alle databasegebruikers kennen reguliere geaggregeerde functies die op een volledige tabel werken en worden gebruikt met een groep per clausule. Maar zeer weinig mensen gebruiken Vensterfuncties in SQL. Deze werken op een reeks rijen en retourneren één geaggregeerde waarde voor elke rij.
Het belangrijkste voordeel van het gebruik van Vensterfuncties ten opzichte van reguliere aggregaatfuncties is: Vensterfuncties zorgen er niet voor dat rijen worden gegroepeerd in een enkele uitvoerrij, de rijen behouden hun afzonderlijke identiteiten en er wordt een geaggregeerde waarde aan elke rij toegevoegd.
laten we eens kijken naar hoe Window functies werken en dan een paar voorbeelden zien van het gebruik ervan in de praktijk om er zeker van te zijn dat dingen duidelijk zijn en ook hoe de SQL en output zich verhouden tot die voor SUM() functies.
zoals altijd moet u er zeker van zijn dat u een volledige back-up hebt, vooral als u nieuwe dingen uitprobeert met uw database.
Inleiding tot Vensterfuncties
Vensterfuncties werken op een reeks rijen en retourneren één geaggregeerde waarde voor elke rij. Het term-venster beschrijft de reeks rijen in de database waarop de functie zal werken.
We definiëren het venster (set van rijen waarop functies werken) met behulp van een over () – clausule. We zullen meer bespreken over de OVER() clausule in het artikel hieronder.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Wanneer u alles opneemt, telt het alle waarden, inclusief dubbele. DISTINCT wordt niet ondersteund in vensterfuncties
expressie
De doelkolom of expressie waarop de functies werken. Met andere woorden, de naam van de kolom waarvoor we een geaggregeerde waarde nodig hebben. Bijvoorbeeld een kolom met orderbedrag zodat we het totaal aantal ontvangen bestellingen kunnen zien.
Over
specificeert de vensterclausules voor geaggregeerde functies.
partitie door partition_list
definieert het venster (set van rijen waarop de vensterfunctie werkt) voor vensterfuncties. We moeten een veld of lijst met velden opgeven voor de partitie na partitie per clausule. Meerdere velden moeten worden gescheiden door een komma zoals gewoonlijk. Als partitie door niet is opgegeven, zal groepering worden gedaan op de hele tabel en waarden zullen dienovereenkomstig worden samengevoegd.
volgorde op order_list
sorteert de rijen binnen elke partitie. Als ORDER BY niet is opgegeven, gebruikt ORDER BY de volledige tabel.
voorbeelden
laten we tabel maken en dummy records invoegen om verdere query ‘ s te schrijven. Voer de code uit.
geaggregeerde Vensterfuncties
SUM ()
We kennen allemaal de sum() geaggregeerde functie. Het doet de som van het opgegeven veld voor de opgegeven groep (zoals stad, staat, land etc.) of voor de gehele tabel als de groep niet is opgegeven. We zullen zien wat de output van de reguliere SUM() aggregate functie en window SUM() aggregate functie zal zijn.
het volgende is een voorbeeld van een reguliere Sum() aggregaat functie. Het somt het orderbedrag voor elke stad.
u kunt aan de resultaatset zien dat een reguliere geaggregeerde functie meerdere rijen groepeert in een enkele uitvoerrij, waardoor afzonderlijke rijen hun identiteit verliezen.
|
1
2
3
4
|
SELECTEER de stad, SUM(order_amount) total_order_amount
UIT . Groeperen op plaats
|

Dit gebeurt niet met vensteraggregaatfuncties. Rijen behouden hun identiteit en tonen ook een geaggregeerde waarde voor elke rij. In het onderstaande voorbeeld doet de query hetzelfde, namelijk het aggregeert de gegevens voor elke stad en toont de som van het totale orderbedrag voor elk van hen. De query voegt nu echter een andere kolom in voor het totale orderbedrag, zodat elke rij zijn identiteit behoudt. De kolom gemarkeerd grand_total is de nieuwe kolom in het voorbeeld hieronder.
AVG()
AVG or Average werkt op precies dezelfde manier met een Window functie.
de volgende query geeft u het gemiddelde orderbedrag voor elke stad en voor elke maand (hoewel we voor de eenvoud alleen gegevens in een maand hebben gebruikt).
we specificeren meer dan één Gemiddelde door meerdere velden in de partitielijst op te geven.
Het is ook vermeldenswaard dat u uitdrukkingen kunt gebruiken in de lijsten zoals maand(order_date) zoals weergegeven in onderstaande query. Zoals altijd kun je deze uitdrukkingen zo complex maken als je wilt, zolang de syntaxis correct is!
uit de bovenstaande afbeelding kunnen we duidelijk zien dat we gemiddeld 12.333 orders hebben ontvangen voor Arlington city in April 2017.
gemiddeld orderbedrag = totaal orderbedrag / totaal Orders
= (20,000 + 15,000 + 2,000) / 3
= 12,333
u kunt ook de combinatie van SUM() & COUNT() functie gebruiken om een gemiddelde te berekenen.
MIN ()
De functie min() aggregate vindt de minimumwaarde voor een opgegeven groep of voor de hele tabel als de groep niet is opgegeven.
bijvoorbeeld, we zijn op zoek naar de kleinste volgorde (minimale volgorde) voor elke stad die we zouden gebruiken de volgende query.
MAX ()
net zoals de MIN() functies u de minimale waarde geven, zal de MAX() functie de grootste waarde van een opgegeven veld identificeren voor een opgegeven groep rijen of voor de hele tabel als een groep niet is opgegeven.
laten we de grootste orde (maximaal orderbedrag) voor elke stad vinden.
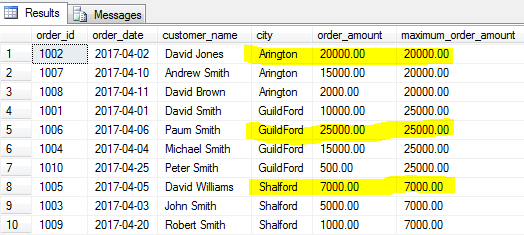
COUNT ()
de COUNT() functie telt de records / rijen.
merk op dat DISTINCT niet wordt ondersteund met de functie window COUNT (), terwijl het wordt ondersteund voor de functie regular COUNT (). DISTINCT helpt u om de verschillende waarden van een bepaald veld te vinden.
als we bijvoorbeeld willen zien hoeveel klanten een bestelling hebben geplaatst in April 2017, kunnen we niet direct alle klanten tellen. Het is mogelijk dat dezelfde klant meerdere bestellingen in dezelfde maand heeft geplaatst.
COUNT (customer_name) geeft u een onjuist resultaat omdat het duplicaten zal tellen. Overwegende dat COUNT (DISTINCT customer_name) geeft u het juiste resultaat als het telt elke unieke klant slechts één keer.
geldig voor de functie regular COUNT ():
|
1
2
3
4
5
|
SELECTEER de stad,COUNT(DISTINCT customer_name) number_of_customers
UIT .
groeperen op plaats
|
ongeldig voor window COUNT() functie:
de bovenstaande query met Window functie geeft u onderstaande fout.
laten we nu de totale ontvangen volgorde voor elke stad vinden met de functie window COUNT ().
Ranking Vensterfuncties
net zoals Vensteraggregaatfuncties de waarde van een opgegeven veld aggregeren, zullen RANKINGFUNCTIES de waarden van een opgegeven veld rangschikken en categoriseren volgens hun rang.
het meest voorkomende gebruik van RANKING functies is het vinden van de top (N) records op basis van een bepaalde waarde. Bijvoorbeeld, Top 10 best betaalde werknemers, Top 10 gerangschikt studenten, Top 50 grootste bestellingen etc.
de volgende functies worden ondersteund:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE ()
laten we ze een voor een bespreken.
RANK ()
De functie RANK() wordt gebruikt om een unieke rang aan elke record te geven op basis van een bepaalde waarde, bijvoorbeeld salaris, orderbedrag enz.
als twee records dezelfde waarde hebben dan zal de functie RANK() dezelfde rang aan beide records toewijzen door de volgende rang over te slaan. Dit betekent-als er twee identieke waarden op rang 2 zijn, zal het dezelfde rang 2 aan beide records toewijzen en dan Rang 3 overslaan en rang 4 aan het volgende record toewijzen.
laten we elke bestelling rangschikken op hun orderbedrag.
|
1
2
3
4
5
|
SELECTEER order_id,order_date,customer_name,stad,
RANK() OVER(ORDER BY order_amount DESC)
UIT .
|
uit de bovenstaande afbeelding kunt u zien dat dezelfde rang (3) is toegewezen aan twee identieke records (elk met een orderbedrag van 15.000) en het slaat dan de volgende rang over (4) en wijs rang 5 toe aan het volgende record.
DENSE_RANK ()
De functie dense_rank() is identiek aan de functie RANK (), behalve dat het geen rang overslaat. Dit betekent dat als er twee identieke records worden gevonden, DENSE_RANK () dezelfde rang aan beide records zal toewijzen, maar niet overslaan en dan de volgende rang overslaan.
laten we eens kijken hoe dit in de praktijk werkt.
zoals u hierboven duidelijk kunt zien, wordt dezelfde rang gegeven aan twee identieke records (elk met hetzelfde orderbedrag) en dan wordt het volgende rangnummer gegeven aan de volgende record zonder een rangwaarde over te slaan.
ROW_NUMBER ()
De naam spreekt voor zich. Deze functies kennen een uniek rijnummer toe aan elk record.
het rijnummer zal worden gereset voor elke partitie als partitie door is opgegeven. Laten we eens kijken hoe ROW_NUMBER() werkt zonder partitie door en dan met partitie door.
ROW_ NUMBER () zonder partitie door
ROW_NUMBER() met partitie door
merk op dat we de partitie op city hebben gedaan. Dit betekent dat het rijnummer wordt gereset voor elke stad en dus opnieuw op 1 start. De volgorde van de rijen wordt echter bepaald door het orderbedrag, zodat voor een bepaalde stad het grootste orderbedrag de eerste rij is en dus rij nummer 1 wordt toegewezen.
NTILE ()
NTILE() is een zeer nuttige vensterfunctie. Het helpt u om te identificeren welk percentiel (of kwartiel, of een andere onderverdeling) een bepaalde rij valt in.
Dit betekent dat als u 100 rijen hebt en u 4 kwartielen wilt maken op basis van een opgegeven waardeveld, u dit gemakkelijk kunt doen en kunt zien hoeveel rijen in elk kwartiel vallen.
laat een voorbeeld zien. In de onderstaande query hebben we aangegeven dat we vier kwartielen willen maken op basis van het orderbedrag. We willen dan zien hoeveel orders er in elk kwartiel vallen.
NTILE maakt tegels aan op basis van de volgende formule:
aantal rijen in elke tegel = aantal rijen in resultaatset / aantal tegels opgegeven
Hier is ons voorbeeld, we hebben in totaal 10 rijen en 4 tegels zijn gespecificeerd in de query dus het aantal rijen in elke tegel zal 2,5 (10/4) zijn. Aangezien het aantal rijen een geheel getal moet zijn, niet een decimaal. SQL engine zal 3 rijen toewijzen voor de eerste twee groepen en 2 rijen voor de resterende twee groepen.
waarde Vensterfuncties
LAG () en LEAD ()
LEAD() en LAG () functies zijn zeer krachtig, maar kunnen complex zijn om uit te leggen.
omdat dit een inleiding is hieronder bekijken we een heel eenvoudig voorbeeld om te illustreren hoe ze te gebruiken.
De LAG-functie maakt het mogelijk om toegang te krijgen tot gegevens uit de vorige rij in dezelfde resultaatset zonder gebruik te maken van SQL-joins. U kunt zien in onderstaand voorbeeld, met behulp van de LAG-functie vonden we de vorige besteldatum.
Script om de vorige orderdatum te vinden met behulp van de functie LAG ():
LEAD-functie maakt toegang tot gegevens uit de volgende rij in dezelfde resultatenset mogelijk zonder gebruik van SQL-joins. U kunt in onderstaand voorbeeld zien, met behulp van de LEAD-functie vonden we de volgende besteldatum.
Script om de volgende orderdatum te vinden met behulp van LEAD() functie:
FIRST_VALUE() en LAST_VALUE ()
Deze functies helpen u bij het identificeren van de eerste en laatste record binnen een partitie of hele tabel als partitie door niet is opgegeven.
laten we de eerste en laatste volgorde van elke stad vinden uit onze bestaande dataset. Opmerking volgorde per clausule is verplicht voor FIRST_VALUE() en LAST_VALUE () functies
uit de bovenstaande afbeelding kunnen we duidelijk zien dat de eerste bestelling ontvangen op 2017-04-02 en de laatste bestelling ontvangen op 2017-04-11 voor Arlington city en het werkt hetzelfde voor andere steden.
Links
- Back-up Types & Strategieën voor SQL-Databases
- TechNet-Artikel op de Component
- MSDN-Artikel Op DENSE_RANK
Andere geweldige artikelen van Ben
Hoe SQL Server selecteert een impasse
Hoe Te Gebruiken het Venster Functies
- Auteur
- Laatste Berichten
bekijk alle berichten van Ben Richardson
- Power BI: Waterfall Charts and Combined Visuals – January 19, 2021
- Power BI: Voorwaardelijke opmaak en gegevens kleuren in actie – 14 januari 2021
- Power BI: Importeren van gegevens uit SQL Server en MySQL – 12 januari 2021