BasicsEdit
em Primeiro lugar, alguns vocabulário:
| ativação | = valor de estado do neurônio. Para neurônios binários, este é geralmente 0 / 1, ou +1 / -1. |
| CAM | = memória endereçável de conteúdo. Recordar uma memória por um padrão parcial em vez de um endereço de memória. |
| convergência | = a estabilização de um padrão de ativação em uma rede. Em SL, convergência significa estabilização de pesos & viases em vez de ativações. |
| discriminativo | = tarefas de reconhecimento. Também chamada análise (em teoria de padrões), ou inferência. |
| energia | = uma quantidade macroscópica descrever o padrão de ativação em uma rede. (veja abaixo) |
| generalização | = comportando-se com precisão sobre previamente não encontrou entradas |
| generativo | = Máquina imaginada e recuperação de tarefas. às vezes chamado de síntese (na teoria do padrão), mimetismo, ou falsos profundos. |
| inferência | = a fase de “execução” (em oposição à formação). Durante a inferência, a rede executa a tarefa que é treinada para fazer-ou reconhecendo um padrão (SL) ou criando um (UL). Normalmente a inferência desce o gradiente de uma função de energia. Em contraste com SL, A descida de gradiente ocorre durante o treinamento, não inferência. |
| machine vision | = machine learning on images. |
| NLP | = Processamento De Linguagem Natural. Aprendizagem mecânica de línguas humanas. |
| padrão | = ativações de rede que tem uma ordem interna em algum sentido, ou que pode ser descrito mais compactamente por características nas ativações. Por exemplo, o padrão de pixels de um zero, seja dado como dados ou imaginado pela rede, tem uma característica que é descritível como um único loop. As características são codificadas nos neurônios escondidos. |
| formação | = fase de aprendizagem. Aqui, a rede ajusta seus pesos & viases para aprender com as entradas. |
Tarefas

UL métodos geralmente preparam uma rede para tarefas gerativas em vez de reconhecimento, mas agrupar tarefas como supervisionadas ou não pode ser nebuloso. Por exemplo, o reconhecimento de caligrafia começou na década de 1980 como SL. Então, em 2007, UL é usado para primear a rede para SL depois. Atualmente, SL recuperou sua posição como o melhor método.
Formação
durante a fase de aprendizagem, uma rede não supervisionada tenta imitar os dados que lhe são dados e usa o erro na sua saída mimada para se corrigir (eg. seus pesos & viases). Isto assemelha-se ao comportamento mimético das crianças enquanto aprendem uma língua. Às vezes o erro é expresso como uma baixa probabilidade de que a saída errada ocorra, ou pode ser expresso como um estado de alta energia instável na rede.uma função de energia é uma medida macroscópica do Estado de uma rede. Esta analogia com a física é inspirada por Ludwig Boltzmann análise de um gás ” macroscópico de energia a partir de microscópicas de probabilidades de partículas de movimento p ∝ {\displaystyle \propto }

eE/kT, onde k é a constante de Boltzmann e T é a temperatura. Na RBM rede se a relação p = e-e / Z, onde p & E variar ao longo do todo o possível padrão de ativação e Z = ∑ A l P a t t e r n a s {\displaystyle \sum _{AllPatterns}}

e-e(padrão). Para ser mais preciso, p(A) = E-E(A) / Z, onde a é um padrão de ativação de todos os neurônios (visível e oculto). Por isso, as primeiras redes neurais têm o nome de máquina Boltzmann. Paul Smolensky chama a harmonia. Uma Rede Busca baixa energia, que é de alta harmonia.
as Redes
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
 |
 autoencoder
|
 variacional autoencoder
|
de Boltzmann e Helmholtz veio antes redes neurais formulações, mas estas redes emprestado a partir de suas análises, de modo que essas redes levará os seus nomes. Hopfield, no entanto, contribuiu diretamente para a UL.
IntermediateEdit
Aqui, as distribuições p (x) e q(x) serão abreviadas como p e Q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. É usado principalmente em SL, mas merece uma menção aqui. |
| 1982 | Ising variant Hopfield net described as CAMs and classifiers by John Hopfield. |
| 1983 | Ising variante de Boltzmann máquina com probabilística neurônios descritos por Hinton & Sejnowski seguinte Sherington & Kirkpatrick 1975 trabalho. |
| 1986 | Paul Smolensky publica A Teoria da Harmonia, que é uma mae com praticamente a mesma função de energia de Boltzmann. Smolensky não deu um esquema de treinamento prático. Hinton did in mid-2000s |
| 1995 | Schmidthuber introduces the LSTM neuron for languages. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| Probabilidade | |
| cdf | = função de distribuição cumulativa. the integral of the pdf. A probabilidade de chegar perto de 3 é a área sob a curva entre 2,9 e 3,1. |
| divergência contrastiva | = um método de aprendizagem em que se reduz a energia sobre os padrões de formação e aumenta a energia sobre os padrões indesejados fora do conjunto de formação. Isto é muito diferente do KL-divergence, mas compartilha uma formulação semelhante. |
| valor esperado | = E(x) = ∑ x {\displaystyle \sum _{x}}
 x * p(x). Este é o valor médio, ou valor médio. Para a entrada contínua x, substitua a soma por uma integral. |
| variável latente | = uma quantidade não observada que ajuda a explicar os dados observados. por exemplo, uma infecção por gripe (não observada) pode explicar por que a pessoa a espirra (observada). Em redes neurais probabilísticas, neurônios ocultos atuam como variáveis latentes, embora sua interpretação latente não seja explicitamente conhecida. |
| = função densidade de probabilidade. A probabilidade de uma variável aleatória assumir um determinado valor. Para pdf contínuo, p(3) = 1/2 ainda pode significar que há quase zero chance de alcançar este valor exato de 3. Racionalizamos isto com a cdf. | |
| stochastic | = comporta-se de acordo com uma fórmula de densidade de probabilidade bem descrita. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. É o trabalho reversível máximo que pode ser realizado por um sistema de calor a temperatura e pressão constantes. energia livre (G = calor – temperatura * entropia |
| informações | = a quantidade de informações de uma mensagem x = -log p(x) |
| KLD | = relativo a entropia. Para redes probabilísticas, este é o análogo do erro entre entrada & saída mimada. A divergência de Kullback-Liebler (KLD) mede o desvio de entropia de 1 distribuição a partir de outra distribuição. KLD(p,q) = ∑ x {\displaystyle \sum _{x}}
p * log( p / p ). Tipicamente, p reflete os dados de entrada, q reflete a interpretação da rede sobre ele, e KLD reflete a diferença entre os dois. |
a Comparação de Redes
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE | |
|---|---|---|---|---|---|---|
| de uso & notáveis | CAM, problema do caixeiro viajante | CAM. A liberdade de conexões torna esta rede difícil de analisar. | reconhecimento de padrões (MNIST, reconhecimento de fala) | imaginação, mimetismo | linguagem: escrita criativa, tradução. Visao: melhorar as imagens desfocadas | gerar dados realistas |
| neurónio | estado binário determinístico. Activation = { 0 (or -1) if x is negative, 1 otherwise } | stochastic binary Hopfield neuron | stochastic binary. Extended to real-valued in mid 2000s | binary, sigmoid | language: LSTM. visão: campos receptivos locais. normalmente, ativação real. | |
| ligações | 1 camada com pesos simétricos. Sem auto-ligações. | 2 camadas. 1-hidden & 1-visible. pesos simétricos. | 2 camadas. pesos simétricos. não há ligações laterais dentro de uma camada. | 3-camadas: pesos assimétricos. 2 redes combinadas em 1. | 3 camadas. A entrada é considerada uma camada, embora não tenha pesos de entrada. camadas recorrentes para NLP. convoluções para a visão. input & output have the same neuron counts. | 3-camadas: entrada, codificador, descodificador de distribuição sampler. o amostrador não é considerado uma camada (e) |
| inferência & energia | energia é dada pela Medida de probabilidade Gibbs : E = − 1 2 ∑ i , j w i j o s i s j + ∑ i θ i s i {\displaystyle E=-{\frac {1}{2}}\sum _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\sum _{eu}{\theta _{i}}{s_{i}}}
 |
← mesmo | ← mesmo | minimizar KL divergência | inferência é apenas de feed-forward. anterior UL redes correu para a frente E para trás | minimizar o erro = reconstrução de erro – KLD |
| treinamento | Δwij = si*sj, para +1/-1 neurônio | Δwij = e*(pij – p’ij). Isto é derivado da minimização do KLD. e = taxa de aprendizagem, p’ = distribuição prevista e p = distribuição real. | contrastiva divergência w/ Gibbs Sampling | acordar-dormir 2 fase de formação | de volta propagar a reconstrução de erro | reparameterize estado oculto para backprop |
| força | semelhante sistemas físicos para herda suas equações | <— mesmo. os neurônios ocultos atuam como representação interna do mundo externo mais rápido esquema de treinamento prático do que as máquinas Boltzmann menos anatômicas. analisável w/ teoria da informação & mecânica estatística | ||||
| fraqueza | hopfield | difícil para treinar devido a lateral de conexões | RBM | Helmholtz |
Redes Específicas
Aqui, destacamos algumas características de cada rede. Ferromagnetismo inspirou redes Hopfield, máquinas Boltzmann e RBMs. Um neurônio corresponde a um domínio de ferro com momentos magnéticos binários para cima e para baixo, e conexões neurais correspondem à influência do domínio um no outro. Conexões simétricas permitem uma formulação de energia global. Durante a inferência, a rede atualiza cada estado usando a função step de ativação padrão. Pesos simétricos garantem convergência a um padrão de ativação estável.as redes Hopfield são usadas como CAMs e são garantidas para se ajustar a algum padrão. Sem pesos simétricos, a rede é muito difícil de analisar. Com a função de energia correta, uma rede convergirá.as máquinas Boltzmann são Redes de Hopfield estocásticas. Seu valor de Estado é amostrado a partir deste pdf da seguinte forma: suponha que um neurônio binário dispara com a probabilidade de Bernoulli p(1) = 1/3 e descansa com p(0) = 2/3. Uma amostra dela, recolhendo um número aleatório uniformemente distribuído y, e colocando-o na função de distribuição cumulativa invertida, que neste caso é a função do degrau debelada em 2/3. A função inversa = {0 if x <= 2/3, 1 if x > 2/3 }
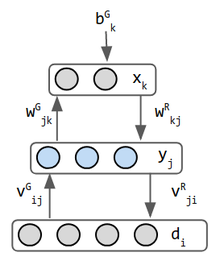
Helmholtz machines are early inspirations for the Variational Auto Encoders. São duas redes combinadas em pesos um-para-a-frente opera o reconhecimento e pesos atrasados implementa a imaginação. É talvez a primeira rede a fazer ambas as coisas. Helmholtz não trabalhou na aprendizagem de máquinas, mas ele inspirou a visão de “motor de inferência estatística cuja função é inferir causas prováveis de entrada sensorial” (3). o neurônio binário estocástico produz uma probabilidade de que seu estado seja 0 ou 1. A entrada de dados normalmente não é considerada uma camada, mas no modo de Geração de máquina Helmholtz, a camada de dados recebe entrada da Camada Média tem pesos separados para esta finalidade, por isso é considerada uma camada. Portanto, esta rede tem 3 camadas.
O Autoencoder variacional (VAE) é inspirado em máquinas Helmholtz e combina rede de probabilidade com redes neurais. Um Autoencoder é uma rede de cames de 3 camadas, onde a camada média é suposto ser alguma representação interna de padrões de entrada. The weights are named phi & theta rather than W and V as in Helmholtz—a cosmetic difference. A rede neural do codificador é uma distribuição de probabilidade qφ (z / x) e a rede decodificadora é pθ(x|z). Estas duas redes aqui podem ser totalmente conectadas, ou usar outro esquema NN.
Hebbian Learning, ART, SOM
The classical example of unsupervised learning in the study of neural networks is Donald Hebb’s principle, that is, neurons that fire together wire together. No aprendizado de Hebbiano, a conexão é reforçada independentemente de um erro, mas é exclusivamente uma função da coincidência entre potenciais de ação entre os dois neurônios. Uma versão similar que modifica os pesos sinápticos leva em conta o tempo entre os potenciais de ação (plasticidade dependente de tempo de spike ou STDP). A aprendizagem de Hebbian tem sido considerada subjacente a uma série de funções cognitivas, tais como reconhecimento de padrões e aprendizagem experiencial.entre os modelos de rede neural, o mapa Auto-organizativo (SOM) e a teoria de ressonância adaptativa (ART) são comumente usados em algoritmos de aprendizagem não supervisionados. O SOM é uma organização topográfica na qual locais próximos no mapa representam entradas com propriedades semelhantes. O modelo de arte permite que o número de clusters varie com o tamanho do problema e permite que o usuário controle o grau de semelhança entre os membros dos mesmos clusters por meio de uma constante definida pelo usuário chamada de parâmetro vigilância. As redes de arte são usadas para muitas tarefas de reconhecimento de padrões, tais como reconhecimento automático de alvos e processamento de sinais sísmicos.