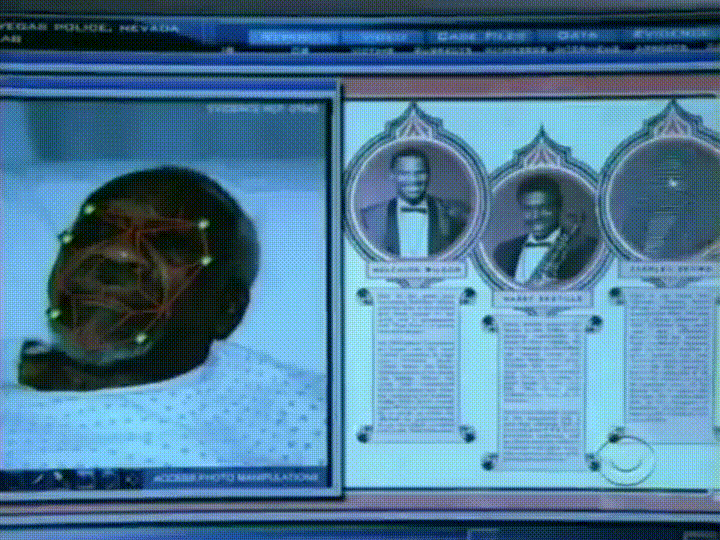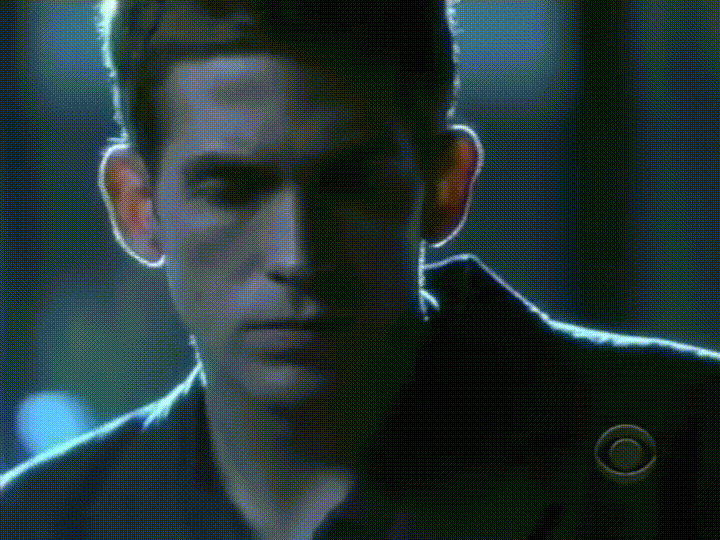
顔を測定する最も信頼性の高い方法
さて、既知の顔データベースを構築するために各顔からどの測定値を収集すべきですか? 耳のサイズか。 鼻の長さか。 目の色? 他に何か?
私たち人間には明らかに見える測定値(目の色など)は、画像内の個々のピクセルを見ているコンピュータにとっては実際には意味がありません。 研究者は、最も正確なアプローチは、コンピュータが自分自身を収集するための測定値を把握できるようにすることであることを発見しました。 ディープラーニングは、顔のどの部分が測定することが重要であるかを把握する上で、人間よりも優れた仕事をします。解決策は、深い畳み込みニューラルネットワークを訓練することです(パート3で行ったように)。 しかし、前回のように画像オブジェクトを認識するようにネットワークを訓練するのではなく、各顔に対して128の測定値を生成するように訓練します。
トレーニングプロセスは、一度に3つの顔画像を見ることによって動作します。
- 既知の人のトレーニング顔画像をロード
- 同じ既知の人の別の画像をロード
- 全く別の人の画像をロード
次に、アルゴリズムは、現在生成されている測定値を調べます。これらの三つの画像のそれぞれについて。 次に、ニューラルネットワークを少し微調整して、#1と#2の測定値がわずかに近く、#2と#3の測定値がわずかに離れていることを確認します。

このステップを何百万もの異なる人々の何百万もの画像に対して何百万回も繰り返した後、ニューラルネットワークは各人に128の測定値を確実に生成することを学習します。 同じ人の任意の10の異なる写真は、ほぼ同じ測定値を与える必要があります。機械学習の人々は、それぞれの顔の128の測定値を埋め込みと呼びます。 画像のような複雑な生データをコンピュータで生成された数字のリストに減らすという考えは、機械学習(特に言語翻訳)で多くのことが起こります。 私たちが使用している顔の正確なアプローチは、Googleの研究者によって2015年に発明されましたが、多くの同様のアプローチが存在します。
顔画像をエンコードする
顔埋め込みを出力するために畳み込みニューラルネットワークを訓練するこのプロセスには、多くのデータとコンピュー 高価なNVidia Telsaビデオカードを使用しても、良好な精度を得るには約24時間の継続的なトレーニングが必要です。
しかし、ネットワークが訓練されると、それはそれが前に見たことがないものであっても、任意の顔の測定値を生成することができます!
したがって、この手順は一度だけ実行する必要があります。 私たちにとって幸運なことに、OpenFaceの素晴らしい人々はすでにこれを行い、彼らは私たちが直接使用できるいくつかの訓練されたネットワー ありがとうBrandon Amosとチーム!
だから、私たちは自分自身を行う必要があるのは、各顔のための128の測定値を取得するために彼らの事前に訓練されたネットワークを介して私た この測定実験のイメージ:

この顔にはこれらの128番号を測定すね! それは我々が見当がつかないことが判明しました。 それは私達に実際に問題ではない。 私たちが気にしているのは、同じ人の2つの異なる写真を見ると、ネットワークがほぼ同じ数字を生成することです。このステップを自分で試してみたい場合は、OpenFaceは、フォルダ内のすべての画像を埋め込み生成し、csvファイルに書き込むluaスクリプトを提供します。 あなたはこのようにそれを実行します。
ステップ4:エンコーディングから人の名前を見つける
この最後のステップは、実際にはプロセス全体で最も簡単なステップです。 私たちがしなければならないのは、私たちのテストイメージに最も近い測定値を持っている既知の人々の私達のデータベースで人を見つけることです。これは、基本的な機械学習分類アルゴリズムを使用して行うことができます。
派手な深い学習のトリックは必要ありません。 単純な線形SVM分類器を使用しますが、多くの分類アルゴリズムが機能する可能性があります。私たちがする必要があるのは、新しいテスト画像から測定値を取得し、どの既知の人物が最も近い一致であるかを伝える分類子を訓練することだ。
この分類子の実行にはミリ秒かかります。 分類子の結果は人の名前です!
それでは、私たちのシステムを試してみましょう。 まず、Will Ferrell、Chad Smith、Jimmy Falonのそれぞれ約20枚の写真を埋め込み、分類器を訓練しました。