
Klassificeringstekniker är en viktig del av maskininlärning och data mining applikationer. Cirka 70% av problemen inom datavetenskap är klassificeringsproblem. Det finns många klassificeringsproblem som finns tillgängliga, men logistikregressionen är vanlig och är en användbar regressionsmetod för att lösa det binära klassificeringsproblemet. En annan kategori av klassificering är Multinomial klassificering, som hanterar de frågor där flera klasser finns i målvariabeln. Till exempel IRIS dataset ett mycket känt exempel på klassificering i flera klasser. Andra exempel är att klassificera artikel/blogg / dokumentkategori.
logistisk Regression kan användas för olika klassificeringsproblem som spamdetektering. Diabetes förutsägelse, om en viss kund kommer att köpa en viss produkt eller kommer de pressa en annan konkurrent, om användaren kommer att klicka på en viss annons länk eller inte, och många fler exempel är i hinken.
logistisk Regression är en av de enklaste och vanligaste maskininlärningsalgoritmerna för tvåklassig klassificering. Det är lätt att implementera och kan användas som baslinje för alla binära klassificeringsproblem. Dess grundläggande grundläggande begrepp är också konstruktiva i djupt lärande. Logistisk regression beskriver och uppskattar förhållandet mellan en beroende binär variabel och oberoende variabler.
i denna handledning kommer du att lära dig följande saker i logistisk Regression:
- introduktion till logistisk Regression
- linjär Regression Vs. logistisk Regression
- maximal sannolikhetsbedömning Vs. vanlig minsta Kvadratmetod
- hur fungerar logistisk Regression?
- modellbyggnad i Scikit-lär dig
- Modellutvärdering med hjälp av Förvirringsmatris.
- fördelar och nackdelar med logistisk Regression
logistisk Regression
logistisk regression är en statistisk metod för att förutsäga binära klasser. Resultatet eller målvariabeln är dikotom i naturen. Dikotom betyder att det bara finns två möjliga klasser. Det kan till exempel användas för cancerdetekteringsproblem. Det beräknar sannolikheten för en händelse.
det är ett speciellt fall av linjär regression där målvariabeln är kategorisk. Den använder en logg över odds som beroende variabel. Logistic Regression predicts the probability of occurrence of a binary event utilizing a logit function.
Linear Regression Equation:
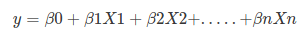
Where, y is dependent variable and x1, x2 … and Xn are explanatory variables.
Sigmoid Function:
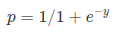
Apply Sigmoid function on linear regression:
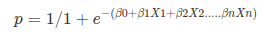
Properties of Logistic Regression:
- den beroende variabeln i logistisk regression följer Bernoulli-fördelningen.
- uppskattning görs genom maximal sannolikhet.
- ingen R-kvadrat, Modell fitness beräknas genom överensstämmelse, KS-statistik.
linjär Regression Vs. logistisk Regression
linjär regression ger dig en kontinuerlig utgång, men logistisk regression ger en konstant utgång. Ett exempel på den kontinuerliga produktionen är huspris och aktiekurs. Exempel på den diskreta utgången är att förutsäga om en patient har cancer eller inte, förutsäga om kunden kommer att churn. Linjär regression uppskattas med vanliga minsta kvadrater (OLS) medan logistisk regression uppskattas med maximal sannolikhetsbedömning (MLE).

maximal Sannolikhetsuppskattning Vs. minsta Kvadratmetod
MLE är en” sannolikhet ” -maximeringsmetod, medan OLS är en approximationsmetod som minimerar avstånd. Maximering av sannolikhetsfunktionen bestämmer de parametrar som mest sannolikt kommer att producera de observerade data. Ur statistisk synvinkel ställer MLE medelvärdet och variansen som parametrar för att bestämma de specifika parametriska värdena för en given modell. Denna uppsättning parametrar kan användas för att förutsäga de data som behövs i en normalfördelning.
vanliga minsta kvadratberäkningar beräknas genom att montera en regressionslinje på givna datapunkter som har minsta summan av de kvadrerade avvikelserna (minsta kvadratfel). Båda används för att uppskatta parametrarna för en linjär regressionsmodell. MLE antar en gemensam sannolikhetsmassfunktion, medan OLS inte kräver några stokastiska antaganden för att minimera avståndet.
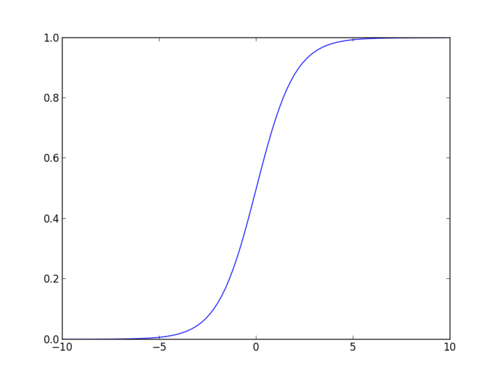
sigmoid-funktion
sigmoid-funktionen, även kallad logistisk funktion, ger en ’S’ – formad kurva som kan ta vilket verkligt värderat tal som helst och kartlägga det till ett värde mellan 0 och 1. Om kurvan går till positiv oändlighet blir y förutspådd 1, och om kurvan går till negativ oändlighet blir y förutspådd 0. Om utsignalen från sigmoidfunktionen är mer än 0,5 kan vi klassificera resultatet som 1 eller ja, och om det är mindre än 0.5, vi kan klassificera det som 0 eller nej. Utgångencannottill exempel: om utgången är 0,75 kan vi säga när det gäller Sannolikhet som: det finns 75 procent chans att patienten kommer att drabbas av cancer.
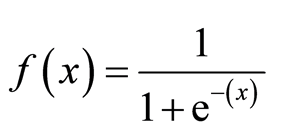
typer av logistisk regression
typer av logistisk regression:
- binär logistisk regression: målvariabeln har bara två möjliga resultat som spam eller inte spam, cancer eller ingen cancer.
- Multinomial logistisk Regression: målvariabeln har tre eller flera nominella kategorier som att förutsäga typen av vin.
- ordinär logistisk Regression: målvariabeln har tre eller flera ordinära kategorier som restaurang eller produktbetyg från 1 till 5.
modellbyggnad i Scikit-lär dig
Låt oss bygga diabetesprognosmodellen.
Här kommer du att förutsäga diabetes med hjälp av logistisk Regressionsklassificerare.
Låt oss först ladda den nödvändiga Pima Indian Diabetes dataset med pandas ’ läs CSV-funktion. Du kan ladda ner data från följande länk: https://www.kaggle.com/uciml/pima-indians-diabetes-database
laddar Data
#import pandasimport pandas as pdcol_names = # load datasetpima = pd.read_csv("pima-indians-diabetes.csv", header=None, names=col_names)pima.head()
välja funktion
här måste du dela upp de givna kolumnerna i två typer av variabler beroende(eller målvariabel) och oberoende variabel(eller funktionsvariabler).
#split dataset in features and target variablefeature_cols = X = pima # Featuresy = pima.label # Target variabledela Data
för att förstå modellprestanda är det en bra strategi att dela datauppsättningen i en träningsuppsättning och en testuppsättning.
Låt oss dela dataset med hjälp av funktionen train_test_split (). Du måste passera 3 parametrar funktioner, mål och test_set storlek. Dessutom kan du använda random_state för att välja poster slumpmässigt.
# split X and y into training and testing setsfrom sklearn.cross_validation import train_test_splitX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=0)/home/admin/.local/lib/python3.5/site-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also, note that the interface of the new CV iterators is different from that of this module. This module will be removed in 0.20. "This module will be removed in 0.20.", DeprecationWarning)Här är datasetet uppdelat i två delar i förhållandet 75:25. Det betyder att 75% data kommer att användas för modellutbildning och 25% för modelltestning.
modellutveckling och förutsägelse
importera först den logistiska Regressionsmodulen och skapa ett logistiskt Regressionsklassificeringsobjekt med LogisticRegression () – funktionen.
montera sedan din modell på tågsatsen med fit () och utför förutsägelse på testuppsättningen med predict ().
# import the classfrom sklearn.linear_model import LogisticRegression# instantiate the model (using the default parameters)logreg = LogisticRegression()# fit the model with datalogreg.fit(X_train,y_train)#y_pred=logreg.predict(X_test)Modellutvärdering med hjälp av Förvirringsmatris
en förvirringsmatris är en tabell som används för att utvärdera prestanda för en klassificeringsmodell. Du kan också visualisera prestanda för en algoritm. Grunden för en förvirringsmatris är antalet korrekta och felaktiga förutsägelser sammanfattas klassvis.
# import the metrics classfrom sklearn import metricscnf_matrix = metrics.confusion_matrix(y_test, y_pred)cnf_matrixarray(, ])Här kan du se förvirringsmatrisen i form av arrayobjektet. Dimensionen av denna matris är 2 * 2 eftersom denna modell är binär klassificering. Du har två klasser 0 och 1. Diagonala värden representerar exakta förutsägelser, medan icke-diagonala element är felaktiga förutsägelser. I utgången är 119 och 36 faktiska förutsägelser, och 26 och 11 är felaktiga förutsägelser.
visualisera Förvirringsmatris med Heatmap
låt oss visualisera resultaten av modellen i form av en förvirringsmatris med matplotlib och seaborn.
Här kommer du att visualisera förvirringsmatrisen med hjälp av Heatmap.
# import required modulesimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlineclass_names= # name of classesfig, ax = plt.subplots()tick_marks = np.arange(len(class_names))plt.xticks(tick_marks, class_names)plt.yticks(tick_marks, class_names)# create heatmapsns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')ax.xaxis.set_label_position("top")plt.tight_layout()plt.title('Confusion matrix', y=1.1)plt.ylabel('Actual label')plt.xlabel('Predicted label')Text(0.5,257.44,'Predicted label')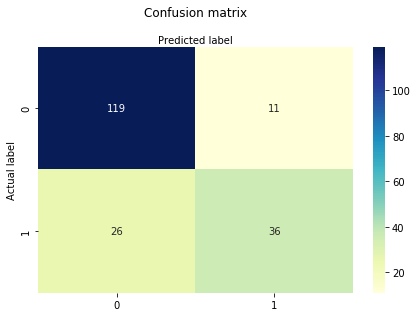
confusion Matrix evaluation metrics
låt oss utvärdera modellen med hjälp av modellutvärderingsmått som noggrannhet, precision och återkallelse.
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))print("Precision:",metrics.precision_score(y_test, y_pred))print("Recall:",metrics.recall_score(y_test, y_pred))Accuracy: 0.8072916666666666Precision: 0.7659574468085106Recall: 0.5806451612903226Tja, du har en klassificeringsgrad på 80%, betraktad som god noggrannhet.
Precision: Precision handlar om att vara exakt, dvs hur exakt din modell är. Med andra ord kan du säga, när en modell gör en förutsägelse, hur ofta det är korrekt. I ditt förutsägelsefall, när din logistiska regressionsmodell förutspådde patienter kommer att drabbas av diabetes, har patienterna 76% av tiden.
minns: om det finns patienter som har diabetes i testuppsättningen och din logistiska regressionsmodell kan identifiera den 58% av tiden.
ROC-kurva
Receiver Operating Characteristic(ROC) kurva är en plot av den sanna positiva hastigheten mot den falska positiva hastigheten. Det visar avvägningen mellan känslighet och specificitet.
y_pred_proba = logreg.predict_proba(X_test)fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)auc = metrics.roc_auc_score(y_test, y_pred_proba)plt.plot(fpr,tpr,label="data 1, auc="+str(auc))plt.legend(loc=4)plt.show()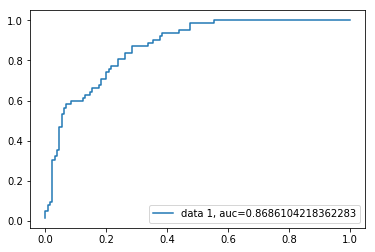
AUC-poäng för fallet är 0,86. AUC-poäng 1 representerar perfekt klassificerare och 0,5 representerar en värdelös klassificerare.
fördelar
På grund av dess effektiva och enkla natur kräver inte hög beräkningskraft, lätt att implementera, lätt tolkbar, används i stor utsträckning av dataanalytiker och forskare. Det kräver inte heller skalning av funktioner. Logistisk regression ger en sannolikhetspoäng för observationer.
nackdelar
logistisk regression kan inte hantera ett stort antal kategoriska funktioner / variabler. Det är sårbart för överfitting. Kan inte heller lösa det icke-linjära problemet med den logistiska regressionen, det är därför det kräver en omvandling av icke-linjära funktioner. Logistisk regression kommer inte att fungera bra med oberoende variabler som inte är korrelerade med målvariabeln och är mycket lika eller korrelerade med varandra.
slutsats
i denna handledning täckte du mycket detaljer om logistisk Regression. Du har lärt dig vad den logistiska regressionen är, hur man bygger respektive modeller, hur man visualiserar resultat och en del av den teoretiska bakgrundsinformationen. Du täckte också några grundläggande begrepp som sigmoid-funktionen, maximal sannolikhet, förvirringsmatris, ROC-kurva.
förhoppningsvis kan du nu använda den logistiska Regressionstekniken för att analysera dina egna dataset. Tack för att du läste denna handledning!
om du vill lära dig mer om logistisk Regression, ta Datacamps Foundations of Predictive Analytics i Python (Del 1) kurs.