
このチュートリアルでは、ロジスティック回帰を学びます。 ここでは、ロジスティック回帰が正確に何であるかを知ることができますし、Pythonの例も表示されます。 ロジスティック回帰は機械学習の重要なトピックであり、私はそれをできるだけ簡単にしようとします。
二十世紀初頭には、ロジスティック回帰は、主にこの後、生物学で使用された、それはいくつかの社会科学のアプリケーションで使用されました。 興味がある場合は、ロジスティック回帰をどこで使用すべきかを尋ねることができますか? したがって、独立変数がカテゴリカルな場合はロジスティック回帰を使用します。
例:
- 人が車を購入するかどうかを予測するには(1)または(0)
- 腫瘍が悪性であるかどうかを知るには(1)または(0)
ここで、人が車を購入するかどうかを分類しなければならないシナリオを考えてみましょう。 この場合、単純な線形回帰を使用する場合は、分類を行うことができるしきい値を指定する必要があります。
実際のクラスは、人が車を購入し、予測された連続値は0.45であり、我々が考慮したしきい値は0であるとしましょう。
実際のクラスは、人が車を購入人は車を購入しませんし、これは間違った予測につながるように5、その後、このデータポイントが考慮されます。したがって、このタイプの分類問題には線形回帰を使用することはできないと結論づけています。
線形回帰は有界であることがわかっているので、ここでは値が厳密に0から1の範囲のロジスティック回帰があります。
単純ロジスティック回帰:
出力:0または1
仮説:K=W*X+B
h λ(x)=sigmoid(K)
Sigmoid関数:


ロジスティック回帰の種類:
バイナリロジスティック回帰
2つの可能な結果(カテゴリ)のみ。
例:人は車を購入するかどうか。
多項ロジスティック回帰
順序なしで可能な二つ以上のカテゴリ。
順序ロジスティック回帰
順序付けで可能な二つ以上のカテゴリ。
Pythonを使用した実世界の例:
ここで、ロジスティック回帰で実世界の問題を解決します。 ユーザー ID、性別、年齢、EstimatedSalary、およびPurchasedの5つの列を持つデータセットがあります。 今度は、与えられたパラメータで人が車を買うかどうかを予測できるモデルを構築する必要があります。
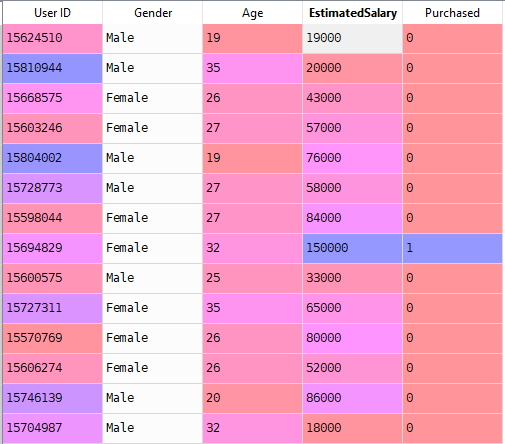
モデルを構築する手順: h2>
1. Importing the libraries
ここでは、モデルを構築するために必要なライブラリをインポートします。p>
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
pandasを使用して変数(つまりデータセット)にデータセットをインポートします。P>
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
私たちのデータセットでは、独立変数としての年齢と推定値と従属変数としての購入値。ここで、Xは独立変数であり、yは従属変数です。P>
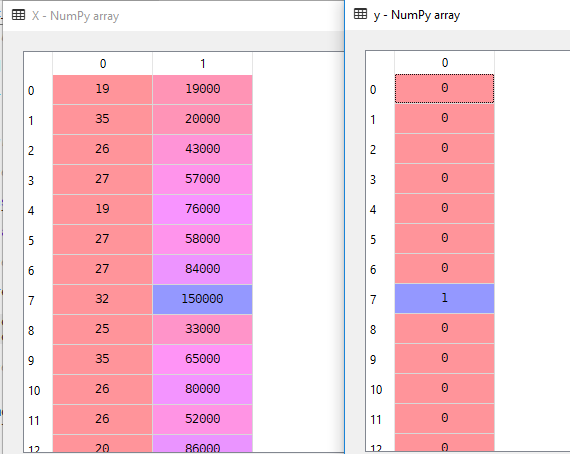
3. Splitting the Data set into the Training Set and Test Set
データセットをトレーニングデータとテストデータに分割します。 トレーニングデータは
ロジスティックモデルのトレーニングに使用され、テストデータはモデルの検証に使用されます。 Sklearnを使用してデータを分割します。 Sklearnからtrain_test_splitをインポートします。model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
今、私たちは、機能のスケーリングを行いますより良い精度を得るために0と1の間でデータをスケーリングします。
年齢と推定の間に大きな違いがあるので、ここでスケーリングが重要です。
- sklearnからStandardScalerをインポートします。前処理
- 次に、オブジェクトStandardScalerのインスタンスsc_xを作成します
- 次に、x_Trainをフィットして変換し、x_Testを変換します
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
今、私たちは私たちの分類器(ロジスティック)を構築します。
- SklearnからLogisticRegressionをインポートします。linear_model
- オブジェクトLogisticRegressionのインスタンス分類子を作成し、毎回同じ結果を得るために
random_state=0を与えます。この分類子を使用してX_Trainとy_trainに合わせます
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)乾杯!! 上記のコマンドを実行した後、人が車を購入するかどうかを予測できる分類子があります。ここで、分類器を使用してテストデータセットの予測を行い、混同行列を使用して精度を見つけます。
次に、分類器を使用してテストデータセットの予P>
6. Predicting the Test set results
y_pred = classifier.predict(X_test)今、私たちはy_predを取得します

これで、y_test(実際の結果)とy_pred(予測結果)を使用してモデルの精度を得ることができます。
7. Making the Confusion Matrix
混乱行列を使用して、モデルの精度を得ることができます。p>
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)行列cmを取得します。p>

以下に示すように、cmを使用して精度を計算します:P>
精度=(cm+cm)/(総テストデータポイント)

ここでは、89%の精度を取得しています。 乾杯!! 我々は良い精度を得ています。
最後に、トレーニングセットの結果とテストセットの結果を視覚化します。 Matplotlibを使用してデータセットをプロットします。P>
トレーニングセットの結果を視覚化する
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()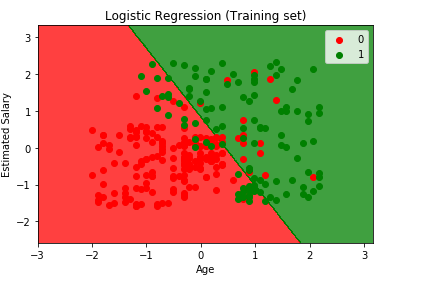
テストセットの結果を視覚化する
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()テストセットの結果を視覚化する
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
ロジスティック回帰のための独自の分類器を構築することができます。
ありがとう!! コーディングを続けろ!!注:これはゲストの投稿であり、この記事の意見はゲストライターのものです。 あなたはwwwで投稿された記事のいずれかに問題がある場合。marktechpost.com please contact at [email protected]
Advertisement
