ansiktsigenkänning — steg för steg
Låt oss ta itu med detta problem ett steg i taget. För varje steg lär vi oss om en annan maskininlärningsalgoritm. Jag kommer inte att förklara varje enskild algoritm helt för att hålla detta från att bli en bok, men du lär dig de viktigaste ideerna bakom var och en och du lär dig hur du kan bygga ditt eget ansiktsigenkänningssystem i Python med OpenFace och dlib.
Steg 1: Hitta alla ansikten
det första steget i vår pipeline är ansiktsigenkänning. Självklart måste vi hitta ansikten på ett fotografi innan vi kan försöka skilja dem åt!
Om du har använt någon kamera under de senaste 10 åren har du förmodligen sett ansiktsigenkänning i aktion:

ansiktsigenkänning är en utmärkt funktion för kameror. När kameran automatiskt kan plocka ut ansikten kan den se till att alla ansikten är i fokus innan den tar bilden. Men vi kommer att använda det för ett annat syfte-att hitta de områden i bilden vi vill vidarebefordra till nästa steg i vår pipeline.
ansiktsigenkänning gick mainstream i början av 2000-talet när Paul Viola och Michael Jones uppfann ett sätt att upptäcka ansikten som var tillräckligt snabb för att köra på billiga kameror. Men mycket mer tillförlitliga lösningar finns nu. Vi kommer att använda en metod som uppfanns 2005 som kallas Histogram av orienterade gradienter-eller bara HOG för kort.
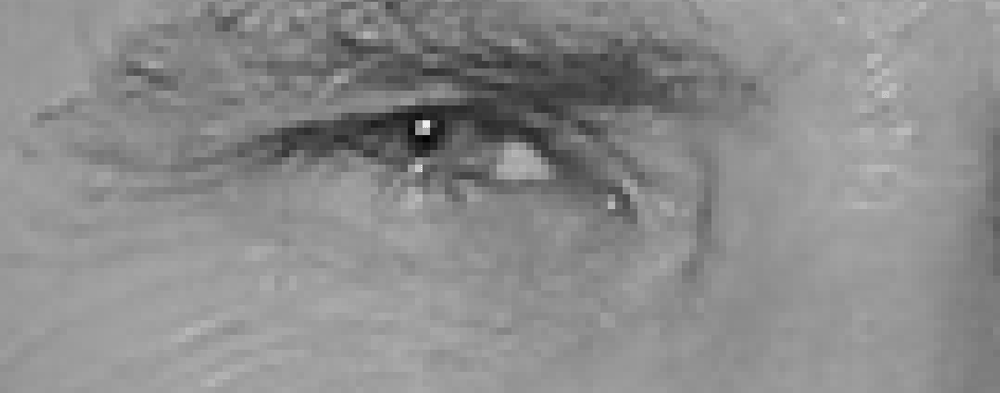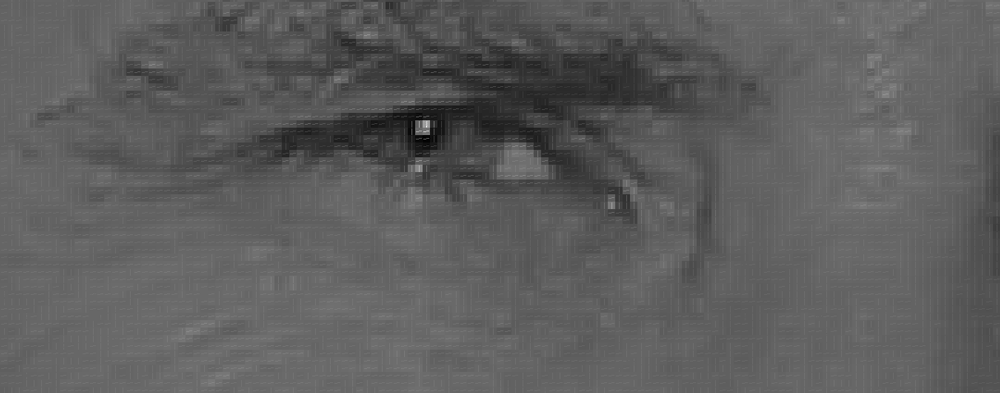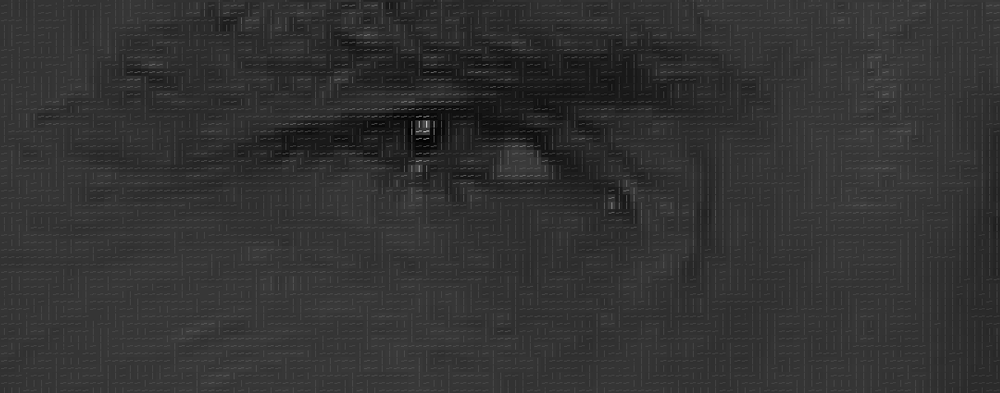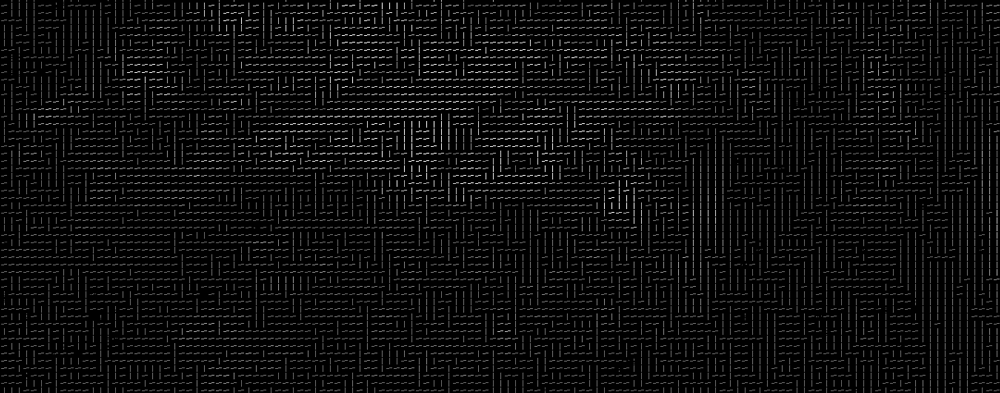
för att hitta ansikten i en bild börjar vi med att göra vår bild svartvitt eftersom vi inte behöver färgdata för att hitta ansikten:

då tittar vi på varje enskild pixel i vår bild en i taget. För varje enskild pixel vill vi titta på pixlarna som direkt omger den:

vårt mål är att ta reda på hur mörk den aktuella pixeln jämförs med pixlarna som omger den direkt. Då vill vi rita en pil som visar i vilken riktning bilden blir mörkare:

blir mörkare uppe till höger.
om du upprepar den processen för varje enskild pixel i bilden, slutar du med att varje pixel ersätts av en pil. Dessa pilar kallas lutningar och de visar flödet från ljus till mörkt över hela bilden:
det här kan verka som en slumpmässig sak att göra, men det finns en riktigt bra anledning att ersätta pixlarna med gradienter. Om vi analyserar pixlar direkt kommer riktigt mörka bilder och riktigt ljusa bilder av samma person att ha helt olika pixelvärden. Men genom att bara överväga riktningen som ljusstyrkan ändras kommer både riktigt mörka bilder och riktigt ljusa bilder att få samma exakta representation. Det gör problemet mycket lättare att lösa!
men att spara lutningen för varje enskild pixel ger oss alldeles för mycket detaljer. Vi saknar skogen för träden. Det skulle vara bättre om vi bara kunde se det grundläggande flödet av ljushet/mörker på en högre nivå så att vi kunde se bildens grundläggande mönster.
för att göra detta bryter vi upp bilden i små rutor på 16×16 pixlar vardera. I varje kvadrat räknar vi upp hur många lutningar som pekar i varje huvudriktning (hur många pekar upp, pekar upp-höger, pekar rätt, etc…). Då ersätter vi den rutan i bilden med pilriktningarna som var starkast.
slutresultatet är att vi förvandlar originalbilden till en mycket enkel representation som fångar grundstrukturen i ett ansikte på ett enkelt sätt:

för att hitta ansikten i denna SVINBILD behöver vi bara hitta den del av vår bild som ser mest ut som ett känt SVINMÖNSTER som extraherades från en massa andra träningsytor:

med denna teknik kan vi nu enkelt hitta ansikten i vilken bild som helst:

om du vill prova detta steg själv med Python och dlib, här är kod som visar hur man genererar och visa HOG representationer av bilder.
steg 2: poserar och projicerar ansikten
Whew, vi isolerade ansikten i vår bild. Men nu måste vi ta itu med det problem som ansikten vände olika riktningar ser helt annorlunda ut än en dator:

människor kan lätt känna igen att båda bilderna är av Will Ferrell, men datorer skulle se dessa bilder som två helt olika människor.
för att ta hänsyn till detta kommer vi att försöka förvränga varje bild så att ögonen och läpparna alltid finns på provplatsen i bilden. Detta kommer att göra det mycket lättare för oss att jämföra ansikten i nästa steg.
för att göra detta kommer vi att använda en algoritm som heter face landmark estimation. Det finns många sätt att göra detta, men vi kommer att använda den metod som uppfanns 2014 av Vahid Kazemi och Josephine Sullivan.
Grundtanken är att vi kommer att komma med 68 specifika punkter (kallade landmärken) som finns på varje ansikte — toppen av hakan, den yttre kanten av varje öga, den inre kanten av varje ögonbryn, etc. Då tränar vi en maskininlärningsalgoritm för att kunna hitta dessa 68 specifika punkter på vilket ansikte som helst:

här är resultatet av att hitta de 68 ansiktsmärken på vår testbild:

Nu när vi vet var ögonen och munnen är, kommer vi helt enkelt att rotera, skala och klippa bilden så att ögonen och munnen är centrerade så bra som möjligt. Vi kommer inte att göra några snygga 3d-varp eftersom det skulle införa snedvridningar i bilden. Vi kommer bara att använda grundläggande bildtransformationer som rotation och skala som bevarar parallella linjer (kallade affine transformationer):

nu oavsett hur ansiktet vänds, kan vi centrera ögonen och munnen är i ungefär samma position i bilden. Detta kommer att göra vårt nästa steg mycket mer exakt.
Om du vill prova detta steg själv med Python och dlib, här är koden för att hitta ansikte landmärken och här är koden för att omvandla bilden med hjälp av dessa landmärken.
steg 3: Kodning ansikten
Nu är vi till köttet av problemet – faktiskt berätta ansikten isär. Det är här Saker blir riktigt intressanta!
den enklaste metoden för ansiktsigenkänning är att direkt jämföra det okända ansiktet vi hittade i steg 2 Med Alla bilder vi har av personer som redan har taggats. När vi hittar ett tidigare taggat ansikte som liknar vårt okända ansikte måste det vara samma person. Verkar som en ganska bra ide, eller hur?
det finns faktiskt ett stort problem med det tillvägagångssättet. En webbplats som Facebook med miljarder användare och en biljon bilder kan omöjligen slinga genom varje tidigare taggade ansikte för att jämföra det med varje nyuppladdad bild. Det skulle ta alldeles för lång tid. De måste kunna känna igen ansikten i millisekunder, inte timmar.
vad vi behöver är ett sätt att extrahera några grundläggande mätningar från varje ansikte. Då kunde vi mäta vårt okända ansikte på samma sätt och hitta det kända ansiktet med närmaste mätningar. Till exempel kan vi mäta storleken på varje öra, avståndet mellan ögonen, längden på näsan etc. Om du någonsin har sett en dålig brottsshow som CSI vet du vad jag pratar om:
det mest pålitliga sättet att mäta ett ansikte
Ok, så vilka mätningar ska vi samla in från varje ansikte för att bygga vår kända ansiktsdatabas? Öronstorlek? Näsa längd? Ögonfärg? Något annat?
det visar sig att de mätningar som verkar uppenbara för oss människor (som ögonfärg) inte riktigt är meningsfulla för en dator som tittar på enskilda pixlar i en bild. Forskare har upptäckt att det mest exakta tillvägagångssättet är att låta datorn räkna ut mätningarna för att samla sig själv. Deep learning gör ett bättre jobb än människor för att ta reda på vilka delar av ett ansikte som är viktiga att mäta.
lösningen är att träna ett djupt Konvolutionellt neuralt nätverk (precis som vi gjorde i del 3). Men istället för att träna nätverket för att känna igen bilder objekt som vi gjorde förra gången, kommer vi att träna det för att generera 128 mätningar för varje ansikte.
träningsprocessen fungerar genom att titta på 3 ansiktsbilder åt gången:
- ladda en träningsbild av en känd person
- ladda en annan bild av samma kända person
- ladda en bild av en helt annan person
sedan tittar algoritmen på de mätningar som den för närvarande genererar för var och en av dessa tre bilder. Det justerar sedan det neurala nätverket något så att det ser till att mätningarna som det genererar för #1 och #2 är något närmare samtidigt som mätningarna för #2 och #3 är något längre ifrån varandra:
efter att ha upprepat detta steg miljoner gånger för miljontals bilder av tusentals olika människor lär det neurala nätverket att på ett tillförlitligt sätt generera 128 mätningar för varje person. Alla tio olika bilder av samma person bör ge ungefär samma mätningar.
Maskininlärningsfolk kallar de 128 mätningarna av varje ansikte en inbäddning. Tanken att minska komplicerade rådata som en bild till en lista över datorgenererade nummer kommer upp mycket i maskininlärning (särskilt i språköversättning). Den exakta metoden för ansikten vi använder uppfanns 2015 av forskare på Google men många liknande metoder finns.
kodning av vår ansiktsbild
denna process för att träna ett konvolutionellt neuralt nätverk för att mata in ansiktsinbäddningar kräver mycket data och datorkraft. Även med ett dyrt NVidia Telsa-grafikkort tar det cirka 24 timmars kontinuerlig träning för att få god noggrannhet.
men när nätverket har tränats kan det generera mätningar för alla ansikten, även de som det aldrig har sett förut! Så detta steg behöver bara göras en gång. Tur för oss, de fina människorna på OpenFace gjorde redan detta och de publicerade flera utbildade nätverk som vi direkt kan använda. Tack Brandon Amos och team!
så allt vi behöver göra själva är att köra våra ansiktsbilder genom deras förutbildade nätverk för att få 128 mätningar för varje ansikte. Här är mätningarna för vår testbild:

Så vilka delar av ansiktet mäter dessa 128 siffror exakt? Det visar sig att vi inte har någon aning. Det spelar ingen roll för oss. Allt vi bryr oss om är att nätverket genererar nästan samma nummer när man tittar på två olika bilder av samma person.
Om du vill prova det här steget själv tillhandahåller OpenFace ett lua-skript som genererar inbäddning av alla bilder i en mapp och skriver dem till en csv-fil. Du kör det så här.
steg 4: Hitta personens namn från kodningen
detta sista steg är faktiskt det enklaste steget i hela processen. Allt vi behöver göra är att hitta personen i vår databas med kända personer som har de närmaste mätningarna till vår testbild.
Du kan göra det genom att använda någon grundläggande maskininlärning klassificeringsalgoritm. Inga snygga djupa inlärningstrick behövs. Vi använder en enkel linjär SVM-klassificerare, men många klassificeringsalgoritmer kan fungera.
allt vi behöver göra är att träna en klassificerare som kan ta in mätningarna från en ny testbild och berätta vilken känd person som är närmast matchningen. Att köra denna klassificerare tar millisekunder. Resultatet av klassificeraren är namnet på personen!
så låt oss prova vårt system. Först tränade jag en klassificerare Med inbäddning av cirka 20 bilder vardera av Will Ferrell, Chad Smith och Jimmy Falon: