
i den här handledningen lär du dig logistisk regression. Här vet du vad exakt är logistisk Regression och du ser också ett exempel med Python. Logistisk Regression är ett viktigt ämne för maskininlärning och jag ska försöka göra det så enkelt som möjligt.
i början av nittonhundratalet, logistisk regression användes främst i biologi efter detta, det användes i vissa Samhällsvetenskapliga tillämpningar. Om du är nyfiken kan du fråga var vi ska använda logistisk regression? Så vi använder logistisk Regression när vår oberoende variabel är kategorisk.
exempel:
- för att förutsäga om en person kommer att köpa en bil (1) eller (0)
- för att veta om tumören är malign (1) eller (0)
låt oss nu överväga ett scenario där du måste klassificera om en person kommer att köpa en bil eller inte. I det här fallet, om vi använder enkel linjär regression, måste vi ange ett tröskelvärde för vilken klassificering som kan göras.
låt säga att den faktiska klassen är att personen kommer att köpa bilen, och förutsagt kontinuerligt värde är 0,45 och tröskeln vi har övervägt är 0.5, då kommer denna datapunkt att betraktas som personen inte kommer att köpa bilen och detta kommer att leda till fel förutsägelse.
så vi drar slutsatsen att vi inte kan använda linjär regression för denna typ av klassificeringsproblem. Som vi vet är linjär regression begränsad, så här kommer logistisk regression där värdet strikt varierar från 0 till 1.
enkel logistisk Regression:
utmatning: 0 eller 1
hypotes: K = W * x + B
h oc/ig(x) = sigmoid(K)
sigmoid funktion:


typer av logistisk Regression:
binär logistisk Regression
endast två möjliga resultat(Kategori).
exempel: personen kommer att köpa en bil eller inte.
Multinomial logistisk Regression
Mer än två kategorier möjliga utan beställning.
Ordningslogistisk Regression
Mer än två kategorier möjliga med beställning.
verkligt exempel med Python:
nu löser vi ett verkligt problem med logistisk Regression. Vi har en datamängd med 5 kolumner nämligen: användar-ID, kön, ålder, EstimatedSalary och köpt. Nu måste vi bygga en modell som kan förutsäga om en person kommer att köpa en bil på den givna parametern eller inte.
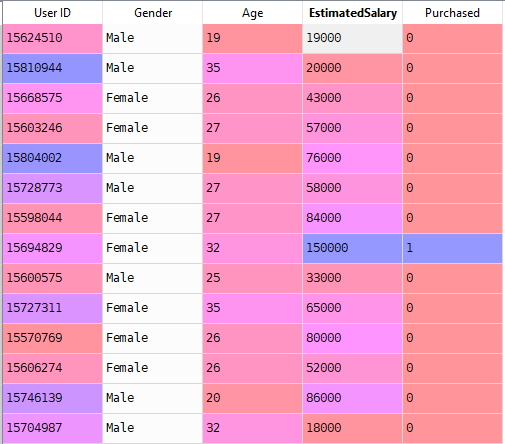
steg för att bygga modellen:
1. Importing the libraries
här importerar vi bibliotek som behövs för att bygga modellen.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
vi importerar vår datamängd i en variabel (dvs dataset) med pandor.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
i vår datamängd kommer vi att överväga ålder och estimatedsalary som oberoende variabel och köpt som beroende variabel.
X = dataset.iloc].valuesy = dataset.iloc.valuesHär är X oberoende variabel och y är beroende variabel.
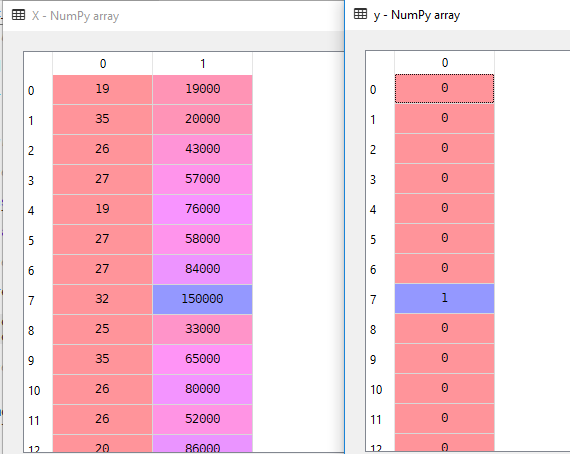
3. Splitting the Data set into the Training Set and Test Set
nu ska vi dela upp vår dataset i träningsdata och testdata. Träningsdata kommer att användas för att träna vår logistiska modell och testdata kommer att användas för att validera vår modell. Vi använder Sklearn för att dela upp våra data. Vi importerar train_test_split från sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
nu ska vi göra funktionsskalning för att skala våra data mellan 0 och 1 för att få bättre noggrannhet.
här skalning är viktigt eftersom det finns en enorm skillnad mellan ålder och EstimatedSalay.
- importera StandardScaler från sklearn.förbehandling
- gör sedan en instans sc_X av objektet StandardScaler
- passa sedan och omvandla X_train och omvandla X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
nu ska vi bygga vår klassificerare (Logistik).
- importera LogisticRegression från sklearn.linear_model
- gör en instans klassificerare av objektet LogisticRegression och ge
random_state = 0 för att få samma resultat varje gång. - använd nu denna klassificerare för att passa X_train och y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)skål!! Efter att ha utfört ovanstående kommando har du en klassificerare som kan förutsäga om en person kommer att köpa en bil eller inte.
använd nu klassificeraren för att göra förutsägelsen för Testdatasatsen och hitta noggrannheten med hjälp av Förvirringsmatris.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)nu får vi y_pred

nu kan vi använda y_test (faktiskt resultat) och y_pred ( förutsagt resultat) för att få noggrannheten i vår modell.
7. Making the Confusion Matrix
med hjälp av Förvirringsmatris kan vi få noggrannhet i vår modell.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)du får en matris cm .

använd cm för att beräkna noggrannhet som visas nedan:
noggrannhet = (cm + cm ) / ( Total testdatapunkter )

Här får vi noggrannhet på 89 % . Skål!! vi får en bra noggrannhet.
slutligen visualiserar vi vårt träningsresultat och testresultat. Vi använder matplotlib för att plotta vår datamängd.
visualisera träningsresultatet
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()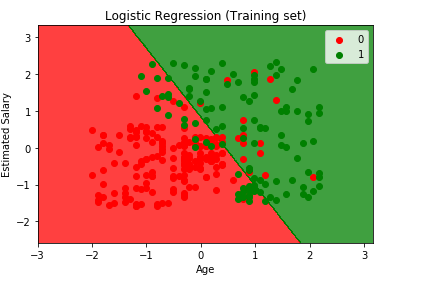
visualisera testresultatet
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Nu kan du bygga din egen klassificerare för logistisk regression.
tack!! Fortsätt Koda !!
Obs: Detta är en gäst post, och yttrande i denna artikel är av gäst författare. Om du har några problem med någon av artiklarna som publiceras på www.marktechpost.com please contact at [email protected]
Advertisement
