o que é a expressão Regular em Python?
uma expressão Regular (RE) em uma linguagem de programação é uma cadeia de texto especial usada para descrever um padrão de busca. É extremamente útil para extrair informações de texto, tais como código, arquivos, log, planilhas ou até mesmo documentos.
ao usar a expressão regular em Python, a primeira coisa é reconhecer que tudo é essencialmente um carácter, e estamos a escrever padrões para corresponder a uma sequência específica de caracteres também referida como string. ASCII ou letras latinas são aquelas que estão em seus teclados e Unicode é usado para combinar com o texto estrangeiro. Ele inclui dígitos e pontuação e todos os caracteres especiais como $#@!%, etc.
neste tutorial regex em Python, iremos aprender –
- sintaxe de expressão Regular
- Exemplo de W+ e ^ expressão
- Exemplo de expressão \s em re.dividir a função
- usando métodos de expressão regular
- usando re.corresponder ()
- procurar o padrão no texto (re.search ()
- usando re.findall para text
- Python Flags
- Exemplo de re.Opções m ou multi-linhas
por exemplo, uma expressão regular em Python poderia dizer a um programa para procurar por texto específico a partir da string e, em seguida, para imprimir o resultado de acordo. A expressão pode incluir
- texto correspondente a
- repetição
- composição Padrão, etc.
ramificação
a expressão Regular ou a expressão regular em Python são indicadas como RE (REs, regexes ou padrão regex) são importadas através do módulo re. O Python suporta a expressão regular através das bibliotecas. RegEx em Python suporta várias coisas como modificadores, identificadores e caracteres de espaço branco.
| Identificadores | Modificadores | caracteres de espaço em Branco | Escape necessário |
|---|---|---|---|
| \d= qualquer número (um dígito) | \d representa um dígito.Ex: ele vai declarar um dígito entre 1,5 como 424.444,545, etc. | \N = nova linha | . + * ? $ ^ () {} | \ |
| \d= tudo menos um número (um não-dígito) | + = fósforos 1 ou mais | \ s = Espaço | |
| \s = Espaço (tab,space,newline etc.) | ? = matches 0 or 1 | \t =tab | |
| \S= anything but a space | * = 0 or more | \e = escape | |
| \w = letters ( Match alphanumeric character, including “_”) | $ match end of a string | \r = carriage return | |
| \W =anything but letters ( Matches a non-alphanumeric character excluding “_”) | ^ match start of a string | \f= form feed | |
| . = anything but letters (periods) | | matches either or x/y | —————– | |
| \b = any character except for new line | = range or “variance” | —————- | |
| \. | {x} = esta quantidade de código anterior | —————– |
Expressão Regular(RE) Sintaxe
import re
- “re” módulo incluído com o Python usado principalmente para a cadeia de procura e manipulação
- Também usado com freqüência para a página da web “Raspagem” (extrair grande quantidade de dados de sites)
Vamos começar a expressão tutorial com este exercício simples usando as expressões (w+) e (^). exemplo de W + e ^ expressão
- “^”: Esta expressão corresponde ao início de uma cadeia de caracteres
- “w+”: esta expressão corresponde ao carácter alfanumérico na cadeia de caracteres
aqui veremos um exemplo em Python de como podemos usar a expressão w+ e ^ no nosso código. Nós cobrimos a função re.findall () em Python, mais tarde neste tutorial, mas por um tempo nós simplesmente focamos em \W+ e \^ expressão.
Por exemplo, para a nossa string “guru99, a educação é divertida” se executarmos o código com w+ e^, ele dará a saída “guru99”.
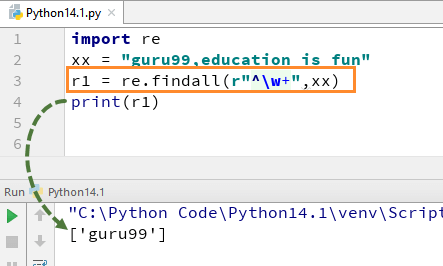
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print(r1)
lembre-se, se você remover +sinal do w+, o resultado irá mudar, e só irá dar o primeiro carácter da primeira letra, ou seja,
exemplo de expressão \s em re.função de divisão
- “s”: esta expressão é usada para criar um espaço na cadeia de caracteres
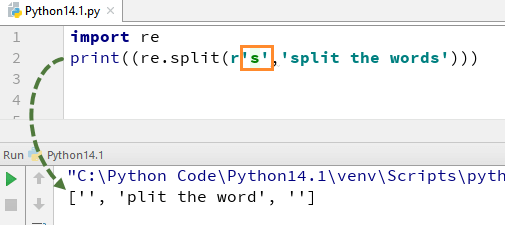
para compreender como esta expressão em Python funciona, começamos com um exemplo simples de uma função de divisão em Python. No exemplo, dividimos cada palavra usando o ” re.dividir ” função e, ao mesmo tempo, temos usado expressões \s que permite processar cada palavra na cadeia separadamente.

quando você executar este código, ele lhe dará o resultado .
agora, vamos ver o que acontece se você remover “\” de s. Não existe nenhum alfabeto ‘s’ na saída, isto é porque removemos ‘\’ da cadeia, e ele avalia “s” como um caractere regular e, assim, divide as palavras onde quer que ele encontre “s” na cadeia.
Similarly, there are series of other Python regular expression that you can use in various ways in Python like \d,\d,$,\., \ b, etc.
Aqui está o código completo
a seguir, vamos ver os tipos de métodos que são usados com expressão regular em Python.
usando métodos de expressão regular
o pacote ” re ” fornece vários métodos para realmente realizar consultas em uma cadeia de entrada. Veremos os métodos de re em Python:
- re.match ()
- re.search ()
- re.nota: com base nas expressões regulares, o Python oferece duas operações primitivas diferentes. O método de correspondência verifica uma correspondência apenas no início do texto, enquanto a pesquisa verifica uma correspondência em qualquer lugar do texto.
re.match ()
re.a função match () Do re em Python irá procurar no padrão de expressão regular e devolver a primeira ocorrência. O método de correspondência RegEx Python verifica uma correspondência apenas no início do texto. Então, se uma correspondência for encontrada na primeira linha, devolve o objecto da correspondência. Mas se uma correspondência for encontrada em alguma outra linha, a função de correspondência RegEx Python retorna nula.
por exemplo, considere o seguinte código de Python re.função match (). A expressão “w+” e “\w “irá corresponder às palavras que começam com a letra” g “e, posteriormente, qualquer coisa que não seja iniciada com” g ” não é identificada. Para verificar a correspondência de cada elemento da lista ou texto, executamos o forloop neste Python re.match () exemplo.

re.search (): Finding Pattern in Text
re.a função search () irá procurar o padrão de expressão regular e devolve a primeira ocorrência. Ao contrário do Python re.match (), irá verificar todas as linhas do texto de entrada. O Python re.a função search () devolve um objecto correspondente quando o padrão é encontrado e “nulo” se o padrão não for encontrado
para usar a função search (), terá de importar primeiro o módulo Python re e depois executar o código. O Python re.a função search () toma o “padrão” e o “texto” para digitalizar a partir da nossa cadeia principal
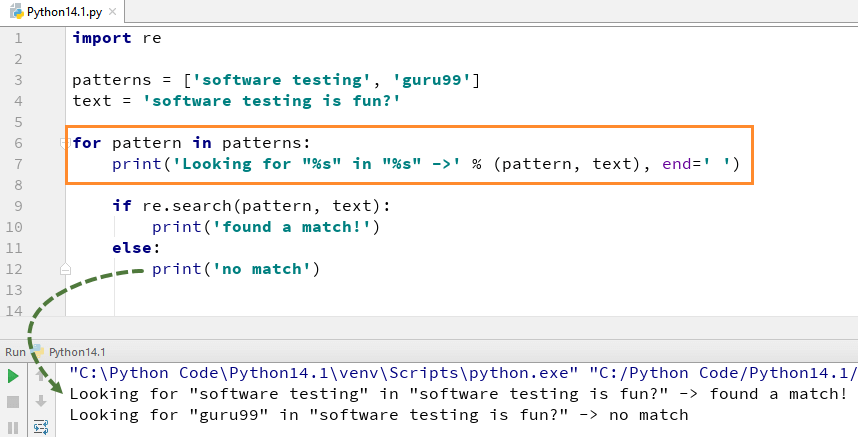
por exemplo aqui nós procuramos duas cadeias literais de “Software testing” “guru99”, em uma cadeia de texto “Software Testing is fun”. Para “software testing”nós encontramos a correspondência, portanto ele retorna a saída de Python re.search () Example as “found a match”, while for word “guru99” we could not found in string hence it returns the output as “No match”.
re.o módulo findall()
findall() é usado para procurar por “todas” ocorrências que correspondam a um dado padrão. Em contraste, o módulo search() só irá devolver a primeira ocorrência que corresponda ao padrão especificado. o findall () irá iterar todas as linhas do ficheiro e irá devolver todas as combinações não sobrepostas de padrões num único passo.
por exemplo, aqui temos uma lista de endereços de E-mail, e queremos que todos os endereços de E-mail sejam obtidos a partir da lista, usamos o método re.findall () em Python. Ele vai encontrar todos os endereços de E-mail da lista.
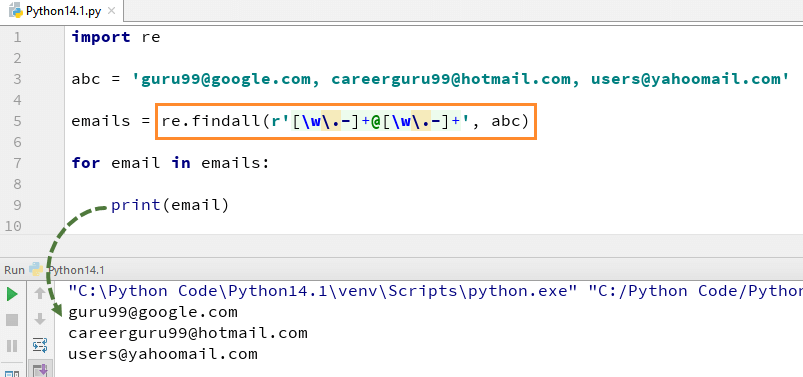
Aqui está o código completo, por exemplo de re.findall ()
import relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print((z.groups())) patterns = text = 'software testing is fun?'for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!')else: print('no match')abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print(email)Python Flags
muitos métodos de Regex Python e funções Regex tomam um argumento opcional chamado Flags. Estas opções podem modificar o significado do padrão de Expressões Regulares em Python. Para compreendê-los, veremos um ou dois exemplos dessas bandeiras.
Various flags used in Python includes
Syntax for Regex Flags What does this flag do Make begin/end consider each line It ignores case Make Make { \w,\W,\b,\B} follows Unicode rules Make {\w,\W,\b,\B} follow locale Allow comment in Regex Example of re.As opções m ou multi-linha
em multi-linha, o carácter padrão corresponde ao primeiro carácter da cadeia de caracteres e ao início de cada linha (a seguir imediatamente após cada linha nova). Enquanto a expressão pequena ” w ” é usada para marcar o espaço com caracteres. Quando você executa o código, a primeira variável “k1” só imprime o caractere ‘g’ para o word guru99, enquanto quando você adiciona a bandeira multi-linha, ele obtém os primeiros caracteres de todos os elementos do texto.
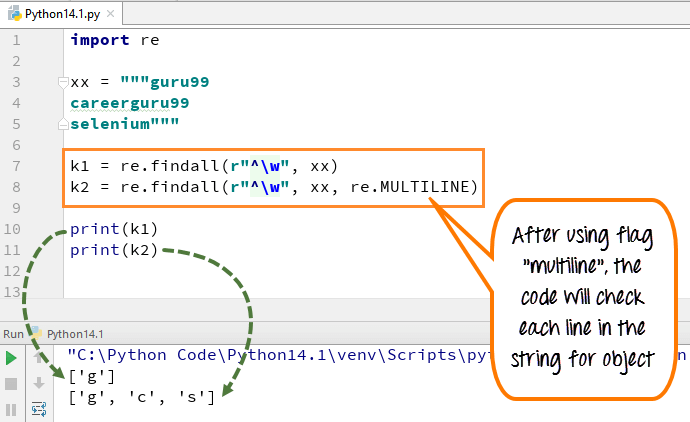
Aqui está o código
import rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print(k1)print(k2)
- que declaramos a variável xx para a cadeia ” guru99…. careerguru99….selênio”
- Executar o código sem o uso de bandeiras de várias linhas, dá a saída apenas ‘g’ do as linhas
- Executar o código com o sinalizador “multiline”, quando você imprime ‘k2’ dá a saída como ‘g’, ‘c’ e ‘s’
- Assim, a diferença podemos ver depois e antes da adição de multi-linhas no exemplo acima.
da mesma forma, você também pode usar outras opções em Python como re.U (Unicode), re.L (Follow locale), re.X (permitir comentário), etc.
exemplo em Python 2
acima os códigos são exemplos em Python 3, Se quiser correr em Python 2, por favor considere o seguinte código.
# Example of w+ and ^ Expressionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print r1# Example of \s expression in re.split functionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print (re.split(r'\s','we are splitting the words'))print (re.split(r's','split the words'))# Using re.findall for textimport relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print(z.groups()) patterns = text = 'software testing is fun?'for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!'else: print 'no match'abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print email# Example of re.M or Multiline Flagsimport rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print k1print k2resumo
uma expressão regular numa linguagem de programação é uma cadeia de texto especial usada para descrever um padrão de pesquisa. Ele inclui dígitos e pontuação e todos os caracteres especiais como $#@!%, etc. A expressão pode incluir literalmente
- correspondência de texto
- repetição
ramificação
- composição Padrão, etc.
em Python, uma expressão regular é denotada como RE (REs, regexes ou padrão regex) são incorporados através do módulo Python re.
- “re” módulo incluído com Python usado principalmente para pesquisa e manipulação de strings
- Também usado frequentemente para a página web “raspagem” (extrair grande quantidade de dados de sites)
- Os Métodos de expressão Regular incluem re.match (), re.search ()& re.findall()
- Outros Python RegEx substituir métodos são sub() e subn (), que são utilizados para substituir cadeias de caracteres correspondentes no re
- Python Bandeiras Muitos Python Regex Métodos e funções Regex tomar um argumento opcional chamado Bandeiras
- Este sinalizadores podem modificar o significado de um determinado padrão Regex
- Vários Python sinalizadores usados em Regex Métodos de re.M, re.Eu, re.S, etc.