BasicsEdit
eerste woordenschat:
| activering | = statuswaarde van het neuron. Voor binaire neuronen is dit meestal 0 / 1, of +1 / -1. |
| CAM | = adresseerbaar geheugen. Een herinnering oproepen door een gedeeltelijk patroon in plaats van een geheugenadres. |
| convergentie | = de stabilisatie van een activeringspatroon op een netwerk. In SL betekent convergentie stabilisatie van gewichten & vertekeningen in plaats van activeringen. |
| discriminatief | = met betrekking tot herkenningstaken. Ook wel analyse (in Patroontheorie), of gevolgtrekking genoemd. |
| energie | = een macroscopische grootheid die het activeringspatroon in een netwerk beschrijft. (zie hieronder) |
| generalisatie | = nauwkeurig gedragen op eerder niet-aangetroffen ingangen |
| generatief | = Machine imagined and recall task. soms synthese genoemd( in Patroontheorie), nabootsing, of diepe vervalsingen. |
| gevolgtrekking | = de” run ” fase (in tegenstelling tot training). Tijdens de gevolgtrekking voert het netwerk de taak uit waarvoor het getraind is—het herkennen van een patroon (SL) of het creëren van een patroon (UL). Gewoonlijk daalt de gevolgtrekking de gradiënt van een energiefunctie af. In tegenstelling tot SL, gradiëntafdaling optreedt tijdens de training, niet gevolgtrekking. |
| machine vision | = machine learning op afbeeldingen. |
| NLP | = verwerking van natuurlijke taal. Machine learning van menselijke talen. |
| patroon | = netwerkactivaties die in zekere zin een interne volgorde hebben, of die compacter kunnen worden beschreven door functies in de activaties. Bijvoorbeeld, het pixelpatroon van een nul, of het nu gegeven wordt als data of voorgesteld door het netwerk, heeft een functie die beschrijfbaar is als een enkele lus. De kenmerken zijn gecodeerd in de verborgen neuronen. |
| training | = de leerfase. Hier past het netwerk zijn gewichten aan & vooroordelen aan om van de ingangen te leren. |
taken

UL methods bereiden gewoonlijk een netwerk voor voor generatieve taken in plaats van herkenning, maar het groeperen van taken als gecontroleerd of niet kan wazig zijn. Bijvoorbeeld, handschriftherkenning begon in de jaren 1980 als SL. Dan in 2007, wordt UL gebruikt om het netwerk voor SL daarna te primen. Momenteel heeft SL zijn positie als de betere methode herwonnen.
Training
tijdens de leerfase probeert een netwerk zonder toezicht de gegeven gegevens na te bootsen en gebruikt de fout in de nagebootste uitvoer om zichzelf te corrigeren (bijv. de gewichten & biases). Dit lijkt op het nabootsingsgedrag van kinderen als ze een taal leren. Soms wordt de fout uitgedrukt als een lage waarschijnlijkheid dat de foutieve output optreedt, of het kan worden uitgedrukt als een onstabiele hoge energietoestand in het netwerk.
energie
Een energiefunctie is een macroscopische maat voor de toestand van een netwerk. Deze analogie met de natuurkunde is geïnspireerd door Ludwig Boltzmanns analyse van de macroscopische energie van een gas uit de microscopische waarschijnlijkheid van deeltjesbeweging p ∝ {\displaystyle \propto }

eE/kT, waarbij k de Boltzmann-constante is en T de temperatuur. In het RBM-netwerk is de relatie p = e-E / Z, waarbij p & e variëren over elk mogelijk activatiepatroon en Z = ∑ A l l P a t T T E r n s {\displaystyle \sum _{AllPatterns}}

e-E(patroon). Om preciezer te zijn, p(a) = e-E(a) / Z, waarbij a een activatiepatroon is van alle neuronen (zichtbaar en verborgen). Daarom dragen vroege neurale netwerken de naam Boltzmann Machine. Paul Smolensky roept-E De Harmonie. Een netwerk zoekt lage energie die een hoge harmonie.
Netwerken
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
 |
 autoencoder
|
 afwijkende autoencoder
|
Boltzmann en Helmholtz kwam voor neurale netwerken formuleringen, maar deze netwerken geleend van hun analyses, zodat deze netwerken dragen hun namen. Hopfield droeg echter rechtstreeks bij aan UL.
Intermediatedit
Hier worden distributies p(x) en q(x) afgekort als p en q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Het wordt meestal gebruikt in SL, maar verdient een vermelding hier. |
| 1982 | Ising variant Hopfield net beschreven als CAMs en classifiers door John Hopfield. |
| 1983 | Ising variant Boltzmann machine met probabilistische neuronen beschreven door Hinton & Sejnowski volgend op Sherington & Kirkpatrick ‘ s 1975 werk. |
| 1986 | Paul Smolensky publiceert Harmonietheorie, een RBM met vrijwel dezelfde Boltzmann-energiefunctie. Smolensky gaf geen praktische training. Hinton deed midden jaren 2000 |
| 1995 | Schmidthuber introduceert het LSTM-neuron voor talen. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| kans | |
| cdf | = cumulatieve distributiefunctie. de integraal van de pdf. De kans om in de buurt van 3 te komen is het gebied onder de curve tussen 2.9 en 3.1. |
| contrastieve divergentie | = een leermethode waarbij men de energie op opleidingspatronen verlaagt en de energie op ongewenste patronen buiten de Opleidingsset verhoogt. Dit verschilt sterk van de KL-divergentie, maar deelt een soortgelijke formulering. |
| verwachte waarde | = E(x) = ∑ x {\displaystyle \sum _{x}}
 x * p(X). Dit is de gemiddelde waarde, of Gemiddelde waarde. Voor continue input x, vervang de sommatie door een integraal. |
| latente variabele | = een niet-waargenomen hoeveelheid die helpt om waargenomen gegevens te verklaren. bijvoorbeeld, een griepinfectie (onopgemerkt) kan verklaren waarom de een persoon niest (waargenomen). In probabilistische neurale netwerken fungeren verborgen neuronen als latente variabelen, hoewel hun latente interpretatie niet expliciet bekend is. |
| = kansdichtheidsfunctie. De kans dat een willekeurige variabele een bepaalde waarde krijgt. Voor continue pdf kan p(3) = 1/2 nog steeds betekenen dat er bijna geen kans is om deze exacte waarde van 3 te bereiken. We rationaliseren dit met de cdf. | |
| stochastische | = gedraagt zich volgens een goed beschreven waarschijnlijkheidsformule. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Het is het maximale omkeerbare werk dat kan worden uitgevoerd door een warmtesysteem bij constante temperatuur en druk. vrije energie G = warmte – temperatuur * entropie |
| informatie | = de informatiehoeveelheid van een bericht x = -log p(x) |
| KLD | = relatieve entropie. Voor probabilistische netwerken is dit het analoog van de fout tussen input & nagebootste uitvoer. De kullback-Liebler divergentie (KLD) meet de entropieafwijking van 1 distributie van een andere distributie. KLD( p, q) = ∑ x {\displaystyle \sum _{x}}
p * log (p / q ). Gewoonlijk geeft p de inputgegevens weer, q De interpretatie van het netwerk en KLD het verschil tussen de twee. |
de Vergelijking van de Netwerken
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE | |
|---|---|---|---|---|---|---|
| gebruik & notabelen | CAM, handelsreiziger probleem | CAM. De Vrijheid van verbindingen maakt dit netwerk moeilijk te analyseren. | patroonherkenning (MNIST, spraakherkenning) | verbeelding, nabootsing | taal: creatief schrijven, vertaling. Visie: verbetering van wazige beelden | genereer realistische gegevens |
| neuron | deterministische binaire toestand. Activering = { 0 (of -1) Als x negatief is, 1 anders } | stochastisch binair Hopfield neuron | stochastisch binair. Uitgebreid naar real-valued in het midden van de jaren 2000 | binair, sigmoid | taal: LSTM. visie: lokale ontvankelijke velden. meestal echte waarde relu activering. | |
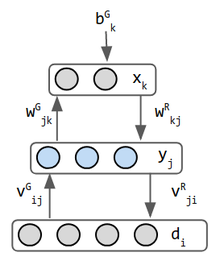
| verbindingen | 1-laag met symmetrische gewichten. Geen zelf-connecties. | 2-lagen. 1-hidden & 1-zichtbaar. symmetrische gewichten. | 2-lagen. symmetrische gewichten. geen zijdelingse verbindingen binnen een laag. | 3-lagen: asymmetrische gewichten. 2 netwerken gecombineerd in 1. | 3-lagen. De input wordt beschouwd als een laag, hoewel het geen inkomende gewichten heeft. terugkerende lagen voor NLP. feedforward convolutions for vision. input & output hebben dezelfde neurontellingen. | 3-lagen: invoer, encoder, distributie sampler decoder. (e) |
| gevolgtrekking & energie | energie wordt gegeven door Gibbs waarschijnlijkheidsmaat : E = − 1 2 ∑ i , j w i j s i s j + ∑ i θ i s i {\displaystyle E=-{\frac {1}{2}}\som _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\som _{i}{\theta _{i}}{s_{i}}}
 |
← dezelfde | ← dezelfde | minimaliseren KL divergentie | gevolgtrekking is alleen feed-forward. vorige UL-netwerken liepen vooruit en achteruit | minimaliseer fout = reconstructie fout-KLD |
| training | Δwij = si * sj, voor + 1 / -1 neuron | Δwij = e*(pij – p ‘ IJ). Dit is afgeleid van het minimaliseren van KLD. e = leerpercentage, p ‘ = voorspelde en p = werkelijke verdeling. | contrastieve divergentie w / Gibbs Sampling | wake-sleep 2 phase training | back propagate the reconstruction error | herparameterize hidden state for backprop | strength | lijkt op fysieke systemen, dus het erft hun vergelijkingen | < – – – same. verborgen neuronen fungeren als interne representatatie van de externe wereld | sneller meer praktische training schema dan Boltzmann machines | licht anatomisch. analyzable w/ information theory & statistische mechanica |
| zwakte | hopfield | moeilijk te trainen als gevolg van laterale verbindingen | RBM | Helmholtz |
specifieke netwerken
hier benadrukken we enkele kenmerken van elke netwerken. Ferromagnetisme inspireerde Hopfield networks, Boltzmann machines en RBM ‘ s. Een neuron komt overeen met een ijzeren domein met binaire magnetische momenten op en neer, en neurale verbindingen komen overeen met de invloed van het domein op elkaar. Symmetrische verbindingen maken een globale energieformulering mogelijk. Tijdens de gevolgtrekking werkt het netwerk elke toestand bij met behulp van de standaard activeringsstapfunctie. Symmetrische gewichten garanderen convergentie naar een stabiel activeringspatroon.
Hopfield netwerken worden gebruikt als nokken en hebben gegarandeerd een bepaald patroon. Zonder symmetrische gewichten is het netwerk erg moeilijk te analyseren. Met de juiste energiefunctie zal een netwerk convergeren.Boltzmann-machines zijn stochastische Hopveldnetten. Hun statuswaarde wordt als volgt gesampled uit deze pdf: stel dat een binair neuron vuurt met de Bernoulli waarschijnlijkheid p (1) = 1/3 en rust met p(0) = 2/3. Een monsters van het door het nemen van een uniform verdeeld willekeurig getal y, en plug het in de omgekeerde cumulatieve verdelingsfunctie, die in dit geval de step-functie dorste op 2/3. De inverse function = { 0 if x <= 2/3, 1 if x > 2/3 }
Helmholtz machines zijn vroege inspiraties voor de variationele Auto Encoders. Het is 2 netwerken gecombineerd in één-voorwaartse gewichten werkt herkenning en achterwaartse gewichten implementeert verbeelding. Het is misschien het eerste netwerk dat beide doet. Helmholtz werkte niet in machine learning, maar hij inspireerde de visie van “statistical inference engine whose function is to infer probability causes of sensory input” (3). het stochastische binaire neuron geeft een kans dat zijn toestand 0 of 1 is. De gegevensinvoer wordt normaal gesproken niet als een laag beschouwd, maar in de Helmholtz – machinegeneratiemodus ontvangt de datalaag input van de middelste laag heeft aparte gewichten voor dit doel, dus wordt het als een laag beschouwd. Daarom heeft dit netwerk 3 lagen.Variational Autoencoder (VAE) zijn geïnspireerd door Helmholtz machines en combineert waarschijnlijkheidsnetwerk met neurale netwerken. Een Autoencoder is een 3-layer CAM-netwerk, waarbij de middelste laag een interne representatie van invoerpatronen moet zijn. De gewichten worden phi & theta genoemd in plaats van W en V zoals in Helmholtz – een cosmetisch verschil. Het neurale encodernetwerk is een kansverdeling qφ (z / x) en het decodernetwerk is pθ(x|z). Deze 2 netwerken hier kunnen volledig worden aangesloten, of gebruik maken van een andere NN-regeling.het klassieke voorbeeld van unsupervised learning in the study of neural networks is Donald Hebb ‘ s principe, dat wil zeggen, neuronen die samen vuren draad samen. In het Hebbiaanse leren wordt de verbinding versterkt ongeacht een fout, maar is uitsluitend een functie van het samenvallen van actiepotentialen tussen de twee neuronen. Een soortgelijke versie die synaptische gewichten wijzigt, houdt rekening met de tijd tussen de actiepotentialen (spike-timing-afhankelijke plasticiteit of STDP). Er wordt verondersteld dat het hebbiaanse leren ten grondslag ligt aan een reeks cognitieve functies, zoals patroonherkenning en ervaringsleer.
tussen neurale netwerkmodellen worden de zelforganiserende kaart (SOM) en de adaptieve resonantietheorie (ART) vaak gebruikt in niet-begeleide leeralgoritmen. De SOM is een topografische organisatie waarin nabijgelegen locaties op de kaart inputs met vergelijkbare eigenschappen vertegenwoordigen. Het ART-model staat het aantal clusters toe om met probleemgrootte te variëren en laat de gebruiker de mate van gelijkenis tussen leden van dezelfde clusters controleren door middel van een gebruikergedefinieerde constante die de waakzaamheidsparameter wordt genoemd. KUNSTNETWERKEN worden gebruikt voor vele patroonherkenningstaken, zoals automatische doelherkenning en seismische signaalverwerking.