gezichtsherkenning-stap voor stap
laten we dit probleem stap voor stap aanpakken. Voor elke stap leren we over een ander algoritme voor machine learning. Ik ga niet elk algoritme volledig uitleggen om te voorkomen dat dit een boek wordt, maar je leert de belangrijkste ideeën achter elk algoritme en je leert hoe je je eigen gezichtsherkenningssysteem in Python kunt bouwen met OpenFace en dlib.
Stap 1: Alle gezichten vinden
de eerste stap in onze pijplijn is gezichtsherkenning. Het is duidelijk dat we de gezichten op een foto moeten lokaliseren voordat we kunnen proberen ze uit elkaar te houden!
Als je hebt gebruikt een camera in de laatste 10 jaar, heb je waarschijnlijk gezien gezichtsherkenning in actie:

gezichts-detectie is een geweldige functie voor camera ‘ s. Wanneer de camera automatisch gezichten kan kiezen, kan hij ervoor zorgen dat alle gezichten in beeld zijn voordat hij de foto neemt. Maar we gebruiken het voor een ander doel — het vinden van de gebieden van het beeld die we willen doorgeven aan de volgende stap in onze pijplijn.in de vroege jaren 2000 vonden Paul Viola en Michael Jones een manier uit om gezichten te detecteren die snel genoeg was om op goedkope camera ‘ s te draaien. Er bestaan nu echter veel betrouwbaardere oplossingen. We gaan een methode gebruiken die in 2005 is uitgevonden, genaamd Histogram van georiënteerde gradiënten-of gewoon varkens in het kort.
om gezichten in een afbeelding te vinden, zullen we beginnen met onze afbeelding zwart-wit te maken omdat we geen kleurgegevens nodig hebben om gezichten te vinden:

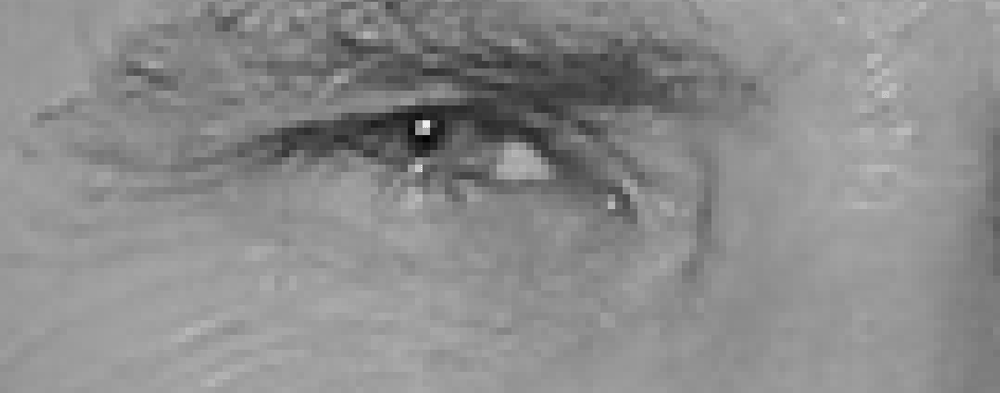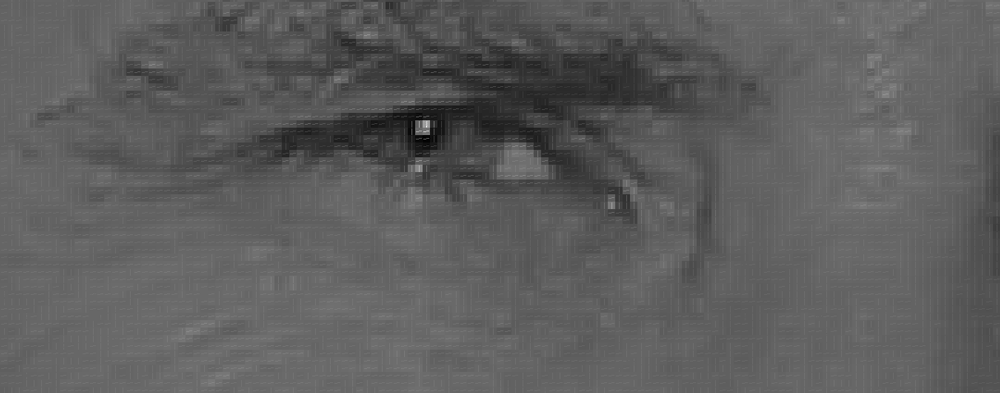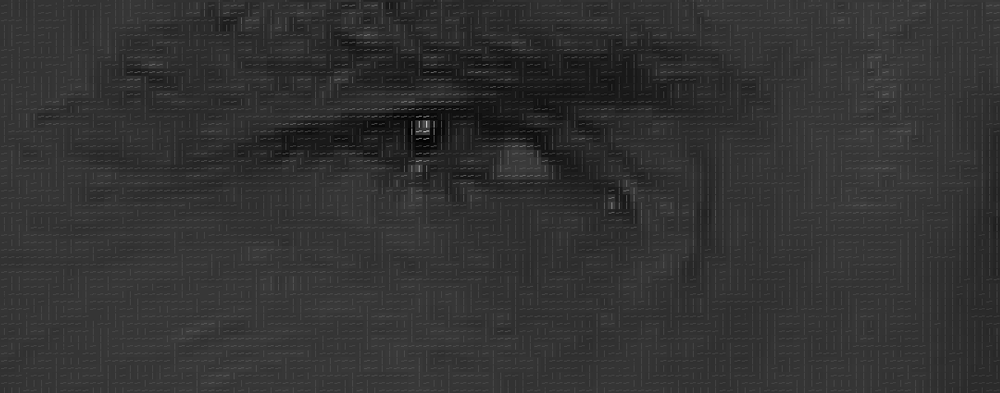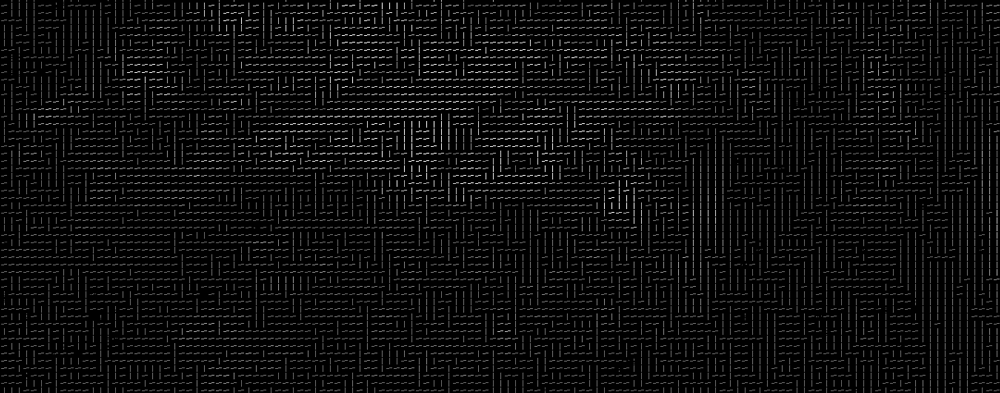
dan zullen we elke pixel in onze afbeelding één voor één bekijken. Voor elke pixel willen we kijken naar de pixels die er direct omheen staan:

ons doel is om erachter te komen hoe donker de huidige pixel is vergeleken met de pixels direct eromheen. Dan willen we een pijl tekenen die laat zien in welke richting de afbeelding donkerder wordt:

Als u dat proces voor elke pixel in de afbeelding herhaalt, wordt elke pixel vervangen door een pijl. Deze pijlen worden gradiënten genoemd en ze tonen de stroom van licht naar donker over de hele afbeelding:
Dit lijkt misschien willekeurig, maar er is een goede reden om de pixels te vervangen door kleurverlopen. Als we pixels direct analyseren, zullen echt donkere beelden en echt lichte beelden van dezelfde persoon totaal verschillende pixelwaarden hebben. Maar door alleen te kijken naar de richting waarin de helderheid verandert, zullen zowel echt donkere beelden als echt heldere beelden precies dezelfde representatie krijgen. Dat maakt het probleem een stuk makkelijker op te lossen!
maar het opslaan van het verloop voor elke pixel geeft ons veel te veel details. Uiteindelijk missen we het bos voor de bomen. Het zou beter zijn als we gewoon de basisstroom van lichtheid/duisternis op een hoger niveau konden zien zodat we het basispatroon van het beeld konden zien.
om dit te doen, splitsen we de afbeelding op in kleine vierkantjes van elk 16×16 pixels. In elk vierkant zullen we tellen hoeveel gradiënten punt in elke grote richting (hoeveel punt omhoog, punt omhoog-rechts, punt rechts, enz…). Dan vervangen we dat vierkant in de afbeelding door de pijlrichtingen die het sterkst waren.
Het eindresultaat is draaien we de originele afbeelding in een zeer eenvoudige voorstelling van zaken dat legt de basis structuur van een gezicht op een eenvoudige manier:

Te vinden gezichten in deze HOG beeld, alles wat we hoeven te doen is het vinden van dat deel van de afbeelding dat ziet er het meest lijkt op een bekend HOG patroon dat werd gewonnen uit een heleboel andere opleiding gezichten:

met Behulp van deze techniek, we kunnen nu gemakkelijk vinden gezichten in een foto:

Als u deze stap zelf wilt proberen met behulp van Python en dlib, dan is hier de code die laat zien hoe u HOG representaties van afbeeldingen kunt genereren en bekijken.
Stap 2: het poseren en projecteren van gezichten
Whew, we isoleerde de gezichten in ons beeld. Maar nu moeten we omgaan met het probleem dat gezichten die verschillende richtingen hebben gedraaid er totaal anders uitzien dan een computer:

om dit te verklaren, zullen we proberen om elke afbeelding zo te vervormen dat de ogen en lippen altijd op de monsterplaats in de afbeelding staan. Dit maakt het voor ons een stuk makkelijker om gezichten te vergelijken in de volgende stappen.
om dit te doen, gebruiken we een algoritme genaamd Face landmark estimation. Er zijn veel manieren om dit te doen, maar we gaan gebruik maken van de aanpak uitgevonden in 2014 door Vahid Kazemi en Josephine Sullivan.
het basisidee is dat we zullen komen met 68 specifieke punten (de zogenaamde oriëntatiepunten) die bestaan op elk gezicht — de bovenkant van de kin, de buitenrand van elk oog, de binnenrand van elke wenkbrauw, enz. Dan zullen we een machine learning algoritme trainen om deze 68 specifieke punten op elk gezicht te kunnen vinden:

Hier is het resultaat van het lokaliseren van de 68 gezichtswijzers op onze testafbeelding:

nu we weten waar de ogen en mond zijn, draaien, schalen en schuin het beeld zodat de ogen en mond zo goed mogelijk gecentreerd zijn. We zullen geen mooie 3d-vervormingen doen omdat dat vervormingen in het beeld zou introduceren. We gaan alleen basis beeldtransformaties gebruiken zoals rotatie en schaal die parallelle lijnen behouden (affiene transformaties genoemd):

nu maakt het niet uit hoe het gezicht wordt gedraaid, we zijn in staat om de ogen en de mond in ongeveer dezelfde positie in het beeld te centreren. Dit zal onze volgende stap veel nauwkeuriger maken.
als u deze stap zelf wilt proberen met behulp van Python en dlib, is hier de code voor het vinden van gezicht oriëntatiepunten en hier is de code voor het transformeren van de afbeelding met behulp van die oriëntatiepunten.
Stap 3: Encoding Faces
nu zijn we aan het vlees van het probleem — eigenlijk gezichten uit elkaar te vertellen. Dit is waar de dingen echt interessant worden!
De eenvoudigste benadering van gezichtsherkenning is om het onbekende gezicht dat we in Stap 2 vonden direct te vergelijken met alle foto ‘ s die we hebben van mensen die al getagd zijn. Als we een eerder gelabeld Gezicht vinden dat erg lijkt op ons onbekende gezicht, moet het dezelfde persoon zijn. Lijkt me een goed idee, toch?
Er is eigenlijk een groot probleem met die aanpak. Een site als Facebook met miljarden gebruikers en een biljoen foto ‘ s kan onmogelijk lus door elk vorig gelabeld gezicht om het te vergelijken met elke nieuw geüploade foto. Dat zou veel te lang duren. Ze moeten gezichten kunnen herkennen in milliseconden, niet in uren.
wat we nodig hebben is een manier om een paar basismetingen uit elk pijler te halen. Dan kunnen we ons onbekende gezicht op dezelfde manier meten en het bekende gezicht vinden met de dichtstbijzijnde metingen. Bijvoorbeeld, kunnen we meten de grootte van elk oor, de afstand tussen de ogen, de lengte van de neus, enz. Als u ooit een slechte misdaadshow zoals CSI hebt gezien, weet u waar ik het over heb:
de meest betrouwbare manier om een gezicht te meten
Ok, dus welke metingen moeten we van elk gezicht verzamelen om onze bekende gezichtdatabase te bouwen? Oormaat? Neuslengte? Oogkleur? Iets anders?
Het blijkt dat de metingen die voor ons mensen duidelijk lijken (zoals oogkleur) niet echt zinvol zijn voor een computer die naar individuele pixels in een afbeelding kijkt. Onderzoekers hebben ontdekt dat de meest nauwkeurige aanpak is om de computer erachter te laten komen van de metingen om zichzelf te verzamelen. Deep learning doet beter werk dan mensen in het uitzoeken welke delen van een gezicht belangrijk zijn om te meten.
de oplossing is om een diep Convolutioneel neuraal netwerk te trainen (net zoals we deden in Deel 3). Maar in plaats van het netwerk te trainen om foto ‘ s te herkennen zoals we de vorige keer deden, gaan we het trainen om 128 metingen te genereren voor elk gezicht.
het trainingsproces werkt door drie gezichtsopnamen tegelijk te bekijken:
- Laad een gezichtsopname van een bekende persoon
- Laad een ander beeld van dezelfde bekende persoon
- Laad een beeld van een totaal andere persoon
dan kijkt het algoritme naar de metingen die het momenteel genereert voor elk van deze drie afbeeldingen. Vervolgens verdraait het neurale netwerk een beetje zo dat het ervoor zorgt dat de metingen die het genereert voor #1 en #2 zijn iets dichter terwijl ervoor te zorgen dat de metingen voor de #2 en #3 zijn iets verder uit elkaar:

Na het herhalen van deze stap miljoenen keer miljoenen afbeeldingen van duizenden verschillende mensen, het neurale netwerk leert om op een betrouwbare manier genereren 128 metingen voor elke persoon. Elke tien verschillende foto ‘ s van dezelfde persoon moeten ongeveer dezelfde afmetingen geven.
Machine learning mensen noemen de 128 metingen van elk gezicht een inbedding. Het idee van het verminderen van ingewikkelde ruwe gegevens zoals een beeld in een lijst van computer-gegenereerde getallen komt veel in machine learning (vooral in taal vertaling). De exacte aanpak voor gezichten die we gebruiken werd uitgevonden in 2015 door onderzoekers van Google, maar veel soortgelijke benaderingen bestaan.
coderen van onze gezichtsafbeelding
Dit proces van het trainen van een convolutioneel neuraal netwerk om gezichtsinbeddingen uit te voeren vereist veel data en computerkracht. Zelfs met een dure NVIDIA Telsa videokaart, duurt het ongeveer 24 uur van continue training om een goede nauwkeurigheid te krijgen.
maar als het netwerk eenmaal is getraind, kan het metingen genereren voor elk gezicht, zelfs voor degenen die het nog nooit eerder heeft gezien! Dus deze stap hoeft maar één keer gedaan te worden. Gelukkig voor ons hebben de fijne mensen van OpenFace dit al gedaan en hebben ze verschillende getrainde netwerken gepubliceerd die we direct kunnen gebruiken. Bedankt Brandon Amos en team!
dus alles wat we zelf moeten doen is onze gezichtsafbeeldingen door hun vooraf getrainde netwerk laten lopen om de 128 metingen voor elk gezicht te krijgen. Hier zijn de metingen voor onze testafbeelding:

dus welke delen van het gezicht meten deze 128 getallen precies? Het blijkt dat we geen idee hebben. Het maakt ons niet uit. Het enige wat ons interesseert is dat het netwerk bijna dezelfde nummers genereert als we naar twee verschillende foto ‘ s van dezelfde persoon kijken.
Als u deze stap zelf wilt proberen, biedt OpenFace een Lua-script dat alle afbeeldingen in een map zal inbedden en naar een csv-bestand zal schrijven. Je doet het zo.
Stap 4: de naam van de persoon vinden uit de codering
Deze laatste stap is eigenlijk de makkelijkste stap in het hele proces. Het enige wat we moeten doen is de persoon in onze database vinden van bekende mensen die het dichtst bij ons testbeeld staan.
u kunt dit doen met behulp van elk standaard classificatie-algoritme voor machine learning. Er zijn geen fancy deep learning trucs nodig. We zullen een eenvoudige lineaire SVM classifier gebruiken, maar veel classificatiealgoritmen zouden kunnen werken.
alles wat we moeten doen is een classifier trainen die de metingen van een nieuwe testafbeelding kan opnemen en vertelt welke bekende persoon het dichtst overeenkomt. Het draaien van deze classifier duurt milliseconden. Het resultaat van de classifier is de naam van de persoon!
dus laten we ons systeem uitproberen. Eerst trainde ik een classifier met de inbeddingen van ongeveer 20 foto ‘ s van elk Will Ferrell, Chad Smith en Jimmy Falon: