todos os utilizadores da base de dados conhecem as funções agregadas regulares que operam numa tabela inteira e são usadas com um grupo por cláusula. Mas muito poucas pessoas usam funções de janelas em SQL. Estes operam em um conjunto de linhas e retornam um único valor agregado para cada linha.
A principal vantagem de usar as funções da janela sobre as funções agregadas regulares é: As funções da janela não fazem com que as linhas se tornem agrupadas numa única linha de saída, as linhas mantêm as suas identidades separadas e um valor agregado será adicionado a cada linha.
vamos dar uma olhada em como as funções da janela funcionam e, em seguida, ver alguns exemplos de usá-lo na prática para ter certeza de que as coisas são claras e também como o SQL e saída se comparam a isso para funções SUM ().
Como sempre, certifique-se de que você está totalmente backup, especialmente se você está experimentando coisas novas com o seu banco de dados.
Introdução às funções da janela
as funções da janela funcionam num conjunto de linhas e devolvem um único valor agregado para cada linha. A janela do termo descreve o conjunto de linhas na base de dados em que a função irá operar.
definimos a janela (conjunto de linhas nas quais as funções operam) usando uma cláusula OVER (). Discutiremos mais sobre a cláusula de OVER() no artigo abaixo.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Quando você vai incluir tudo, ele vai contar todos os valores, incluindo os duplicados. DISTINCT não é suportado nas funções da janela
expressão
a coluna-alvo ou expressão em que as funções operam. Em outras palavras, o nome da coluna para a qual precisamos de um valor agregado. Por exemplo, uma coluna contendo a quantidade de ordem para que possamos ver as encomendas totais recebidas.
OVER
especifica as cláusulas de janela para funções agregadas.
A partição por partition_ list
define a janela (conjunto de linhas em que a função da janela Opera) para as funções da janela. Precisamos fornecer um campo ou lista de campos para a partição após a partição por cláusula. Vários campos precisam ser separados por uma vírgula, como de costume. Se a partição por não for especificada, o agrupamento será feito na tabela inteira e os valores serão agregados em conformidade.
ordem por order_ list
ordena as linhas dentro de cada partição. Se a ordem por não for especificada, a ordem por usa a tabela inteira.
exemplos
vamos criar tabelas e inserir registros fictícios para escrever mais consultas. Corre abaixo do Código.
funções agregadas de janelas
soma ()
Todos conhecemos a função agregada soma (). Ele faz a soma do campo especificado para grupos específicos (como cidade, estado, país, etc.) ou para toda a tabela, se o grupo não for especificado. Veremos qual será a saída da função agregada soma regular() e da função agregada soma da janela ().
o seguinte é um exemplo de uma soma regular () função agregada. Ela soma o valor da ordem para cada cidade.
pode ver a partir do conjunto de resultados que uma função agregada regular agrupa várias linhas numa única linha de saída, o que faz com que as linhas individuais percam a sua identidade.
|
1
2
3
4
|
SELECIONE cidade, SOMA(order_amount) total_order_amount
a PARTIR de . GRUPO PELA cidade
|

Isso não acontece com a janela de funções de agregação. As linhas retêm a sua identidade e também mostram um valor agregado para cada linha. No exemplo abaixo a consulta Faz a mesma coisa, ou seja, agrega os dados para cada cidade e mostra a soma do valor total da ordem para cada uma delas. No entanto, a consulta agora insere outra coluna para a quantidade total de ordem de modo que cada linha mantém a sua identidade. A coluna marcada grand_total é a nova coluna no exemplo abaixo.
AVG ()
AVG ou o AVG Médio funciona exactamente da mesma forma com uma função de janela.
a seguinte consulta irá dar-lhe a quantidade média de pedidos para cada cidade e para cada mês (embora, para simplificar, nós só usamos dados em um mês).
especificamos mais de uma média, especificando vários campos na lista de partições.
também vale a pena notar que você pode usar expressões nas listas como o mês(order_ data), como mostrado na consulta abaixo. Como sempre, você pode tornar essas expressões tão complexas quanto quiser, desde que a sintaxe esteja correta!
da imagem acima, podemos ver claramente que, em média, recebemos encomendas de 12.333 para Arlington city em abril de 2017.
valor médio da ordem = montante Total da ordem / total das ordens
= (20,000 + 15,000 + 2,000) / 3
= 12,333
Você também pode usar a combinação da função SUM() & COUNT() para calcular uma média.
MIN ()
a função agregada MIN () irá encontrar o valor mínimo para um grupo especificado ou para toda a tabela se o grupo não for especificado.
Por exemplo, estamos procurando a menor ordem (ordem mínima) para cada cidade que usaríamos a seguinte consulta.
MAX()
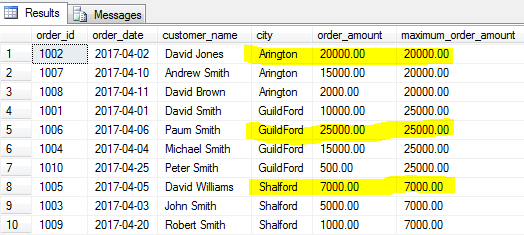
assim como o MIN() funções dá-lhe o valor mínimo, o MAX (), a função de identificar o maior valor de um campo especificado para um determinado grupo de linhas ou para a tabela inteira se um grupo não é especificado.
let’s find the biggest order (maximum order amount) for each city.
ontagem ()
A função Contagem() contará os registos / linhas.
Note que DISTINCT não é suportado com a função Contagem de janelas() enquanto que é suportado para a função Contagem regular (). DISTINCT ajuda você a encontrar os valores distintos de um campo especificado. por exemplo, se queremos ver quantos clientes fizeram uma encomenda em abril de 2017, não podemos contar diretamente todos os clientes. É possível que o mesmo cliente tenha feito várias encomendas no mesmo mês.
COUNT (personaler_name) dar-lhe-á um resultado incorrecto, dado que irá contar duplicados. Considerando que a contagem (customer_name distinto) lhe dará o Resultado Correto, uma vez que conta cada cliente único apenas uma vez.
válido para a função de contagem regular() :
|
1
2
3
4
5
|
SELECIONE cidade,COUNT(DISTINCT customer_name) number_of_customers
a PARTIR de .
GROUP BY cidade
|
Inválida para a janela da função COUNT ():
A consulta acima com função de Janela irá dar-lhe abaixo erro.
Agora, vamos encontrar a ordem total recebida para cada cidade usando a função window COUNT ().
Ranking Funções da Janela
assim como a Janela de funções de agregação agregado o valor de um campo especificado, funções de CLASSIFICAÇÃO serão calculados os valores de um campo especificado e categorizá-los de acordo com a sua classificação.
O uso mais comum das funções de classificação é encontrar os registros de topo (N) com base em um determinado valor. Por exemplo, os 10 funcionários mais bem pagos, os 10 melhores classificados, os 50 maiores pedidos, etc.
as seguintes são funções de classificação suportadas:
RANK (), DENSE_RANK (), ROW_NUMBER (), NTILE()
vamos discuti-las uma a uma.
RANK ()
a função RANK () é usada para dar uma classificação única a cada registro com base em um valor especificado, por exemplo salário, valor de ordem, etc.
Se dois registros têm o mesmo valor, então a função RANK() irá atribuir o mesmo rank para ambos os registros, saltando o próximo rank. Isto significa-se existem dois valores idênticos no rank 2, ele vai atribuir o mesmo rank 2 para ambos os registros e, em seguida, pular rank 3 e atribuir rank 4 para o próximo registro.
vamos classificar cada ordem pela sua quantidade de ordem.
|
1
2
3
4
5
|
SELECIONE order_id,order_date,customer_name,cidade,
RANK() OVER(FIM POR order_amount DESC)
a PARTIR de .
|
a Partir da imagem acima, você pode ver que o mesmo valor (3) é atribuído a dois registros idênticos (cada uma com um valor da ordem de 15.000) e, em seguida, salta para a próxima posição (4) e atribuir uma classificação de 5 para o próximo registo.
DENSE_RANK ()
a função DENSE_RANK() é idêntica à função RANK (), exceto que não salta qualquer rank. Isto significa que se dois registros idênticos forem encontrados, então DENSE_RANK () irá atribuir o mesmo rank para ambos os registros, mas não pular, em seguida, pular o próximo rank.vamos ver como isto funciona na prática.
Como você pode ver claramente acima, o mesmo posto é dado a dois registros idênticos (cada um com a mesma quantidade de ordem) e então o número de posto seguinte é dado para o próximo registro sem saltar um valor de posto.
ROW_NUMBER ()
o nome é auto-explicativo. Estas funções atribuem um número de linha único a cada registro.
O número da linha será reinicializado para cada partição se a partição Por for especificada. Vamos ver como o ROW_NUMBER () funciona sem partição por e, em seguida, com partição por.
ROW_ (NÚMERO) sem PARTIÇÃO
ROW_NUMBER() com PARTIÇÃO POR
Observe que temos feito a partição na cidade. Isto significa que o número da linha é reiniciado para cada cidade e assim recomeça em 1 novamente. No entanto, a ordem das linhas é determinada pela quantidade de ordem de modo que para qualquer cidade dada a maior quantidade de ordem será a primeira linha e assim atribuída a linha número 1.
NTILE ()
NTILE () é uma função de janela muito útil. Ele ajuda você a identificar em que percentil (ou quartil, ou qualquer outra subdivisão) uma dada linha cai.
isto significa que se tiver 100 linhas e quiser criar 4 quartis com base num campo de valores especificado, poderá fazê-lo facilmente e ver quantas linhas caem em cada quartil. vejamos um exemplo. Na consulta abaixo, especificamos que queremos criar quatro quartis com base na quantidade de ordem. Então queremos ver quantas ordens caem em cada quartil.
NTILE cria ladrilhos com base na seguinte fórmula:
Nenhum de linhas em cada tile = número de linhas no conjunto de resultados / número de peças especificado
Aqui é o nosso exemplo, temos o total de 10 linhas e 4 peças são especificados na consulta para o número de linhas em cada bloco será de 2,5 (10/4). As number of rows should be whole number, not a decimal. O motor SQL irá atribuir 3 linhas para os dois primeiros grupos e 2 linhas para os restantes dois grupos.
funções de janela de valor
LAG () e funções de chumbo ()
LEAD() e LAG() são muito poderosas, mas podem ser complexas para explicar. como este é um artigo introdutório abaixo, estamos olhando para um exemplo muito simples para ilustrar como usá-los.
a função LAG permite acessar dados da linha anterior no mesmo conjunto de resultados sem o uso de qualquer junção SQL. Você pode ver em baixo exemplo, usando a função LAG encontramos data de pedido anterior.
Script to find previous order date using LAG () function:
LEAD function allows to access data from the next row in the same result set without use of any SQL joins. Você pode ver em baixo exemplo, usando a função LEAD nós encontramos a próxima data de ordem.
Script para encontrar a próxima data para o uso de CHUMBO() função:
FIRST_VALUE() e LAST_VALUE()
Estas funções ajudam você a identificar o primeiro e o último registro dentro de uma partição ou toda a tabela, se a PARTIÇÃO não é especificado.
vamos encontrar a primeira e última ordem de cada cidade a partir do nosso conjunto de dados existente. Nota cláusula ORDER BY é obrigatória para FIRST_VALUE() e LAST_VALUE funções ()
a Partir da imagem acima, podemos ver claramente que a primeira ordem recebida no 2017-04-02 e última ordem recebida no 2017-04-11 para Arlington cidade e funciona da mesma para outras cidades.
Links
- Tipos de Cópia de segurança & Estratégias para Bancos de dados SQL
- Artigo da TechNet sobre a Cláusula
- o Artigo do MSDN Sobre DENSE_RANK
Outras grandes artigos de Ben
Como o SQL Server seleciona uma vítima de deadlock
Como Usar Funções de Janela
- Autor
- Posts Recentes
Ver todos os posts por Ben Richardson
- fonte de Alimentação BI: Cachoeira Gráficos e Combinado Visuais – janeiro 19, 2021
- fonte de Alimentação BI: Formatação condicional e cores dos dados em ação-14 de janeiro de 2021
- Power BI: importação de dados do servidor SQL e MySQL-12 de janeiro de 2021