wszyscy użytkownicy baz danych wiedzą o zwykłych funkcjach agregujących, które działają na całej tabeli i są używane z klauzulą GROUP BY. Ale bardzo niewiele osób korzysta z funkcji okien w SQL. Działają one na zbiorze wierszy i zwracają pojedynczą zagregowaną wartość dla każdego wiersza.
główną zaletą korzystania z funkcji okiennych nad zwykłymi funkcjami zbiorczymi jest: Funkcje okna nie powodują, że wiersze są pogrupowane w jeden wiersz wyjściowy, wiersze zachowują swoje oddzielne tożsamości, a zagregowana wartość zostanie dodana do każdego wiersza.
przyjrzyjmy się, jak działają funkcje Window, a następnie zobaczmy kilka przykładów użycia ich w praktyce, aby mieć pewność, że wszystko jest jasne, a także jak SQL i wyjście porównują się do funkcji SUM ().
jak zawsze upewnij się, że masz pełną kopię zapasową, zwłaszcza jeśli próbujesz nowych rzeczy z bazą danych.
Wprowadzenie do funkcji okna
funkcje okna działają na zbiorze wierszy i zwracają pojedynczą zagregowaną wartość dla każdego wiersza. Okno term opisuje zbiór wierszy w bazie danych, na których będzie działać funkcja.
definiujemy okno (zbiór wierszy, na którym działają funkcje) za pomocą klauzuli OVER (). Więcej o klauzuli OVER() omówimy w poniższym artykule.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Kiedy dołączysz wszystko, zliczy się wszystkie wartości, w tym zduplikowane. DISTINCT nie jest wspierany w funkcjach okna
wyrażenie
kolumna docelowa lub wyrażenie, na którym działają funkcje. Innymi słowy, nazwa kolumny, dla której potrzebujemy zagregowanej wartości. Na przykład kolumna zawierająca kwotę zamówienia, abyśmy mogli zobaczyć całkowitą liczbę otrzymanych zamówień.
OVER
określa klauzule okna dla funkcji agregujących.
PARTITION BY partition_list
definiuje okno (zbiór wierszy, na którym działa funkcja window) dla funkcji window. Musimy podać pole lub listę pól dla partycji po klauzuli PARTITION BY. Wiele pól musi być oddzielonych przecinkiem, jak zwykle. Jeśli partycja by nie jest określona, grupowanie zostanie wykonane na całej tabeli, a wartości zostaną odpowiednio zagregowane.
ORDER BY order_list
sortuje wiersze w obrębie każdej partycji. Jeśli ORDER BY nie jest określony, ORDER BY używa całej tabeli.
przykłady
stwórzmy tabelę i wstawmy puste rekordy, aby pisać kolejne zapytania. Uruchom poniżej kodu.
funkcje zbiorcze okna
SUM ()
wszyscy znamy funkcję zbiorczą SUM (). Wykonuje sumę podanego pola dla podanej grupy (np. miasto, stan, kraj itp.) lub dla całej tabeli, jeżeli grupa nie jest określona. Zobaczymy, co będzie wynikiem funkcji sumowania regularnego sum () i sumowania okna ().
poniżej znajduje się przykład regularnej funkcji sumowania (). Sumuje kwotę zamówienia dla każdego miasta.
z zestawu wyników widać, że zwykła funkcja agregująca grupuje wiele wierszy w jeden wiersz wyjściowy, co powoduje, że poszczególne wiersze tracą swoją tożsamość.
|
1
2 tym celu należy wybrać miasto, sumę(order_amount) total_order_amount
wybierz miasto, suma (order_amount) total_order_amount
od . Grupuj według miast
|

nie ma to miejsca w przypadku funkcji agregowania okien. Wiersze zachowują swoją tożsamość, a także pokazują zagregowaną wartość dla każdego wiersza. W poniższym przykładzie zapytanie robi to samo, a mianowicie agreguje dane dla każdego miasta i pokazuje sumę całkowitej kwoty zamówienia dla każdego z nich. Jednak zapytanie wstawia teraz kolejną kolumnę dla całkowitej kwoty zamówienia, tak aby każdy wiersz zachował swoją tożsamość. Kolumna oznaczona grand_total jest nową kolumną w poniższym przykładzie.
AVG ()
AVG lub średnia działa w dokładnie taki sam sposób z funkcją okna.
poniższe zapytanie da ci średnią kwotę zamówienia dla każdego miasta i dla każdego miesiąca (chociaż dla uproszczenia użyliśmy danych tylko w ciągu jednego miesiąca).
określamy więcej niż jedną średnią, określając wiele pól na liście partycji.
warto również zauważyć, że można używać wyrażeń na listach takich jak MONTH (order_date), jak pokazano w poniższym zapytaniu. Jak zawsze możesz uczynić te wyrażenia tak złożonymi, jak chcesz, o ile składnia jest poprawna!
z powyższego zdjęcia wyraźnie widać, że średnio otrzymaliśmy zamówienia w wysokości 12,333 dla Arlington city na Kwiecień 2017.
średnia kwota zamówienia = całkowita kwota zamówienia/całkowite zamówienia
= (20,000 + 15,000 + 2,000) / 3
= 12,333
Możesz również użyć kombinacji SUM() & funkcja COUNT() do obliczenia średniej.
MIN ()
funkcja agregująca MIN() znajdzie minimalną wartość dla określonej grupy lub dla całej tabeli, jeśli grupa nie jest określona.
na przykład szukamy najmniejszego zamówienia (minimalnego zamówienia) dla każdego miasta, które użyjemy następującego zapytania.
MAX ()
tak jak funkcje MIN() dają minimalną wartość, funkcja MAX() określi największą wartość określonego pola dla określonej grupy wierszy lub dla całej tabeli, jeśli grupa nie jest określona.
znajdźmy największe zamówienie (maksymalną kwotę zamówienia) dla każdego miasta.
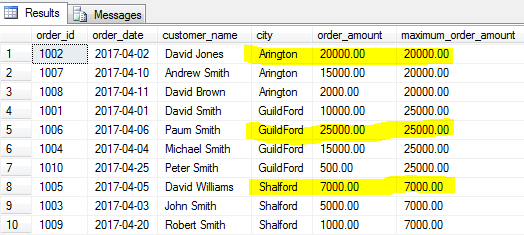
COUNT ()
funkcja COUNT() zliczy rekordy / wiersze.
zauważ, że DISTINCT nie jest wspierany przez funkcję window COUNT (), podczas gdy jest wspierany przez zwykłą funkcję COUNT (). Funkcja DISTINCT pomaga znaleźć różne wartości określonego pola.
na przykład, jeśli chcemy zobaczyć, ilu klientów złożyło zamówienie w kwietniu 2017 r., nie możemy bezpośrednio policzyć wszystkich klientów. Możliwe, że ten sam klient złożył wiele zamówień w tym samym miesiącu.
COUNT(customer_name) da ci niepoprawny wynik, ponieważ zliczy duplikaty. Natomiast COUNT (DISTINCT customer_name) da ci poprawny wynik, ponieważ liczy każdego unikalnego klienta tylko raz.
ważne dla regularnej funkcji COUNT ():
|
1
2 tym celu należy wybrać miasto,liczbę(distinct customer_name) number_of_customers
from .
Grupuj według miast
|
nieprawidłowe dla funkcji window COUNT ():
powyższe zapytanie z funkcją Window spowoduje poniższy błąd.
teraz znajdźmy całkowitą kolejność odebraną dla każdego miasta za pomocą funkcji window COUNT ().
Ranking funkcji okna
tak jak funkcje agregujące okno agregują wartość określonego pola, funkcje rankingowe będą klasyfikować wartości określonego pola i kategoryzować je zgodnie z ich rankingiem.
najczęstszym zastosowaniem funkcji rankingowych jest znalezienie top (N) rekordów na podstawie określonej wartości. Na przykład 10 najlepiej opłacanych pracowników, 10 najlepszych studentów, 50 największych zamówień itp.
obsługiwane są następujące funkcje rankingowe:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
omówmy je jeden po drugim.
RANK ()
funkcja RANK() służy do nadawania unikalnej rangi każdemu rekordowi na podstawie określonej wartości, na przykład wynagrodzenia, kwoty zamówienia itp.
Jeśli dwa rekordy mają tę samą wartość, funkcja RANK() przypisze tę samą rangę do obu rekordów, pomijając następną rangę. Oznacza to-jeśli istnieją dwie identyczne wartości w rank 2, przypisze tę samą rangę 2 do obu rekordów, a następnie pominie rangę 3 i przypisze rangę 4 do następnego rekordu.
uszeregujmy każde zamówienie według ich ilości.
|
1
2
3
4
5
|
WYBIERZ id zamówienia, datę zamówienia, nazwę klienta, miasto,
RANK() WYŻEJ(KOLEJNOŚĆ PO kolei, PO kolei)
OD .
|
z powyższego obrazka widać, że ta sama ranga (3) jest przypisana do dwóch identycznych rekordów (każdy z zamówieniem o wartości 15 000), a następnie pomija kolejną rangę (4) i przydziela rangę 5 do następnego rekordu.
dense_rank ()
funkcja DENSE_RANK() jest identyczna z funkcją RANK() z tym wyjątkiem, że nie pomija żadnej rangi. Oznacza to, że jeśli zostaną znalezione dwa identyczne rekordy, to dense_rank() przypisze tę samą rangę do obu rekordów, ale nie pominie, a następnie pominie następną rangę.
zobaczmy, jak to działa w praktyce.
jak widać powyżej, ta sama ranga jest nadawana dwóm identycznym rekordom (każdy o tej samej wartości zamówienia), a następnie kolejny numer rangi jest nadawany kolejnemu rekordowi bez pomijania wartości rangi.
ROW_NUMBER ()
nazwa jest oczywista. Funkcje te przypisują unikalny numer wiersza do każdego rekordu.
numer wiersza zostanie zresetowany dla każdej partycji, jeśli partycja By jest określona. Zobaczmy, jak ROW_NUMBER () działa bez partycji by, a następnie z partycją by.
ROW_ NUMBER() bez partycji przez
ROW_NUMBER() z partycją przez
zauważ, że zrobiliśmy partycję na city. Oznacza to, że numer wiersza jest resetowany dla każdego miasta i tak ponownie uruchamia się na 1. Jednak kolejność wierszy jest określona przez kwotę zamówienia, tak że dla danego miasta największą ilością zamówienia będzie pierwszy wiersz i tak przypisany numer wiersza 1.
NTILE ()
NTILE() jest bardzo pomocną funkcją okna. Pomaga określić, do jakiego percentyla (lub kwartyla lub innego podpodziału) wpada dany wiersz.
oznacza to, że jeśli masz 100 wierszy i chcesz utworzyć kwartyle 4 na podstawie określonego pola wartości, możesz to łatwo zrobić i zobaczyć, ile wierszy przypada na każdy kwartyl.
zobaczmy przykład. W poniższym zapytaniu określiliśmy, że chcemy utworzyć cztery kwartyle na podstawie kwoty zamówienia. Następnie chcemy zobaczyć, ile zamówień przypada na każdy kwartyl.
NTILE tworzy płytki na podstawie następującego wzoru:
Liczba wierszy w każdym kafelku = liczba wierszy w zestawie wyników / liczba podanych kafelków
oto nasz przykład, mamy łącznie 10 wierszy i 4 kafelki są określone w zapytaniu, więc liczba wierszy w każdym kafelku wyniesie 2.5 (10/4). Jako liczba wierszy powinna być liczbą całkowitą, a nie dziesiętną. SQL engine przypisze 3 wiersze dla pierwszych dwóch grup i 2 Wiersze dla pozostałych dwóch grup.
funkcje okna wartości
LAG() i LEAD ()
funkcje LEAD() I LAG() są bardzo potężne, ale mogą być skomplikowane do wyjaśnienia.
ponieważ jest to artykuł wprowadzający poniżej, patrzymy na bardzo prosty przykład, aby zilustrować, jak z nich korzystać.
funkcja LAG umożliwia dostęp do danych z poprzedniego wiersza w tym samym zestawie wyników bez użycia żadnych złączeń SQL. Możesz zobaczyć w poniższym przykładzie, używając funkcji LAG znaleźliśmy poprzednią datę zamówienia.
skrypt do wyszukiwania daty poprzedniego zamówienia za pomocą funkcji LAG ():
funkcja LEAD umożliwia dostęp do danych z następnego wiersza w tym samym zestawie wyników bez użycia żadnych złączeń SQL. Możesz zobaczyć w poniższym przykładzie, używając funkcji LEAD znaleźliśmy datę następnego zamówienia.
skrypt do znajdowania daty następnego zamówienia za pomocą funkcji LEAD ():
FIRST_VALUE() i LAST_VALUE ()
funkcje te pomagają zidentyfikować pierwszy i ostatni rekord na partycji lub całej tabeli, jeśli partycja by nie jest określona.
znajdźmy pierwszą i ostatnią kolejność każdego miasta z naszego istniejącego zbioru danych. Uwaga klauzula ORDER BY jest obowiązkowa dla funkcji FIRST_VALUE() i LAST_VALUE ()
z powyższego obrazu wyraźnie widać, że pierwsze zamówienie otrzymane w dniu 2017-04-02 i ostatnie zamówienie otrzymane w dniu 2017-04-11 dla Arlington city i działa to tak samo dla innych miast.
Przydatne linki
- typy kopii zapasowych & strategie baz danych SQL
- TechNet artykuł na temat klauzuli OVER
- MSDN artykuł na temat DENSE_RANK
inne świetne artykuły z Ben
jak SQL Server wybiera ofiarę impasu
Jak aby korzystać z funkcji okna
- autor
- ostatnie posty
Zobacz wszystkie posty Bena Richardsona
- Power BI: wykresy wodospadów i połączone wizualizacje-styczeń 19, 2021
- Power BI: Formatowanie warunkowe i kolory danych w akcji – 14 stycznia 2021 r.
- Power BI: Importowanie danych z SQL Server i MySQL – 12 stycznia 2021 r.