
In deze tutorial leer Je Logistische Regressie. Hier Weet je precies wat logistieke regressie is en zie je ook een voorbeeld met Python. Logistieke regressie is een belangrijk onderwerp van Machine Learning en Ik zal proberen om het zo eenvoudig mogelijk te maken.
in het begin van de twintigste eeuw werd logistische regressie vooral gebruikt in de biologie, daarna werd het gebruikt in sommige toepassingen in de sociale wetenschappen. Als je nieuwsgierig bent, kun je je afvragen waar we logistieke regressie moeten gebruiken? We gebruiken logistische regressie als onze onafhankelijke variabele categorisch is.
voorbeelden:
- om te voorspellen of een persoon een auto zal kopen (1) of (0)
- om te weten of de tumor kwaadaardig is (1) of (0)
laten we nu een scenario overwegen waarin u moet classificeren of een persoon een auto zal kopen of niet. In dit geval, als we eenvoudige lineaire regressie gebruiken, moeten we een drempel specificeren waarop classificatie kan worden gedaan.
laten we zeggen dat de werkelijke klasse is de persoon zal de auto te kopen, en voorspelde continue waarde is 0,45 en de drempel die we hebben overwogen is 0.5, dan zal dit gegevenspunt worden beschouwd als de persoon de auto niet zal kopen en dit zal leiden tot de verkeerde voorspelling.
dus we concluderen dat we geen lineaire regressie kunnen gebruiken voor dit type classificatieprobleem. Zoals we weten is lineaire regressie Begrensd, dus hier komt logistieke regressie waar de waarde strikt varieert van 0 tot 1.
eenvoudige logistische regressie:
Uitgang: 0 of 1
hypothese: K = W * X + B
hΘ(x) = sigmoid (K)
Sigmoid functie:


typen logistische regressie:
binaire logistische regressie
slechts twee mogelijke uitkomsten(Categorie).
voorbeeld: de persoon zal een auto kopen of niet.
multinomiale logistische regressie
meer dan twee categorieën mogelijk zonder bestelling.
ordinale logistische regressie
meer dan twee categorieën mogelijk met volgorde.
real-world voorbeeld met Python:
nu lossen we een real-world probleem op met logistieke regressie. We hebben een dataset met 5 kolommen namelijk: User ID, geslacht, leeftijd, geschatte Salary en gekocht. Nu moeten we een model bouwen dat kan voorspellen of op de gegeven parameter een persoon een auto zal kopen of niet.
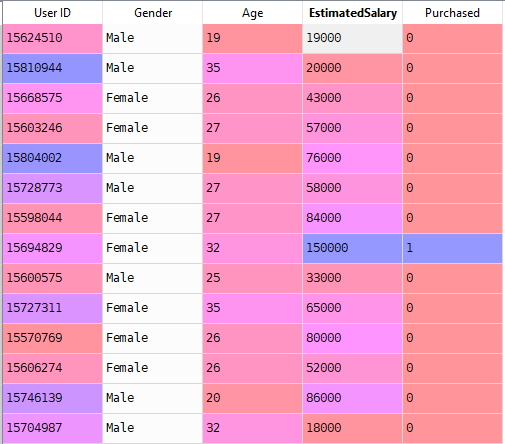
stappen om het Model te bouwen:
1. Importing the libraries
Hier zullen we bibliotheken importeren die nodig zijn om het model te bouwen.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
We zullen onze gegevensverzameling importeren in een variabele (dat wil zeggen dataset) met behulp van Panda ‘ s.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
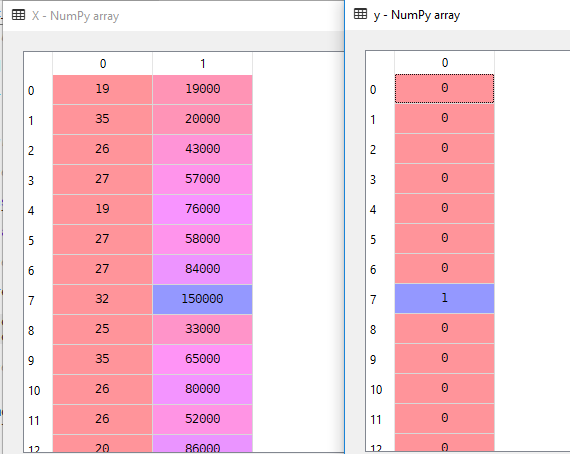
geschatte salary als onafhankelijke variabele en aangekocht als afhankelijke variabele.
X = dataset.iloc].valuesy = dataset.iloc.valuesHier is X onafhankelijke variabele en y is afhankelijke variabele.
3. Splitting the Data set into the Training Set and Test Set
nu splitsen we onze dataset op in trainingsgegevens en testgegevens. Trainingsgegevens zullen worden gebruikt om ons logistieke model te trainen en testgegevens zullen worden gebruikt om ons model te valideren. We gebruiken Sklearn om onze gegevens te splitsen. We importeren train_test_split van sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
schalen om onze gegevens tussen 0 en 1 te schalen voor een betere nauwkeurigheid.
hier is schalen belangrijk omdat er een enorm verschil is tussen leeftijd en Geschatte Salay.
- Importeer StandardScaler uit sklearn.preprocessing
- maak Vervolgens een exemplaar sc_X van het object StandardScaler
- Vervolgens passen en te transformeren X_train en transformeren X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Nu we bouwen onze classifier (Logistieke).
- Logisticregressie importeren vanuit sklearn.linear_model
- Maak een instantie classifier van het object LogisticRegression en geef
random_state = 0 om telkens hetzelfde resultaat te krijgen. - gebruik nu deze classifier om X_train en y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Cheers!! Na het uitvoeren van het bovenstaande commando heb je een classifier die kan voorspellen of een persoon een auto zal kopen of niet.
Gebruik nu de classifier om de voorspelling voor de testgegevensreeks te maken en de nauwkeurigheid te vinden met behulp van Verwarmingsmatrix.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)nu krijgen we y_pred

nu kunnen we y_test (actual result) en y_pred ( predicted result) gebruiken om de nauwkeurigheid van ons model te krijgen.
7. Making the Confusion Matrix
met behulp van Verwarmingsmatrix kunnen we de nauwkeurigheid van ons model verkrijgen.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)u krijgt een matrix cm.

gebruik cm om de nauwkeurigheid te berekenen zoals hieronder getoond:
nauwkeurigheid = ( cm + cm) /(Totale testgegevenspunten)

hier krijgen we een nauwkeurigheid van 89 % . Proost!! we krijgen een goede nauwkeurigheid.
ten slotte visualiseren we het resultaat van de trainingsset en het resultaat van de testset. We gebruiken matplotlib om onze dataset te plotten.
het Visualiseren van de Training Set resultaat
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()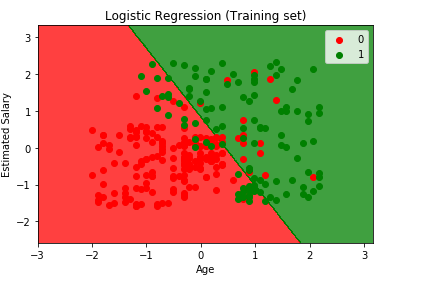
het Visualiseren van de Test Set resultaat
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Nu kunt U het bouwen van uw eigen indeler voor de Logistieke Regressie.
bedankt!! Blijf Coderen !!
Opmerking: Dit is een gastpost, en de mening in dit artikel is van de gastschrijver. Als je problemen hebt met een van de artikelen geplaatst op www.marktechpost.com please contact at [email protected]
Advertisement
