
neste tutorial, Você vai aprender a Regressão Logística. Aqui você saberá exatamente o que é Regressão Logística e também verá um exemplo com Python. Regressão logística é um tópico importante de aprendizagem de máquinas e vou tentar torná-lo o mais simples possível.
no início do século XX, regressão logística foi usada principalmente em Biologia depois disso, foi usado em algumas aplicações de Ciências Sociais. Se você está curioso, você pode perguntar onde devemos usar regressão logística? Então usamos regressão logística quando nossa variável independente é categórica.exemplos:
- Para prever se uma pessoa vai comprar um carro (1) ou (0)
- Para saber se o tumor é maligno (1) ou (0)
Agora, vamos considerar um cenário onde você tem que classificar se uma pessoa vai comprar um carro ou não. Neste caso, se usarmos regressão linear simples, precisaremos especificar um limiar sobre o qual a classificação pode ser feita.
digamos que a classe real é a pessoa que vai comprar o carro, e o valor contínuo previsto é 0,45 eo limiar que temos considerado é 0.5, então este ponto de dados será considerado como a pessoa não vai comprar o carro e isso levará à previsão errada.
então concluímos que não podemos usar regressão linear para este tipo de problema de classificação. Como sabemos a regressão linear é limitada, então aqui vem a regressão logística onde o valor varia estritamente de 0 a 1.
Simples de Regressão Logística:
Saída: 0 ou 1
Hipótese: K = W * X + B
hΘ(x) = sigmóide(K)
Função Sigmóide:


Tipos de Regressão Logística:
Binário de Regressão Logística
Apenas dois resultados possíveis(Categoria).exemplo: a pessoa vai comprar um carro ou não.
Regressão Logística Multinomial
Mais de duas categorias possíveis sem ordenação.
Regressão Logística Ordinal
Mais de duas categorias possíveis com a ordenação.
Real-world Example with Python:
Now we’ll solve a real-world problem with Logistic Regression. Temos um conjunto de dados com 5 colunas, a saber: ID do utilizador, sexo, idade, salário estimado e comprado. Agora temos que construir um modelo que pode prever se no parâmetro dado uma pessoa vai comprar um carro ou não.
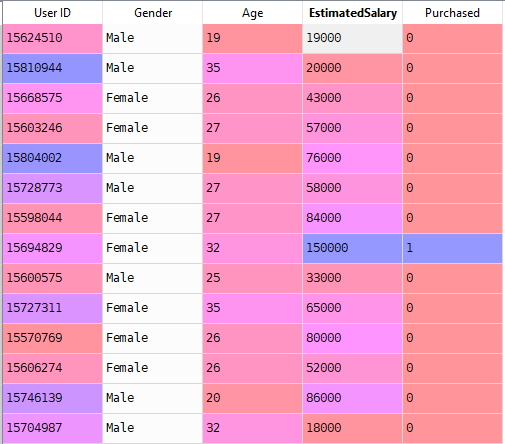
passos para construir o modelo:
1. Importing the libraries
Aqui importaremos bibliotecas que serão necessárias para construir o modelo.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
importaremos o nosso conjunto de dados numa variável (I. E. dataset) usando pandas.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
No nosso conjunto de Dados vamos considerar a Idade e EstimatedSalary como variável Independente e Comprado como Variável Dependente.
X = dataset.iloc].valuesy = dataset.iloc.valuesAqui X é variável independente e y é variável dependente.
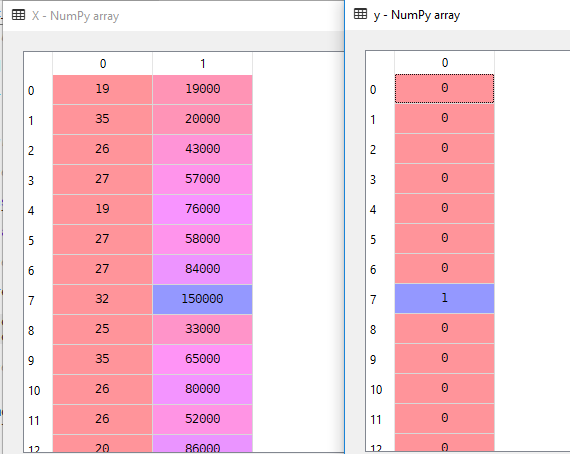
3. Splitting the Data set into the Training Set and Test Set
Agora, vamos dividir o nosso conjunto de Dados para os Dados de Treinamento e Dados de Teste. Os dados de treinamento serão usados para treinar o nosso modelo logístico e os dados de teste serão usados para validar o nosso modelo. Vamos usar o Sklearn para dividir os nossos dados. Vamos importar o comboio do sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
Agora vamos fazer recurso de escala para escala de nossos dados entre 0 e 1, para obter melhor precisão.a escala aqui é importante porque há uma enorme diferença entre a idade e o salário estimado.
- importar um escalador padrão de sklearn.pré-processamento
- , em Seguida, faça uma instância sc_X do objeto StandardScaler
- , em Seguida, ajuste e transformação X_train e transformar X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Agora vamos criar o nosso classificador (Logística).
- importar a regressão logística do sklearn.linear_model
- Make an instance classifier of the object LogisticRegression and give
random_state = 0 to get the same result every time. - Agora utilizar este classificador para caber X_train e y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Cheers!! Depois de executar o comando acima você terá um classificador que pode prever se uma pessoa vai comprar um carro ou não.
Agora use o classificador para fazer a previsão para o conjunto de dados de teste e encontrar a precisão usando a matriz de confusão.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)Agora nós vamos chegar y_pred

Agora podemos usar y_test (Resultado Real) e y_pred ( Resultado Previsto) para obter a precisão do modelo.
7. Making the Confusion Matrix
Usando matriz de confusão podemos obter precisão do nosso modelo.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)você vai ter uma matriz cm .

Use cm para calcular a precisão, como mostrado abaixo:
a Precisão = ( cm + cm ) / ( Total de dados de teste pontos )

Aqui estamos chegando a precisão de 89 % . Saúde!! estamos a obter uma boa precisão.finalmente, Visualizaremos o resultado do nosso conjunto de treino e o resultado do conjunto de testes. Vamos usar matplotlib para traçar o nosso conjunto de dados.
Visualizando o Conjunto de Treinamento com resultado
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()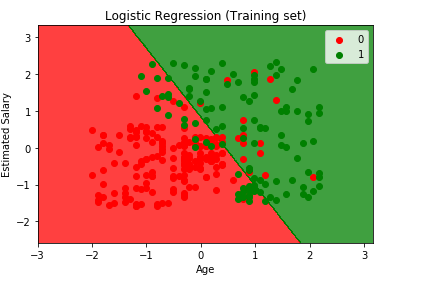
Visualizando o Conjunto de Teste resultado
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Agora Você pode construir seu próprio classificador para a Regressão Logística.obrigado!! Continua A Codificar !!
Nota: Este é um post convidado, e a opinião neste artigo é do escritor convidado. Se tiver algum problema com algum dos artigos publicados na www.marktechpost.com please contact at [email protected]
Advertisement
