Rozpoznawanie twarzy-krok po kroku
zmierzmy się z tym problemem krok po kroku. Dla każdego kroku poznamy inny algorytm uczenia maszynowego. Nie zamierzam całkowicie wyjaśniać każdego algorytmu, aby nie zamienić go w książkę, ale poznasz główne idee każdego z nich i dowiesz się, jak możesz zbudować własny system rozpoznawania twarzy w Pythonie za pomocą OpenFace i dlib.
Krok 1: Znalezienie wszystkich twarzy
pierwszym krokiem w naszym rurociągu jest wykrywanie twarzy. Oczywiście musimy zlokalizować twarze na zdjęciu, zanim spróbujemy je odróżnić!
jeśli używałeś jakiejkolwiek kamery w ciągu ostatnich 10 lat, prawdopodobnie widziałeś detekcję twarzy w akcji:

wykrywanie twarzy to świetna funkcja dla kamer. Gdy aparat może automatycznie wybrać twarze, może upewnić się, że wszystkie twarze są w ostrości, zanim zrobi zdjęcie. Ale użyjemy go do innego celu-znalezienia obszarów obrazu, które chcemy przekazać do następnego kroku w naszym rurociągu.
wykrywanie twarzy stało się powszechne na początku 2000 roku, kiedy Paul Viola i Michael Jones wynaleźli sposób wykrywania twarzy, który był wystarczająco szybki, aby działał na tanich kamerach. Jednak obecnie istnieją znacznie bardziej niezawodne rozwiązania. Użyjemy metody wynalezionej w 2005 roku zwanej histogramem zorientowanych gradientów – w skrócie HOG.
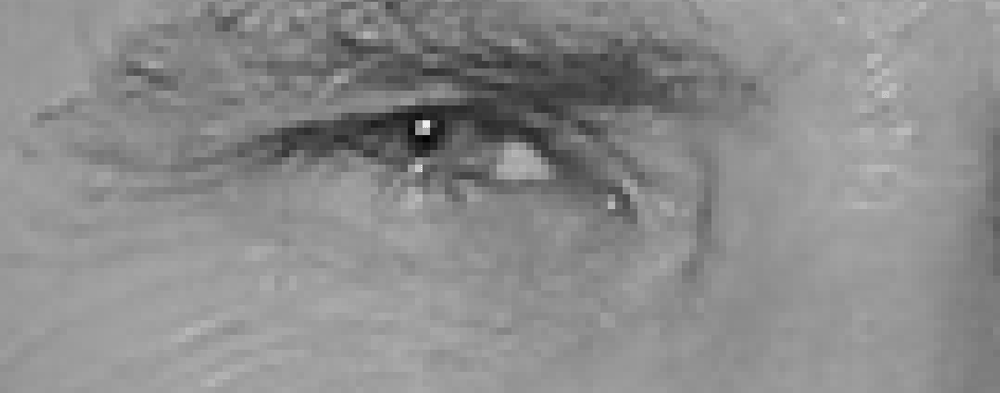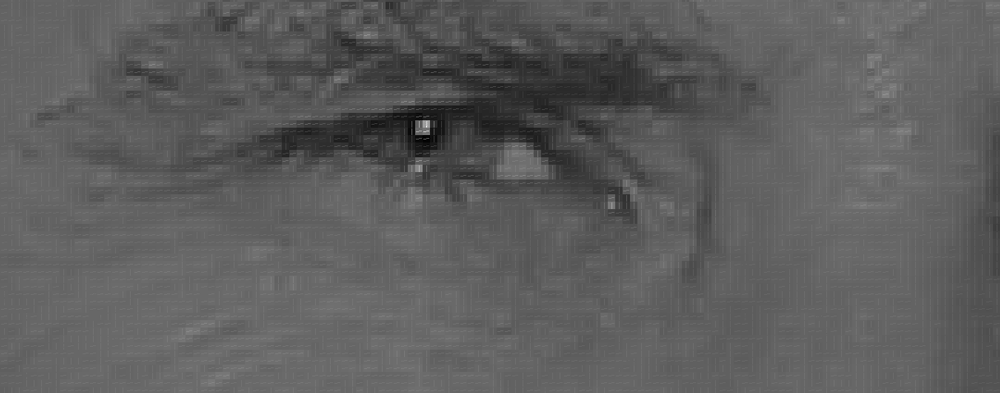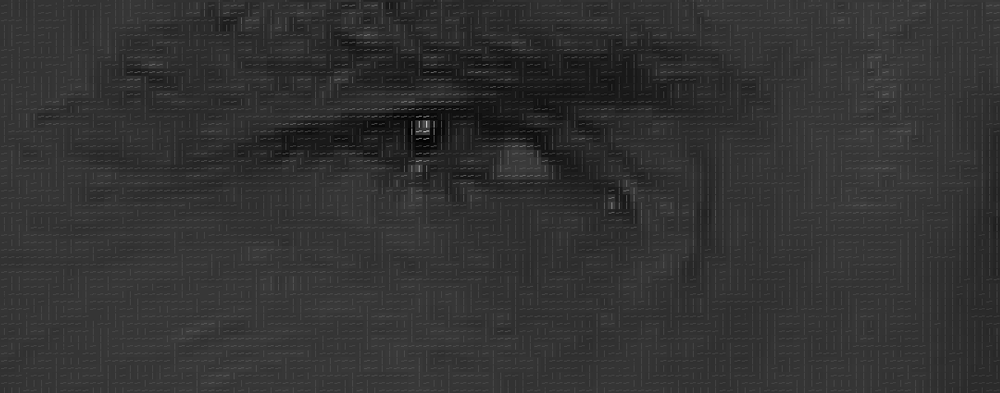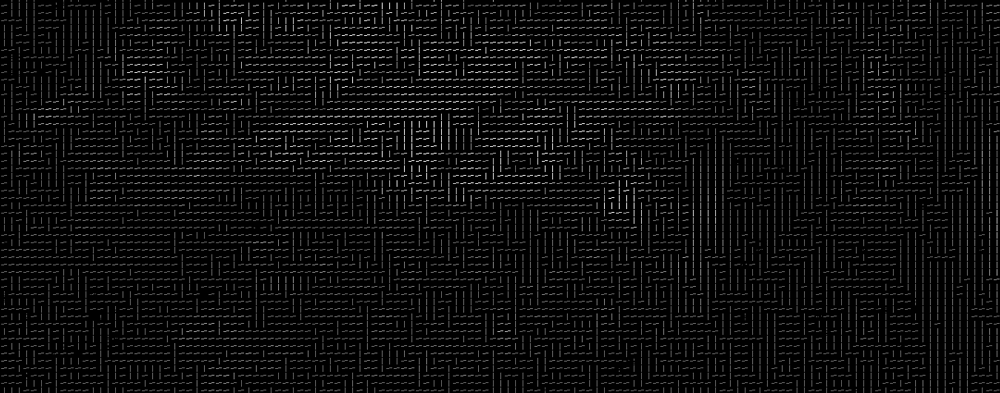
aby znaleźć twarze w obrazie, zaczniemy od uczynienia naszego obrazu czarno-białym, ponieważ nie potrzebujemy danych kolorów, aby znaleźć twarze:

wtedy będziemy patrzeć na każdy pojedynczy piksel w naszym obrazie po kolei. Dla każdego pojedynczego piksela chcemy przyjrzeć się pikselom, które bezpośrednio go otaczają:

naszym celem jest sprawdzenie, jak ciemny jest bieżący piksel w porównaniu z pikselami bezpośrednio otaczającymi go. Następnie chcemy narysować strzałkę pokazującą, w którym kierunku obraz staje się ciemniejszy:

jeśli powtórzysz ten proces dla każdego pojedynczego piksela na obrazie, każdy piksel zostanie zastąpiony strzałką. Strzałki te nazywane są gradientami i pokazują przepływ światła do ciemności na całym obrazie:
to może wydawać się przypadkową rzeczą do zrobienia, ale jest naprawdę dobry powód, aby zastąpić piksele gradientami. Jeśli przeanalizujemy bezpośrednio piksele, naprawdę ciemne i naprawdę jasne obrazy tej samej osoby będą miały zupełnie inne wartości pikseli. Ale biorąc pod uwagę tylko kierunek, w którym zmienia się jasność, zarówno naprawdę ciemne obrazy, jak i naprawdę jasne obrazy będą miały tę samą dokładną reprezentację. To sprawia, że problem jest o wiele łatwiejszy do rozwiązania!
ale zapisanie gradientu dla każdego pojedynczego piksela daje nam o wiele za dużo szczegółów. Brakuje nam lasu dla drzew. Byłoby lepiej, gdybyśmy mogli po prostu zobaczyć podstawowy przepływ światła/ciemności na wyższym poziomie, abyśmy mogli zobaczyć podstawowy wzór obrazu.
aby to zrobić, podzielimy obraz na małe kwadraty o wymiarach 16×16 pikseli każdy. W każdym kwadracie policzymy, ile gradientów wskazuje w każdym głównym kierunku (ile punktów w górę, punkt w górę-w prawo, punkt w prawo itp.). Następnie zastąpimy ten kwadrat na obrazie kierunkami strzałek, które były najsilniejsze.
rezultatem jest przekształcenie oryginalnego obrazu w bardzo prostą reprezentację, która w prosty sposób oddaje podstawową strukturę twarzy:

aby znaleźć twarze na tym obrazku Wieprza, wystarczy znaleźć część naszego obrazu, która wygląda najbardziej podobnie do znanego wzorca Wieprza, który został wyodrębniony z kilku innych twarzy treningowych:

korzystając z tej techniki, możemy teraz łatwo znaleźć twarze na dowolnym obrazie:

Jeśli chcesz wypróbować ten krok samodzielnie za pomocą Pythona i dlib, oto kod pokazujący, jak generować i wyświetlać reprezentacje Hog obrazów.
Krok 2: pozowanie i wyświetlanie twarzy
UFF, wyizolowaliśmy twarze na naszym obrazie. Ale teraz mamy do czynienia z problemem, że twarze odwrócone w różnych kierunkach wyglądają zupełnie inaczej do komputera:

aby to wyjaśnić, postaramy się wypaczyć każde zdjęcie tak, aby oczy i usta były zawsze w miejscu próbki na obrazie. To znacznie ułatwi nam porównywanie twarzy w kolejnych krokach.
aby to zrobić, użyjemy algorytmu o nazwie face landmark estimation. Jest na to wiele sposobów, ale wykorzystamy podejście wynalezione w 2014 roku przez Vahida Kazemi i Josephine Sullivan.
podstawową ideą jest to, że wymyślimy 68 konkretnych punktów (zwanych punktami orientacyjnymi), które istnieją na każdej twarzy — górna część podbródka, zewnętrzna krawędź każdego oka, wewnętrzna krawędź każdej brwi itp. Następnie wytrenujemy algorytm uczenia maszynowego, aby móc znaleźć te 68 konkretnych punktów na dowolnej twarzy:

oto wynik zlokalizowania 68 punktów orientacyjnych twarzy na naszym obrazie testowym:

: Możesz również użyć tej samej techniki, aby zaimplementować własną wersję Snapchat w czasie rzeczywistym 3D filtry twarzy!
teraz, gdy wiemy, że są oczy i usta, po prostu obracamy, skalujemy i ścinamy obraz, aby oczy i usta były wyśrodkowane jak najlepiej. Nie będziemy robić żadnych fantazyjnych wypaczeń 3d, ponieważ wprowadzałoby to zniekształcenia do obrazu. Będziemy używać tylko podstawowych przekształceń obrazu, takich jak obrót i Skala, które zachowują równoległe linie (zwane transformacjami afinicznymi):

teraz bez względu na to, jak odwrócona jest Twarz, jesteśmy w stanie wyśrodkować oczy i usta w mniej więcej tej samej pozycji na obrazie. To sprawi, że nasz następny krok będzie o wiele dokładniejszy.
Jeśli chcesz wypróbować ten krok samodzielnie za pomocą Pythona i dlib, oto kod do znajdowania punktów orientacyjnych twarzy i oto kod do przekształcania obrazu za pomocą tych punktów orientacyjnych.
Krok 3: Kodowanie twarzy
teraz jesteśmy do mięsa problemu-właściwie odróżnianie twarzy od siebie. Tutaj robi się naprawdę interesująco!
najprostszym podejściem do rozpoznawania twarzy jest bezpośrednie porównanie nieznanej twarzy znalezionej w Kroku 2 ze wszystkimi zdjęciami osób, które zostały już oznaczone. Kiedy znajdziemy wcześniej oznaczoną twarz, która wygląda bardzo podobnie do naszej nieznanej twarzy, musi to być ta sama osoba. To chyba dobry pomysł, prawda?
z takim podejściem jest duży problem. Strona taka jak Facebook z miliardami użytkowników i bilionem zdjęć nie może być w stanie przejrzeć każdej wcześniej oznaczonej twarzy, aby porównać ją z każdym nowo przesłanym zdjęciem. To by trwało zbyt długo. Muszą umieć rozpoznać twarze w milisekundach, a nie w godzinach.
to, czego potrzebujemy, to sposób na wyodrębnienie kilku podstawowych pomiarów z każdej twarzy. Wtedy moglibyśmy zmierzyć naszą nieznaną twarz w ten sam sposób i znaleźć znaną twarz z najbliższymi pomiarami. Na przykład możemy zmierzyć rozmiar każdego ucha, odstęp między oczami, długość nosa itp. Jeśli kiedykolwiek oglądałeś zły serial kryminalny, taki jak CSI, wiesz o czym mówię:
najbardziej niezawodny sposób pomiaru twarzy
ok, więc jakie pomiary powinniśmy zebrać z każdej twarzy, aby zbudować naszą znaną bazę danych twarzy? Rozmiar ucha? Długość nosa? Kolor oczu? Coś jeszcze?
okazuje się, że pomiary, które wydają się nam ludziom oczywiste (np. kolor oczu) nie mają sensu dla komputera oglądającego poszczególne piksele na obrazie. Naukowcy odkryli, że najdokładniejszym podejściem jest pozwolić komputerowi obliczyć pomiary, aby zebrać się. Uczenie głębokie lepiej sprawdza się niż ludzie w ustalaniu, które części twarzy są ważne do zmierzenia.
rozwiązaniem jest trenowanie głębokiej sieci neuronowej (tak jak w części 3). Ale zamiast trenować sieć do rozpoznawania obrazów obiektów, jak poprzednio, będziemy trenować ją do generowania 128 pomiarów dla każdej twarzy.
proces szkolenia polega na patrzeniu na 3 obrazy twarzy naraz:
- załaduj treningowy obraz twarzy znanej osoby
- załaduj kolejne zdjęcie tej samej znanej osoby
- Załaduj zdjęcie zupełnie innej osoby
następnie algorytm patrzy na pomiary, które obecnie generuje dla każdego z tych trzech obrazów. Następnie zmienia nieco sieć neuronową, aby upewnić się, że pomiary, które generuje dla #1 i #2, są nieco bliżej, podczas gdy pomiary dla #2 i #3 są nieco dalej od siebie:

po milionach powtórzeń tego kroku dla milionów obrazów tysięcy różnych osób, sieć neuronowa uczy się niezawodnie generować 128 pomiarów dla każdej osoby. Każde dziesięć różnych zdjęć tej samej osoby powinno dać mniej więcej takie same wymiary.
Uczenie maszynowe ludzie nazywają 128 pomiarów każdej twarzy osadzeniem. Idea redukcji skomplikowanych surowych danych, takich jak obraz, do listy generowanych komputerowo liczb, pojawia się często w uczeniu maszynowym (zwłaszcza w tłumaczeniach językowych). Dokładne podejście do twarzy, którego używamy, zostało wynalezione w 2015 roku przez naukowców z Google, ale istnieje wiele podobnych podejść.
kodowanie naszego obrazu twarzy
ten proces szkolenia konwolucyjnej sieci neuronowej do wyprowadzania osadzania twarzy wymaga dużej ilości danych i mocy komputera. Nawet w przypadku drogiej karty graficznej Nvidia Telsa, uzyskanie dobrej dokładności zajmuje około 24 godzin ciągłego szkolenia.
ale po przeszkoleniu sieć może generować pomiary dla każdej twarzy, nawet takiej, jakiej nigdy wcześniej nie widziała! Więc ten krok trzeba zrobić tylko raz. Na szczęście dla nas, dobrzy ludzie z OpenFace już to zrobili i opublikowali kilka wyszkolonych sieci, z których możemy bezpośrednio korzystać. Dzięki Brandon Amos i zespół!
więc wszystko, co musimy zrobić sami, to przepuścić nasze obrazy twarzy przez ich wstępnie przeszkoloną sieć, aby uzyskać 128 pomiarów dla każdej twarzy. Oto pomiary dla naszego obrazu testowego:

więc jakie dokładnie są te 128 liczb? Okazuje się, że nie mamy pojęcia. To nie ma dla nas znaczenia. Zależy nam tylko na tym, że sieć generuje prawie te same liczby, gdy patrzy się na dwa różne zdjęcia tej samej osoby.
Jeśli chcesz wypróbować ten krok samodzielnie, OpenFace udostępnia skrypt lua, który wygeneruje osadzenie wszystkich obrazów w folderze i zapisze je do pliku csv. Tak to robisz.
Krok 4: znalezienie nazwy osoby z kodowania
ten ostatni krok jest w rzeczywistości najłatwiejszym krokiem w całym procesie. Wszystko, co musimy zrobić, to znaleźć osobę w naszej bazie znanych osób, która ma najbliższe pomiary do naszego obrazu testowego.
Możesz to zrobić za pomocą dowolnego podstawowego algorytmu klasyfikacji uczenia maszynowego. Nie są potrzebne żadne wymyślne sztuczki deep learning. Użyjemy prostego liniowego klasyfikatora SVM, ale wiele algorytmów klasyfikacji może działać.
wszystko, co musimy zrobić, to wytrenować klasyfikator, który może pobierać pomiary z nowego obrazu testowego i informować, która znana osoba jest najbliżej dopasowana. Uruchomienie tego klasyfikatora zajmuje milisekundy. Wynikiem klasyfikacji jest imię i nazwisko osoby!
wypróbujmy więc nasz system. Najpierw wyszkoliłem klasyfikatora z umieszczeniem około 20 zdjęć, każdy z Willem Ferrellem, Chadem Smithem i Jimmym Falonem: