Pythonの正規表現とは何ですか?
プログラミング言語の正規表現(RE)は、検索パターンを記述するために使用される特別なテキスト文字列です。 これは、コード、ファイル、ログ、スプレッドシート、あるいは文書などのテキストから情報を抽出するために非常に便利です。
Pythonの正規表現を使用している間、最初に認識することは、すべてが本質的に文字であり、文字列とも呼ばれる特定の文字シーケンスに一致するパター Asciiまたはラテン文字は、キーボード上にあるものであり、Unicodeは、外国のテキストと一致するために使用されます。 これには、数字と句読点、および$#@のようなすべての特殊文字が含まれています!%など
このPython正規表現チュートリアルでは、次のことを学びます-
- 正規表現構文
- w+と^式の例
- reの\s式の例。分割関数
- 正規表現メソッドを使用して
- reを使用して。match()
- テキスト内のパターンの検索(re.search())
- reを使用しています。テキストのfindall
- Python Flags
- reの例。Mまたは複数行のフラグ
たとえば、Pythonの正規表現は、文字列から特定のテキストを検索し、それに応じて結果を出力するようにプログラムに指示 式には、
- テキストマッチング
- 繰り返し
- 分岐
- パターン構成などを含めることができます。Pythonの正規表現または正規表現は、REモジュールを介してインポートされるRE(REs、正規表現または正規表現パターン)として示されています。 Pythonはライブラリを介した正規表現をサポートしています。 Pythonの正規表現は、修飾子、識別子、空白文字などのさまざまなものをサポートしています。 Th>
修飾子 空白文字 エスケープが必要 \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=任意の数字(数字) \d=td> \dは数字を表します。Ex: \d{1,5}424,444,545などのように1,5の間の数字を宣言します。 \n=新しい行 。 + * ? $ ^ () {} | \ \s=スペース(タブ、スペース、改行など) \s=スペース(タブ、スペース、改行など) \s=スペース(タブ、スペース、改行など) \s=スペース(タブ、スペース、改行など) \s=スペース(タブ、スペース、改行など) \s=スペース(タブ、スペース、改行など)td> = matches 0 or 1 \t =tab \S= anything but a space * = 0 or more \e = escape \w = letters ( Match alphanumeric character, including “_”) $ match end of a string \r = carriage return \W =anything but letters ( Matches a non-alphanumeric character excluding “_”) ^ match start of a string \f= form feed . = anything but letters (periods) | matches either or x/y —————– \b = any character except for new line = range or “variance” —————- \. {x}=前のコードのこの量 —————–
正規表現(RE)構文
import re
- “re”モジュールは、主に文字列の検索や操作に使用されるPythonに含まれています
- また、webページ”スクレイピング”(ウ式のチュートリアルでは、式(w+)と式(^)を使用して、この簡単な演習を開始します。
w+と^の式の例
- “^”: この式は文字列の先頭と一致します
- “w+”:この式は文字列の英数字と一致します
ここでは、コード内でw+と^式を使用する方法のPython正規表現の例を見 私たちは、機能reをカバーしています.Pythonでのfindall()は、このチュートリアルの後半ですが、しばらくの間、単に\w+と\^expressionに焦点を当てます。 たとえば、文字列”guru99,education is fun”の場合、w+と^を使用してコードを実行すると、”guru99″という出力が得られます。
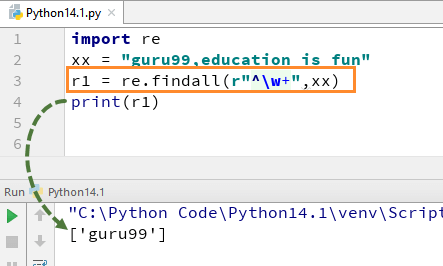
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print(r1)
W+から+記号を削除すると、出力が変更され、最初の文字の最初の文字、つまり
reの\s式の例が表示されます。split function
- “s”:この式は文字列にスペースを作成するために使用されます
Pythonでこの正規表現がどのように機能するかを理解するために、単純なPython この例では、”re”を使用して各単語を分割しました。split”関数を使用すると同時に、文字列内の各単語を個別に解析できるexpression\sを使用しました。

このコードを実行すると、出力が得られます。 これは、文字列から’\’を削除し、”s”を通常の文字として評価し、文字列内で”s”が見つかった場所で単語を分割するためです。
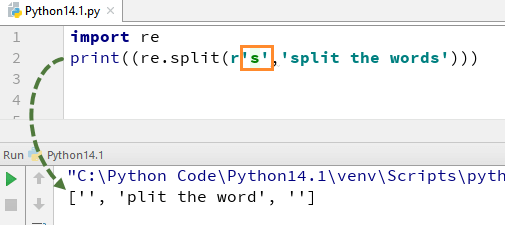
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print((re.split(r'\s','we are splitting the words')))print((re.split(r's','split the words')))
次に、我々はPythonで正規表現で使用されているメソッドの種類を見ていきます。
正規表現メソッドの使用
“re”パッケージは、入力文字列に対して実際にクエリを実行するためのいくつかのメソッドを提供します。 Pythonでreのメソッドが表示されます:
- re。match()
- re.検索()
- re.Findall()
注:正規表現に基づいて、Pythonは二つの異なるプリミティブ演算を提供しています。 Matchメソッドは、文字列の先頭にのみ一致をチェックし、searchは文字列内の任意の場所に一致するかどうかをチェックします。
再。match()
re.Pythonのreのmatch()関数は、正規表現パターンを検索し、最初の出現を返します。 PythonのRegEx Matchメソッドは、文字列の先頭でのみ一致をチェックします。 したがって、最初の行に一致するものが見つかった場合は、matchオブジェクトを返します。 しかし、他の行に一致するものが見つかった場合、Pythonの正規表現一致関数はnullを返します。 たとえば、次のPython reのコードを考えてみましょう。match()関数。 式”w+”と”\W”は文字’g’で始まる単語と一致し、それ以降は’g’で始まらないものは識別されません。”w+”と”\W”は文字’g’で始まる単語と一致します。”w+”と”\W”は文字’g’ リストまたは文字列内の各要素の一致を確認するには、このPython reでforloopを実行します。マッチ()の例。

re。search():テキスト内のパターンを見つける
re.search()関数は、正規表現パターンを検索し、最初の出現を返します。 Python reとは異なります。match()、それは入力文字列のすべての行をチェックします。 パイソンの再.search()関数は、パターンが見つかったときに一致オブジェクトを返し、パターンが見つからない場合は”null”を返します
search()関数を使用するには、最初にPython reモジュー パイソンの再.search()関数は、私たちのメイン文字列からスキャンするために”パターン”と”テキスト”を取ります
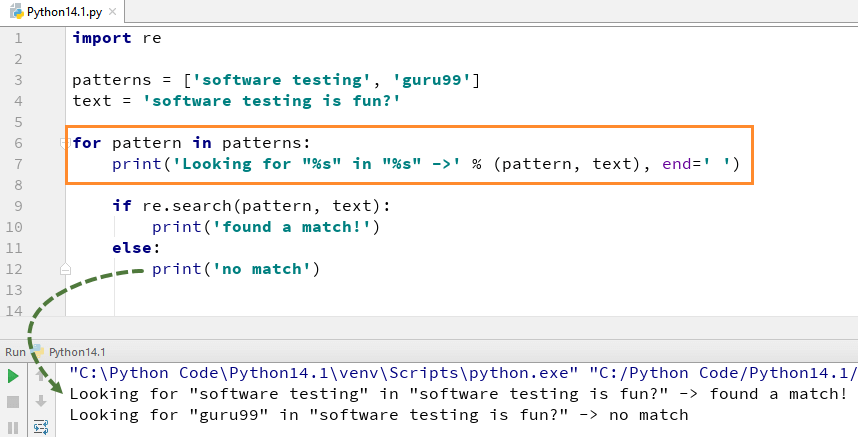
たとえば、ここでは、”Software Testing””guru99″という2つのリテラル文字列をテキスト文字列”Software Testing is fun”で探します。 「ソフトウェアテスト」では、一致が見つかったため、Python reの出力が返されます。search()の例は”found a match”ですが、単語”guru99″の場合は文字列で見つかりませんでしたので、出力は”no match”として返されます。
再。findall()
findall()モジュールは、指定されたパターンに一致する”すべて”の出現を検索するために使用されます。 これとは対照的に、search()モジュールは、指定されたパターンに一致する最初の出現のみを返します。 findall()はファイルのすべての行を反復処理し、単一のステップでパターンの重複しないすべての一致を返します。 たとえば、ここでは電子メールアドレスのリストがあり、すべての電子メールアドレスをリストから取得したい場合は、reメソッドを使用します。Pythonでのfindall()。 これは、リストからすべての電子メールアドレスを検索します。
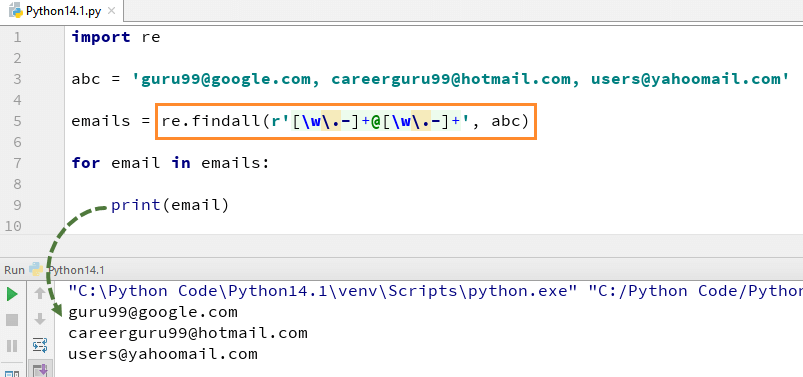
ここでは、reの例の完全なコードです。findall()
import relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print((z.groups())) patterns = text = 'software testing is fun?'for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!')else: print('no match')abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print(email)Python Flags
多くのPython正規表現メソッドと正規表現関数はFlagsと呼ばれるオプションの引数を取ります。 このフラグは、指定されたPython正規表現パターンの意味を変更することができます。 これらを理解するために、これらのフラグの1つまたは2つの例が表示されます。
Various flags used in Python includes
Syntax for Regex Flags What does this flag do Make begin/end consider each line It ignores case Make Make { \w,\W,\b,\B} follows Unicode rules Make {\w,\W,\b,\B} follow locale Allow comment in Regex Example of re.Mまたは複数行フラグ
複数行では、パターン文字は文字列の最初の文字と各行の先頭(各改行の直後)に一致します。 式small”w”はスペースを文字でマークするために使用されます。 コードを実行すると、最初の変数”k1″は単語guru99の文字’g’のみを出力しますが、複数行フラグを追加すると、文字列内のすべての要素の最初の文字をフェッ
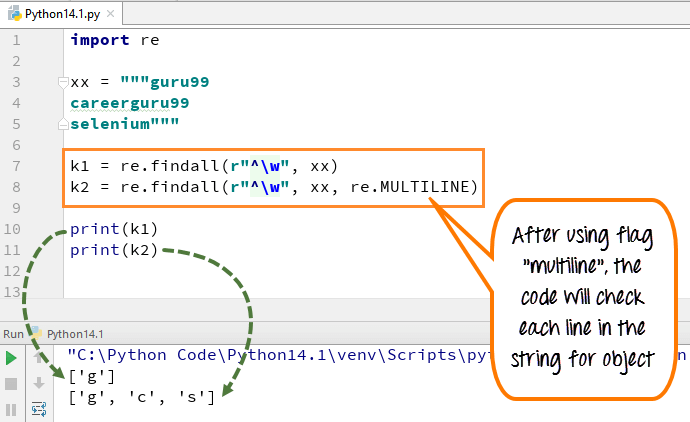
import rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print(k1)print(k2)
- 文字列”guru99….”の変数xxを宣言しました。 キャレル99………..複数行のフラグを使用せずにコードを実行すると、行から’g’だけが出力されます
- フラグ”multiline”でコードを実行します。’k2’を印刷すると、’g’、’c’、’s’として出力されます
- だから、上記の例では複数行を追加した後と前に見ることができます。同様に、reのような他のPythonフラグを使用することもできます。U(Unicode),re.L(ロケールに従ってください)、re。X(コメントを許可する)など 上記のコードはPython3の例ですが、Python2で実行したい場合は、次のコードを検討してください。
# Example of w+ and ^ Expressionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print r1# Example of \s expression in re.split functionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print (re.split(r'\s','we are splitting the words'))print (re.split(r's','split the words'))# Using re.findall for textimport relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print(z.groups()) patterns = text = 'software testing is fun?'for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!'else: print 'no match'abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print email# Example of re.M or Multiline Flagsimport rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print k1print k2概要
プログラミング言語の正規表現は、検索パターンを記述するために使用される特別なテキスト文字列です。 これには、数字と句読点、および$#@のようなすべての特殊文字が含まれています!%など 式には、リテラル
- テキストマッチング
- 繰り返し
- 分岐
- パターン構成などを含めることができます。
Pythonでは、正規表現は、RE(REs、正規表現または正規表現パターン)は、Pythonのreモジュールを介して埋め込まれているとして示されています。
- “re”モジュールは、主に文字列の検索と操作のために使用されるPythonに含まれています
- また、webページ”スクレイピング”(ウェブサイトから大量のデータを抽出)
- 正規表現の方法は、reが含まれています。マッチ(),re.search()&re.findall()
- 他のPython RegEx replaceメソッドは、reで一致する文字列を置き換えるために使用されるsub()とsubn()です
- Python Flags多くのPython RegexメソッドとRegex関数はFlagsと呼ばれるオプショM、再…私は、再。Sなど