
“Er zijn drie soorten leugens – leugens, verdomde leugens en statistiek.”- Benjamin Disraeli
statistische analyses zijn historisch gezien een vaste waarde geweest in de hightech en geavanceerde bedrijfsindustrieën, en vandaag de dag zijn ze belangrijker dan ooit. Met de opkomst van geavanceerde technologie en geglobaliseerde activiteiten, statistische analyses geven bedrijven inzicht in het oplossen van de extreme onzekerheden van de markt. Studies bevorderen geïnformeerde besluitvorming, gedegen oordelen en acties die worden uitgevoerd op basis van het gewicht van bewijsmateriaal, niet op basis van veronderstellingen.
omdat bedrijven vaak gedwongen worden een moeilijk te interpreteren marktroadmap te volgen, kunnen statistische methoden helpen bij de planning die nodig is om door een landschap te navigeren dat gevuld is met kuilen, valkuilen en vijandige concurrentie. Statistische studies kunnen ook helpen bij het op de markt brengen van goederen of diensten, en bij het begrijpen van elke doelmarkten unieke waarde drivers. In het digitale tijdperk worden deze mogelijkheden ALLEEN verder versterkt en benut door de implementatie van geavanceerde technologie en business intelligence software. Als dit allemaal waar is, wat is dan het probleem met statistieken?
eigenlijk is er geen probleem op zich – maar er kan zijn. Statistieken zijn berucht om hun vermogen en potentieel om te bestaan als misleidende en slechte gegevens.
Wat Is een misleidende statistiek?
misleidende statistieken zijn gewoon het misbruik – al dan niet doelgericht – van een numerieke gegevens. De resultaten geven een misleidende informatie aan de ontvanger, die dan iets verkeerd gelooft als hij of zij de fout niet opmerkt of niet het volledige gegevensbeeld heeft.
gezien het belang van gegevens in de snel evoluerende digitale wereld van vandaag, is het belangrijk om vertrouwd te zijn met de basisprincipes van misleidende statistieken en toezicht. Als een oefening in due diligence, zullen we een aantal van de meest voorkomende vormen van misbruik van statistieken, en verschillende alarmerende (en helaas veel voorkomende) misleidende statistieken voorbeelden uit het openbare leven te bekijken.
zijn statistieken betrouwbaar?
73,6% van de statistieken zijn onwaar. Echt? Nee, natuurlijk is het een verzonnen nummer (ook al zou zo ‘ n studie interessant zijn om te weten – maar nogmaals, kan alle gebreken die het probeert op hetzelfde moment aan te wijzen hebben). Statistische betrouwbaarheid is van cruciaal belang om de nauwkeurigheid en validiteit van de analyse te garanderen. Om ervoor te zorgen dat de betrouwbaarheid hoog is, zijn er verschillende technieken uit te voeren – ten eerste zijn de controles, die vergelijkbare resultaten moeten hebben bij het reproduceren van een experiment in vergelijkbare omstandigheden. Deze controlerende maatregelen zijn essentieel en moeten deel uitmaken van elk experiment of onderzoek – helaas is dat niet altijd het geval.
hoewel getallen niet liegen, kunnen ze in feite worden gebruikt om met halve waarheden te misleiden. Dit staat bekend als het ” misbruik van statistieken.”Er wordt vaak van uitgegaan dat het misbruik van statistieken beperkt is tot die individuen of bedrijven die winst willen halen uit het verdraaien van de waarheid, of het nu gaat om Economie, Onderwijs of massamedia.
het vertellen van halve waarheden door studie is echter niet alleen beperkt tot wiskundige amateurs. Een onderzoek uit 2009 van Dr. Daniele Fanelli van de Universiteit van Edinburgh vond dat 33,7% van de ondervraagde wetenschappers toegaf aan twijfelachtige onderzoekspraktijken, waaronder het wijzigen van resultaten om resultaten te verbeteren, subjectieve data-interpretatie, het achterhouden van analytische details en het laten vallen van observaties vanwege buikgevoelens…. Wetenschappers!
hoewel getallen niet altijd gefabriceerd of misleidend hoeven te zijn, is het duidelijk dat zelfs samenlevingen met de meeste vertrouwde numerieke poortwachters niet immuun zijn voor de onzorgvuldigheid en vooringenomenheid die kan ontstaan bij statistische interpretatieprocessen. Er zijn verschillende manieren waarop statistieken misleidend kunnen zijn, die we later zullen toelichten. De meest voorkomende is natuurlijk correlatie versus causatie, die altijd een andere (of twee of drie) factor weglaat die de werkelijke causatie van het probleem is. Het drinken van thee verhoogt diabetes met 50% en kaalheid verhoogt het risico op hart-en vaatziekten tot 70%! Zijn we vergeten de hoeveelheid suiker in de thee te vermelden, of het feit dat kaalheid en ouderdom gerelateerd zijn – net als risico ‘ s voor hart-en vaatziekten en ouderdom?
kunnen statistieken worden gemanipuleerd? Dat kunnen ze zeker. Liegen getallen? Jij kunt de rechter zijn.
How Statistics Can Be misleidend

onthoud dat misbruik van statistieken per ongeluk of doelgericht kan zijn. Terwijl een kwaadaardige intentie om lijnen te vervagen met misleidende statistieken zal zeker vergroten vooringenomenheid, intentie is niet nodig om misverstanden te creëren. Het misbruik van statistieken is een veel breder probleem dat nu door meerdere industrieën en studiegebieden doordringt. Hier zijn een paar mogelijke ongelukken die vaak leiden tot misbruik:
- defecte peiling
de manier waarop vragen worden geformuleerd kan een enorme impact hebben op de manier waarop een publiek ze beantwoordt. Specifieke formuleringspatronen hebben een overtuigend effect en stimuleren respondenten om op voorspelbare wijze te antwoorden. Bijvoorbeeld, in een poll op zoek naar fiscale meningen, laten we kijken naar de twee mogelijke vragen:
– bent u van mening dat u moet worden belast, zodat andere burgers niet hoeven te werken? Denk je dat de overheid mensen moet helpen die geen werk kunnen vinden?
deze twee vragen zullen waarschijnlijk veel verschillende antwoorden opleveren, ook al hebben zij betrekking op hetzelfde onderwerp van overheidssteun. Dit zijn voorbeelden van ” geladen vragen.”
een nauwkeuriger formulering zou de vraag zijn: “ondersteunt u de hulpprogramma’ s van de overheid voor werkloosheid?”of, (nog neutraler)” Wat is uw standpunt ten aanzien van werkloosheidsuitkeringen?”
de laatste twee voorbeelden van de oorspronkelijke vragen elimineren elke gevolgtrekking of suggestie van de poller en zijn dus beduidend onpartijdiger. Een andere oneerlijke methode van de peiling is het stellen van een vraag, maar voorafgaan met een voorwaardelijke verklaring of een verklaring van de feiten. Blijf bij ons voorbeeld, dat zou er zo uitzien: “gezien de stijgende kosten voor de middenklasse, steun je hulpprogramma’ s van de overheid?”
een goede vuistregel is om peilingen altijd te nemen met een korreltje zout, en om te proberen om de vragen die daadwerkelijk werden gepresenteerd te herzien. Ze bieden veel inzicht, vaak meer dan de antwoorden.
- gebrekkige correlaties
het probleem met correlaties is het volgende: als je voldoende variabelen meet, zal het uiteindelijk lijken dat sommige correleren. Aangezien één op de twintig zonder enige directe correlatie onvermijdelijk significant zal worden geacht, kunnen studies (met voldoende gegevens) worden gemanipuleerd om een correlatie aan te tonen die niet bestaat of die niet significant genoeg is om oorzakelijk verband te bewijzen.
om dit punt verder te illustreren, laten we aannemen dat een studie een correlatie heeft gevonden tussen een toename van auto-ongevallen in de staat New York in de maand Juni (A) en een toename van berenaanvallen in de staat New York in de maand juni (B).
dat betekent Dat er waarschijnlijk zes mogelijke verklaringen:
– Auto-ongevallen (Een) oorzaak bear aanvallen (B)- Bear aanvallen (B) de oorzaak van auto-ongevallen (A)- Auto-ongevallen (A) en bear aanvallen (B) mede oorzaak elkaar – Auto-ongevallen (A) en bear aanvallen (B) veroorzaakt zijn door een derde factor (C)- Bear aanvallen (B) worden veroorzaakt door een derde factor (C) wat overeenkomt met auto-ongelukken (A)- De correlatie is alleen kans
Ieder zinnig mens zou gemakkelijk identificeren van het feit dat auto-ongelukken veroorzaken geen beer aanvallen. Elk is waarschijnlijk een gevolg van een derde factor, dat is: een toegenomen bevolking, als gevolg van het hoog toeristische seizoen in de maand Juni. Het zou absurd zijn om te zeggen dat ze elkaar veroorzaken… en dat is precies waarom het ons voorbeeld is. Het is gemakkelijk om een correlatie te zien.
maar hoe zit het met het oorzakelijk verband? Wat als de gemeten variabelen anders waren? Wat als het iets geloofwaardiger was, zoals Alzheimer en ouderdom? Er is duidelijk een correlatie tussen de twee, maar is er een oorzakelijk verband? Velen zouden ten onrechte aannemen, Ja, uitsluitend gebaseerd op de sterkte van de correlatie. Wees voorzichtig, want ofwel bewust of onwetend, correlatie jacht zal blijven bestaan binnen statistische studies.
- Data fishing
dit voorbeeld van misleidende gegevens wordt ook” data bagger ” genoemd (en heeft betrekking op gebrekkige correlaties). Het is een datamining techniek waar extreem grote hoeveelheden gegevens worden geanalyseerd met het oog op het ontdekken van relaties tussen datapunten. Het zoeken naar een relatie tussen gegevens is niet een data misbruik per se, echter, dit te doen zonder een hypothese is.
data baggeren is een zelfvoorzienende techniek die vaak wordt gebruikt met het onethische doel om traditionele dataminingtechnieken te omzeilen, om aanvullende gegevensconclusies te zoeken die niet bestaan. Dit wil niet zeggen dat er geen correct gebruik is van datamining, omdat dit in feite kan leiden tot verrassende uitschieters en interessante analyses. Echter, vaker wel dan niet, Data baggeren wordt gebruikt om het bestaan van data relaties aan te nemen zonder verder onderzoek.
vaak resulteert datavissen in studies die zeer bekend zijn vanwege hun belangrijke of bizarre bevindingen. Deze studies worden al snel tegengesproken door andere belangrijke of bizarre bevindingen. Deze valse correlaties laten het grote publiek vaak erg in de war en zoeken naar antwoorden over de Betekenis van causatie en correlatie.
Een andere gangbare praktijk met gegevens is het weglaten, wat betekent dat na het bekijken van een grote dataset van antwoorden, u alleen degene kiest die uw standpunten en bevindingen ondersteunen en degenen weglaat die het tegenspreken. Zoals vermeld in het begin van dit artikel, is aangetoond dat een derde van de wetenschappers toegaf dat ze twijfelachtige onderzoekspraktijken hadden, waaronder het achterhouden van analytische details en het wijzigen van de resultaten…! Maar aan de andere kant, we worden geconfronteerd met een studie die zelf zou kunnen vallen in deze 33% van twijfelachtige praktijken, foutieve opiniepeilingen, selectieve vooringenomenheid… Het wordt moeilijk om elke analyse te geloven!
- misleidende datavisualisatie
inzichtelijke grafieken en grafieken bevatten zeer fundamentele, maar essentiële, groepering van elementen. Welke soorten datavisualisatie u ook kiest, het moet het volgende bevatten:
– de gebruikte schalen – de beginwaarde (nul of anders)- de berekeningsmethode (bijv. dataset en tijdsperiode)
zonder deze elementen moeten visuele gegevensrepresentaties met een korreltje zout worden bekeken, rekening houdend met de veelvoorkomende fouten in datavisualisatie die men kan maken. Er moeten ook tussenliggende gegevenspunten worden geïdentificeerd en de context moet worden aangegeven indien dit een meerwaarde zou betekenen voor de gepresenteerde informatie. Met de toenemende afhankelijkheid van intelligente oplossingsautomatisering voor vergelijkingen van variabele gegevenspunten, moeten best practices (d.w.z. ontwerp en schaling) worden geïmplementeerd voordat gegevens uit verschillende bronnen, datasets, tijden en locaties worden vergeleken.
- doelgerichte en selectieve bias
de laatste van onze meest voorkomende voorbeelden voor misbruik van statistieken en misleidende gegevens is misschien wel de ernstigste. Doelgerichte bias is de opzettelijke poging om gegevensbevindingen te beïnvloeden zonder zelfs maar te veinzen professionele verantwoording. Bias is het meest waarschijnlijk in de vorm van gegevens weglatingen of aanpassingen.
de selectieve bias is iets discreter voor wie de kleine regels niet leest. Het valt meestal op de steekproef van de ondervraagde mensen. Bijvoorbeeld, de aard van de groep ondervraagde mensen: vragen aan een college student over de wettelijke leeftijd van drinken, of een groep van gepensioneerden over de ouderenzorg systeem. U zult eindigen met een statistische fout genaamd “selectieve bias”.
- gebruikmakend van procentuele verandering in combinatie met een kleine steekproefgrootte
een andere manier om misleidende statistieken te creëren, ook gekoppeld aan de hierboven besproken steekproefkeuze, is de grootte van die steekproef. Wanneer een experiment of een enquête wordt geleid op basis van een totaal niet significante steekproefgrootte, zullen niet alleen de resultaten onbruikbaar zijn, maar zal de manier om ze te presenteren – namelijk als percentages – volkomen misleidend zijn.
Een vraag stellen aan een steekproef van 20 personen, waarbij 19 antwoorden “Ja” (=95% zeggen voor ja) versus dezelfde vraag stellen aan 1.000 personen en 950 antwoorden “Ja” (=95% ook): de validiteit van het percentage is duidelijk niet hetzelfde. Het is volkomen misleidend om alleen het percentage verandering zonder het totale aantal of de steekproefgrootte te vermelden. xkdc ’s comic illustreren dit heel goed, om te laten zien hoe de “snelst groeiende” claim is een totaal relatieve marketing speech:

evenzo wordt de benodigde steekproefgrootte beïnvloed door het soort vraag dat u stelt, de statistische significantie die u nodig hebt (klinische studie vs.bedrijfsstudie) en de statistische techniek. Als u een kwantitatieve analyse uitvoert, zijn monstergroottes onder 200 mensen meestal ongeldig.
misleidende statistieken voorbeelden in het echte leven
nu we een aantal van de meest gangbare methoden van misbruik van gegevens hebben beoordeeld, laten we eens kijken naar verschillende digitale tijdperk voorbeelden van misleidende statistieken over drie verschillende, maar verwante, spectrums: media en politiek, reclame en wetenschap. Hoewel bepaalde onderwerpen die hier worden vermeld waarschijnlijk emotie roeren afhankelijk van iemands standpunt, hun opname is alleen voor data demonstratie doeleinden.
- Voorbeelden van misleidende statistiek in de media en de politiek
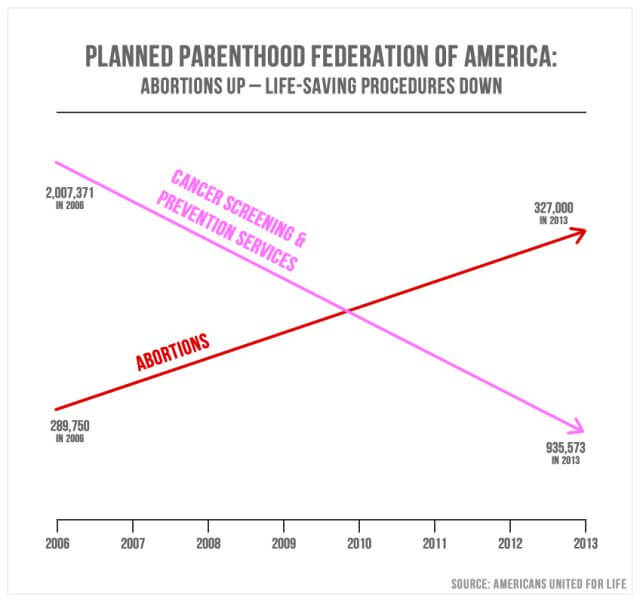
Misleidende statistiek in de media zijn heel gebruikelijk. Op Sept. 29, 2015, Republikeinen van het Amerikaanse Congres ondervraagd Cecile Richards, de president van Planned Parenthood, met betrekking tot de verduistering van $500 miljoen in jaarlijkse federale financiering. De bovenstaande grafiek / grafiek werd gepresenteerd als een punt van nadruk.
vertegenwoordiger Jason Chaffetz uit Utah legde uit: “in roze is dat de vermindering van de borstonderzoeken, en het rood is de toename van de abortussen. Dat is wat er gaande is in je organisatie.”
op basis van de structuur van de grafiek lijkt het in feite aan te tonen dat het aantal abortussen sinds 2006 aanzienlijk is toegenomen, terwijl het aantal kankeronderzoeken aanzienlijk is afgenomen. De bedoeling is om een verschuiving in focus over te brengen van kanker screenings naar abortus. De grafiekpunten lijken aan te geven dat 327.000 abortussen in inherente waarde groter zijn dan 935.573 kanker screenings. Toch zal nader onderzoek onthullen dat de grafiek geen gedefinieerde y-as heeft. Dit betekent dat er geen definieerbare rechtvaardiging is voor de plaatsing van de zichtbare meetlijnen.
Politifact, een fact checking advocacy website, beoordeelde de cijfers van Rep.Chaffetz via een vergelijking met de eigen jaarverslagen van Planned Parenthood. Met behulp van een duidelijk gedefinieerde schaal ziet de informatie er als volgt uit:

en zoals dit met een andere geldige schaal:
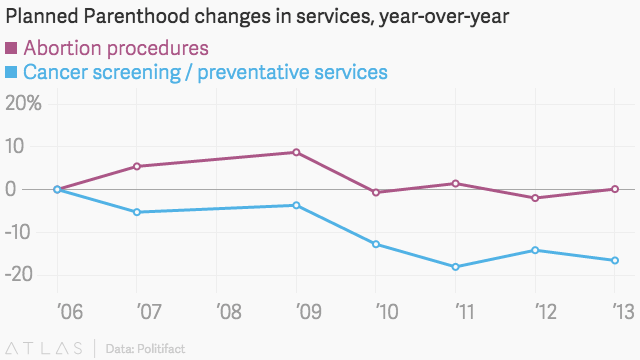
eenmaal geplaatst binnen een duidelijk gedefinieerde schaal, wordt het duidelijk dat, hoewel het aantal kankeronderzoeken in feite is afgenomen, het nog steeds veel groter is dan het aantal abortieprocedures dat jaarlijks wordt uitgevoerd. Als zodanig is dit een groot voorbeeld van misleidende statistieken, en sommigen zouden vooringenomenheid kunnen aanvoeren gezien het feit dat de grafiek niet afkomstig is van het Congreslid, maar van Americans United for Life, een anti-abortusgroep. Dit is slechts een van de vele voorbeelden van misleidende statistieken in de media en de politiek.
- misleidende statistieken in reclame

In 2007 werd Colgate door de Advertising Standards Authority (ASA) van het Verenigd Koninkrijk om hun claim te verlaten: “meer dan 80% van de tandartsen raden Colgate.”De slogan in kwestie werd gepositioneerd op een reclame billboard in het Verenigd Koninkrijk, en werd geacht in strijd te zijn met de Britse reclame regels.
de claim, die was gebaseerd op door de fabrikant uitgevoerde onderzoeken onder tandartsen en hygiënisten, bleek onjuist te zijn omdat de deelnemers hierdoor een of meer tandpastamerken konden selecteren. De ASA verklaarde dat de claim “… zou worden begrepen door de lezers te betekenen dat 80 procent van de tandartsen Colgate aanbevelen boven andere merken, en de resterende 20 procent zou aanbevelen verschillende merken.”
de ASA vervolgde: “omdat we begrepen dat het merk van een andere concurrent bijna evenveel werd aanbevolen als het merk Colgate door de ondervraagde tandartsen, concludeerden we dat de bewering ten onrechte impliceerde dat 80 procent van de tandartsen Colgate-tandpasta aanbeveelt in plaats van alle andere merken.”De ASA beweerde ook dat de scripts die voor de enquête werden gebruikt de deelnemers informeerden dat het onderzoek werd uitgevoerd door een onafhankelijk onderzoeksbureau, wat inherent onjuist was.
op basis van de misbruik technieken die we hebben behandeld, is het veilig om te zeggen dat deze List off-hand techniek door Colgate is duidelijk voorbeeld van misleidende statistieken in reclame, en zou vallen onder verkeerde opiniepeilingen en regelrechte vertekening.
- misleidende statistieken in de wetenschap
net als abortus is opwarming van de aarde een ander politiek geladen onderwerp dat waarschijnlijk emoties oproept. Het is ook een onderwerp dat krachtig wordt onderschreven door zowel tegenstanders als voorstanders via studies. Laten we eens kijken naar wat van de bewijzen voor en tegen.
algemeen wordt aangenomen dat de globale gemiddelde temperatuur in 1998 58,3 graden Fahrenheit was. Dit is volgens NASA ‘ s Goddard Institute for Space Studies. In 2012 werd de wereldwijde gemiddelde temperatuur gemeten op 58,2 graden. Het wordt daarom aangevoerd door tegenstanders van de opwarming van de aarde dat, aangezien er een 0,1 graden daling van de gemiddelde temperatuur over een periode van 14 jaar was, de opwarming van de aarde wordt weerlegd.
onderstaande grafiek is de grafiek die het vaakst wordt gebruikt om de opwarming van de aarde te weerleggen. Het toont de verandering in de luchttemperatuur (Celsius) van 1998 tot 2012.
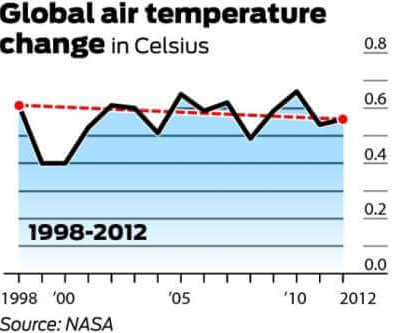
Het is vermeldenswaard dat 1998 een van de heetste jaren ooit was vanwege een abnormaal sterke El Niño windstroom. Het is ook vermeldenswaard dat, aangezien er een grote mate van variabiliteit binnen het klimaatsysteem is, temperaturen meestal worden gemeten met ten minste een cyclus van 30 jaar. De onderstaande grafiek geeft de 30-jarige verandering in de wereldwijde gemiddelde temperatuur weer.
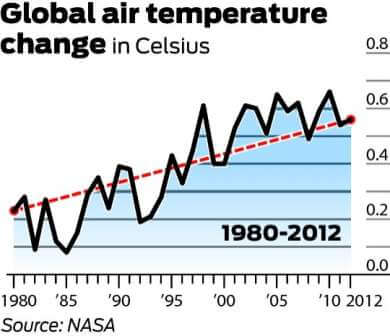
en kijk nu naar de trend van 1900 tot 2012: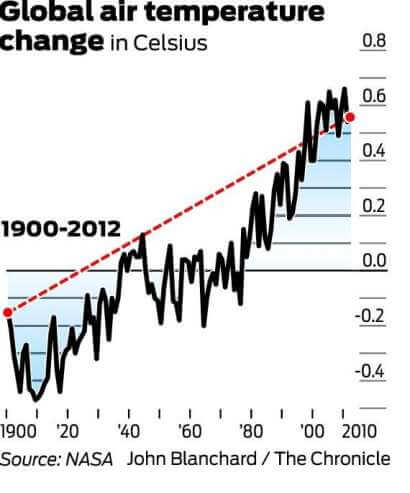
terwijl de lange-term data kan lijken te weerspiegelen een plateau, het schetst duidelijk een beeld van geleidelijke opwarming. Daarom is het gebruik van de eerste grafiek, en alleen de eerste grafiek, om de opwarming van de aarde te weerleggen een perfect voorbeeld van misleidende statistieken.
How To Read Statistics With Distance
een eerste goede zaak zou natuurlijk zijn om voor een eerlijk onderzoek/experiment/onderzoek te staan – kies degene die je onder je ogen hebt –, die de juiste technieken voor het verzamelen en interpreteren van gegevens heeft toegepast. Maar je kunt het niet weten totdat je jezelf een paar vragen stelt en de resultaten analyseert die je tussen je handen hebt.
als ondernemer en voormalig consultant Mark Suster adviseert in een artikel, moet je je afvragen wie het primaire onderzoek van deze analyse deed. Onafhankelijke universiteit studiegroep, lab-aangesloten onderzoeksteam, adviesbureau? Daaruit komt natuurlijk de vraag voort: wie betaalde ze? Aangezien niemand gratis werkt, is het altijd interessant om te weten wie het onderzoek sponsort. Ook, wat zijn de motieven achter het onderzoek? Wat hebben de wetenschapper of statistici geprobeerd te achterhalen? Tot slot, hoe groot was de sample set en wie maakte er deel van uit? Hoe inclusief was het?
dit zijn belangrijke vragen om na te denken en te beantwoorden alvorens overal vertekende of bevooroordeelde resultaten te verspreiden – ook al gebeurt dit de hele tijd, vanwege versterking. Een typisch voorbeeld van versterking gebeurt vaak met kranten en journalisten, die een stuk gegevens nemen en het moeten omzetten in krantenkoppen – dus vaak uit de oorspronkelijke context. Niemand koopt een tijdschrift waar staat dat volgend jaar, hetzelfde gaat gebeuren in XYZ markt als dit jaar-hoewel het waar is. Redacteuren, klanten en mensen willen iets nieuws, niet iets dat ze weten; dat is waarom we vaak eindigen met een versterkingsfenomeen dat weerklinkt en meer dan het zou moeten.
misbruik van statistieken-een samenvatting
op de vraag ” kunnen statistieken worden gemanipuleerd?”, kunnen we 6 vaak gebruikte methoden aanpakken – met opzet of niet-die de analyse en de resultaten scheeftrekken. Hier zijn veel voorkomende vormen van misbruik van statistieken:
- defecte polling
- gebrekkige correlaties
- data fishing
- misleidende gegevensvisualisatie
- doelgerichte en selectieve bias
- gebruikmakend van procentuele verandering in combinatie met een kleine steekproefgrootte
nu je ze kent, is het makkelijker om ze te herkennen en alle statistieken die je elke dag krijgt in vraag te stellen. Om ervoor te zorgen dat u een bepaalde afstand houdt tot de studies en enquêtes die u leest, onthoudt u ook de vragen die u zich moet stellen: wie onderzocht en waarom, wie betaalde ervoor, wat was het monster.
Transparency and Data-Driven Business Solutions
hoewel het vrij duidelijk is dat statistische gegevens het potentieel hebben om te worden misbruikt, kan het ook ethisch de marktwaarde in de digitale wereld stimuleren. Big data biedt bedrijven uit het digitale tijdperk een routekaart voor efficiëntie en transparantie, en uiteindelijk voor winstgevendheid. Geavanceerde technologieoplossingen zoals online rapportagesoftware kunnen statistische gegevensmodellen verbeteren en bedrijven uit het digitale tijdperk meer concurrentie bieden.
of het nu gaat om marktinformatie, klantervaring of bedrijfsrapportage, de toekomst van data is nu. Zorg ervoor dat u gegevens op een verantwoorde, ethische en visuele manier toepast en kijk hoe uw transparante corporate identity groeit.