
w tym samouczku nauczysz się regresji logistycznej. Tutaj dowiesz się, czym dokładnie jest regresja logistyczna, a także zobaczysz przykład z Pythonem. Regresja logistyczna jest ważnym tematem uczenia maszynowego i postaram się to uprościć.
na początku XX wieku regresja logistyczna była używana głównie w biologii, później była używana w niektórych zastosowaniach nauk społecznych. Jeśli jesteś ciekawy, możesz zapytać, gdzie powinniśmy zastosować regresję logistyczną? Używamy regresji logistycznej, gdy nasza zmienna niezależna jest kategoryczna.
przykłady:
- aby przewidzieć, czy dana osoba kupi samochód (1) lub (0)
- aby wiedzieć, czy guz jest złośliwy (1) lub (0)
rozważmy teraz scenariusz, w którym musisz sklasyfikować, czy dana osoba kupi samochód, czy nie. W tym przypadku, jeśli użyjemy prostej regresji liniowej, będziemy musieli określić próg, na którym można dokonać klasyfikacji.
powiedzmy, że rzeczywistą klasą jest osoba, która kupi samochód, a przewidywana wartość ciągła wynosi 0,45, a próg, który rozważaliśmy, wynosi 0.5, następnie ten punkt danych będzie uważany za osobę, która nie kupi samochodu, a to doprowadzi do niewłaściwej prognozy.
więc wnioskujemy, że nie możemy użyć regresji liniowej dla tego typu problemu klasyfikacji. Jak wiemy regresja liniowa jest ograniczona, więc tutaj pojawia się regresja logistyczna, gdzie wartość ściśle waha się od 0 do 1.
prosta regresja logistyczna:
Wyjście: 0 LUB 1
hipoteza: K = W * X + b
hΘ(x) = esica(K)
funkcja esicy:


rodzaje regresji logistycznej:
binarna regresja logistyczna
tylko dwa możliwe wyniki(Kategoria).
przykład: osoba kupi samochód lub nie.
regresja logistyczna
Więcej niż dwie kategorie możliwe bez zamawiania.
porządkowa regresja logistyczna
przy zamówieniu możliwe są więcej niż dwie kategorie.
rzeczywisty przykład z Pythonem:
teraz rozwiążemy rzeczywisty problem z regresją logistyczną. Mamy zestaw danych zawierający 5 kolumn a mianowicie: identyfikator użytkownika, płeć,wiek, szacowany i zakupiony. Teraz musimy zbudować model, który potrafi przewidzieć, czy na danym parametrze osoba kupi samochód, czy nie.
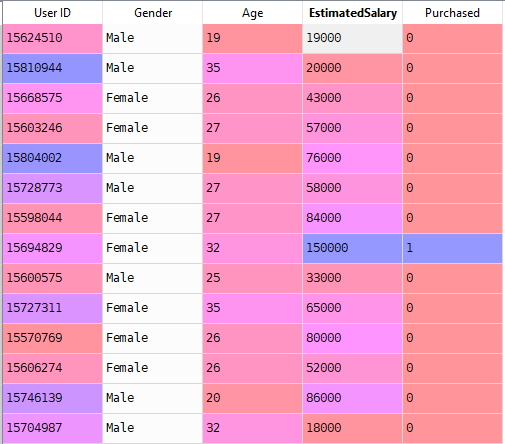
kroki do zbudowania modelu:
1. Importing the libraries
tutaj zaimportujemy biblioteki, które będą potrzebne do zbudowania modelu.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
zaimportujemy nasz zestaw danych do zmiennej (tj. zbioru danych) za pomocą pand.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
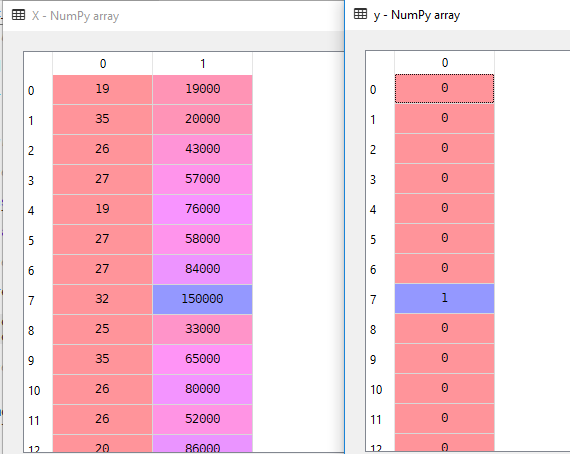
w naszym zbiorze danych weźmiemy pod uwagę wiek i oszacowanie jako zmienną niezależną i zakupioną jako zmienną zależną.
X = dataset.iloc].valuesy = dataset.iloc.valuestutaj X jest zmienną niezależną, a y zmienną zależną.
3. Splitting the Data set into the Training Set and Test Set
teraz podzielimy nasz zestaw danych na dane treningowe i dane testowe. Dane szkoleniowe zostaną wykorzystane do szkolenia naszego modelu logistycznego ,a dane testowe zostaną wykorzystane do walidacji naszego modelu. Użyjemy Sklearn do podziału naszych danych. Zaimportujemy train_test_split ze sklepu.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
teraz wykonamy skalowanie funkcji, aby skalować nasze dane między 0 a 1, Aby uzyskać lepszą dokładność.
tutaj skalowanie jest ważne, ponieważ istnieje ogromna różnica między wiekiem a szacowanym wiekiem.
- Import StandardScaler ze sklepu.preprocessing
- następnie utwórz instancję sc_X obiektu StandardScaler
- następnie dopasuj i przekształć X_train i przekształć X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
teraz zbudujemy nasz klasyfikator (logistyczny).
- Import LogisticRegression ze sklepu.linear_model
- tworzy klasyfikator instancji obiektu LogisticRegression i daje
random_state = 0, aby uzyskać ten sam wynik za każdym razem. - teraz Użyj tego klasyfikatora, aby dopasować X_train i y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Pozdrawiam!! Po wykonaniu powyższego polecenia będziesz miał klasyfikator, który może przewidzieć, czy dana osoba kupi samochód, czy nie.
teraz użyj klasyfikatora, aby przewidzieć zestaw danych testowych i znaleźć dokładność za pomocą macierzy pomieszania.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)teraz otrzymamy y_pred

teraz możemy użyć y_test (rzeczywisty wynik) i y_pred ( przewidywany wynik), aby uzyskać dokładność naszego modelu.
7. Making the Confusion Matrix
używając macierzy splątania możemy uzyskać dokładność naszego modelu.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)otrzymasz matrycę cm .

użyj cm, aby obliczyć dokładność, jak pokazano poniżej:
Accuracy = ( cm + cm) /(Total test data points)

tutaj otrzymujemy dokładność 89 % . Zdrowie!! mamy dobrą celność.
na koniec Zwizualizujemy wynik zestawu treningowego i wynik zestawu testowego. Użyjemy matplotliba do wykreślenia naszego zbioru danych.
Wizualizacja wyniku zestawu treningowego
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()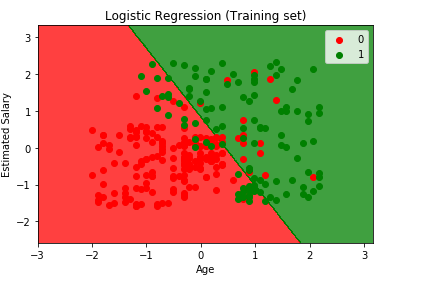
Wizualizacja wyniku zestawu testowego
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
teraz możesz zbudować własny klasyfikator regresji logistycznej.
dzięki!! Koduj !!
uwaga: jest to post gościnny,a opinia w tym artykule jest autorstwa gościa. Jeśli masz jakiekolwiek problemy z którymś z artykułów zamieszczonych na www.marktechpost.com please contact at [email protected]
Advertisement
