alla databasanvändare vet om vanliga aggregerade funktioner som fungerar på en hel tabell och används med en grupp av klausul. Men väldigt få människor använder fönsterfunktioner i SQL. Dessa fungerar på en uppsättning rader och returnerar ett enda aggregerat värde för varje rad.
den största fördelen med att använda fönsterfunktioner över vanliga aggregatfunktioner är: Fönsterfunktioner får inte rader att grupperas i en enda utmatningsrad, raderna behåller sina separata identiteter och ett aggregerat värde läggs till varje rad.
Låt oss ta en titt på hur fönsterfunktioner fungerar och sedan se några exempel på att använda det i praktiken för att vara säker på att saker är tydliga och även hur SQL och output jämför med det för SUM() funktioner.
som alltid vara säker på att du är helt säkerhetskopierad, särskilt om du provar nya saker med din databas.
introduktion till fönsterfunktioner
fönsterfunktioner fungerar på en uppsättning rader och returnerar ett enda aggregerat värde för varje rad. Termfönstret beskriver uppsättningen rader i databasen som funktionen ska fungera på.
Vi definierar fönstret (uppsättning rader på vilka funktioner fungerar) med en över () – sats. Vi kommer att diskutera mer om Over () klausul i artikeln nedan.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. När du kommer att inkludera alla det kommer att räkna alla värden inklusive dubbletter. DISTINCT stöds inte i window functions
expression
målkolumnen eller uttrycket som funktionerna fungerar på. Med andra ord namnet på kolumnen för vilken vi behöver ett aggregerat värde. Till exempel en kolumn som innehåller orderbelopp så att vi kan se totala orderingången.
över
anger fönsterklausulerna för aggregerade funktioner.
PARTITION BY partition_list
definierar fönstret (uppsättning rader som fönsterfunktionen fungerar på) för fönsterfunktioner. Vi måste tillhandahålla ett fält eller en lista med fält för partitionen efter PARTITION BY-klausulen. Flera fält måste separeras med ett komma som vanligt. Om PARTITION BY inte anges kommer gruppering att göras på hela tabellen och värdena kommer att aggregeras i enlighet därmed.
ORDER BY order_list
sorterar raderna inom varje partition. Om ORDER BY inte anges använder ORDER BY hela tabellen.
exempel
Låt oss skapa tabell och infoga dummy-poster för att skriva ytterligare frågor. Kör under kod.
aggregerade fönsterfunktioner
summa ()
vi vet alla summan () aggregerad funktion. Det gör summan av specificerat fält för angiven grupp (som stad, stat, land etc.) eller för hela tabellen om gruppen inte anges. Vi kommer att se vad som kommer att vara resultatet av regular SUM() aggregate funktion och window SUM () aggregate funktion.
Följande är ett exempel på en vanlig summa () aggregatfunktion. Det summerar orderbeloppet för varje stad.
Du kan se från resultatuppsättningen att en vanlig mängdfunktion grupperar flera rader i en enda utmatningsrad, vilket gör att enskilda rader förlorar sin identitet.
|
1
2
3
4
|
Välj stad, summa(order_amount) total_order_amount
från . Grupp efter stad
|

detta händer inte med fönstets sammanlagda funktioner. Rader behåller sin identitet och visar också ett aggregerat värde för varje rad. I exemplet nedan gör frågan samma sak, nämligen den aggregerar data för varje stad och visar summan av det totala orderbeloppet för var och en av dem. Men frågan infogar nu en annan kolumn för det totala orderbeloppet så att varje rad behåller sin identitet. Kolumnen märkt grand_total är den nya kolumnen i exemplet nedan.
AVG()
AVG eller Average fungerar på exakt samma sätt med en fönsterfunktion.
följande fråga ger dig genomsnittligt orderbelopp för varje stad och för varje månad (även om vi för enkelhetens skull bara har använt data på en månad).
vi anger mer än ett genomsnitt genom att ange flera fält i partitionslistan.
det är också värt att notera att du kan använda uttryck i listorna som månad(order_date) som visas i nedanstående fråga. Som någonsin kan du göra dessa uttryck så komplexa som du vill så länge syntaxen är korrekt!
från bilden ovan kan vi tydligt se att vi i genomsnitt har fått order på 12 333 för Arlington city för April 2017.
genomsnittligt orderbelopp = Total orderbelopp / total order
= (20,000 + 15,000 + 2,000) / 3
= 12,333
Du kan också använda kombinationen av SUM ()& COUNT () – funktionen för att beräkna ett genomsnitt.
MIN ()
min() aggregatfunktionen hittar minimivärdet för en viss grupp eller för hela tabellen om grupp inte anges.
till exempel letar vi efter den minsta ordern (Minsta order) för varje stad som vi skulle använda följande fråga.
MAX()
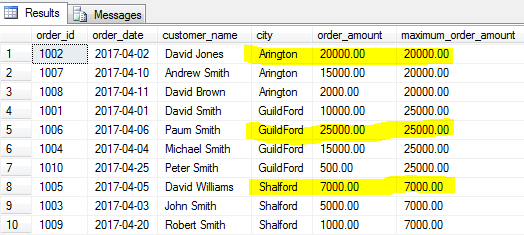
precis som min () – funktionerna ger dig minimivärdet, identifierar MAX () – funktionen det största värdet för ett angivet fält för en viss grupp rader eller för hela tabellen om en grupp inte anges.
låt oss hitta den största ordern (maximal orderbelopp) för varje stad.
räkna()
funktionen räkna() räknar posterna / raderna.
Observera att DISTINCT inte stöds med funktionen window COUNT() medan den stöds för funktionen regular COUNT (). DISTINCT hjälper dig att hitta de olika värdena för ett visst fält.
om vi till exempel vill se hur många kunder som har beställt i April 2017 kan vi inte direkt räkna alla kunder. Det är möjligt att samma kund har lagt flera beställningar under samma månad.
COUNT (customer_name) ger dig ett felaktigt resultat eftersom det kommer att räkna dubbletter. Medan COUNT (distinkt kundnamn) ger dig rätt resultat eftersom det bara räknar varje unik kund en gång.
gäller för regelbunden räkning () funktion:
|
1
2
3
4
5
|
Välj stad,räkna(distinkt kundnamn) number_of_customers
från .
grupp efter stad
|
ogiltig för window COUNT () – funktion:
ovanstående fråga med fönsterfunktion ger dig fel nedan.
låt oss nu hitta den totala order som mottas för varje stad med hjälp av window COUNT () – funktionen.
Rankningsfönsterfunktioner
precis som fönstets sammanlagda funktioner aggregerar värdet för ett angivet fält, rangordnar RANKNINGSFUNKTIONERNA värdena för ett angivet fält och kategoriserar dem efter deras rang.
den vanligaste användningen av RANKNINGSFUNKTIONER är att hitta de översta (N) posterna baserat på ett visst värde. Till exempel, Topp 10 högst betalda anställda, topp 10 rankade studenter, topp 50 största order etc.
följande stöds RANKNINGSFUNKTIONER:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE ()
låt oss diskutera dem en efter en.
RANK ()
funktionen RANK () används för att ge en unik rang till varje post baserat på ett angivet värde, till exempel lön, orderbelopp etc.
om två poster har samma värde kommer funktionen RANK() att tilldela samma rang till båda posterna genom att hoppa över nästa rang. Detta innebär – Om det finns två identiska värden på rang 2, Det kommer att tilldela samma rang 2 till båda posterna och sedan hoppa rank 3 och tilldela rang 4 till nästa post.
låt oss rangordna varje order efter deras orderbelopp.
|
1
2
3
4
5
|
välj order_id,order_date,customer_name,stad,
rang() över(ordning efter order_amount desc)
från .
|
från ovanstående bild kan du se att samma rang (3) tilldelas två identiska poster (var och en har en ordermängd på 15 000) och det hoppar sedan över nästa rang (4) och tilldelar rang 5 till nästa post.
DENSE_RANK ()
funktionen DENSE_RANK() är identisk med funktionen RANK() förutom att den inte hoppar över någon rang. Det betyder att om två identiska poster hittas kommer DENSE_RANK() att tilldela samma rang till båda posterna men inte hoppa över och hoppa över nästa rang.
Låt oss se hur detta fungerar i praktiken.
som du tydligt kan se ovan ges samma rang till två identiska poster (var och en har samma orderbelopp) och sedan ges nästa rangnummer till nästa post utan att hoppa över ett rangvärde.
ROW_NUMBER ()
namnet är självförklarande. Dessa funktioner tilldelar ett unikt radnummer till varje post.
radnumret återställs för varje partition om PARTITION BY anges. Låt oss se hur ROW_NUMBER() fungerar utan PARTITION av och sedan med PARTITION av.
ROW_NUMMER() utan PARTITION av
ROW_NUMBER() med PARTITION av
Observera att vi har gjort partitionen på Stad. Detta innebär att radnumret återställs för varje stad och så startar på 1 igen. Ordningen på raderna bestäms dock av orderbeloppet så att för en viss stad blir det största orderbeloppet den första raden och så tilldelat radnummer 1.
NTILE ()
NTILE () är en mycket användbar fönsterfunktion. Det hjälper dig att identifiera vilken percentil (eller kvartil eller någon annan underavdelning) en given rad faller in i.
det betyder att om du har 100 rader och du vill skapa 4 kvartiler baserat på ett angivet värdefält kan du göra det enkelt och se hur många rader som faller i varje kvartil.
Låt oss se ett exempel. I frågan nedan har vi angett att vi vill skapa fyra kvartiler baserat på orderbelopp. Vi vill sedan se hur många order som faller i varje kvartil.
NTILE skapar plattor baserat på följande formel:
Antal rader i varje kakel = antal rader i resultatuppsättning/antal brickor som anges
Här är vårt exempel, Vi har totalt 10 rader och 4 brickor anges i frågan så antalet rader i varje kakel blir 2,5 (10/4). Eftersom antalet rader ska vara heltal, inte ett decimaltal. SQL engine tilldelar 3 rader för de två första grupperna och 2 rader för återstående två grupper.
value Window Functions
LAG() och LEAD()
LEAD() och LAG() funktioner är mycket kraftfulla men kan vara komplexa att förklara.
eftersom det här är en inledande artikel nedan tittar vi på ett mycket enkelt exempel för att illustrera hur man använder dem.
LAG-funktionen gör det möjligt att komma åt data från föregående rad i samma resultatuppsättning utan att använda några SQL-anslutningar. Du kan se i nedanstående exempel, med hjälp av eftersläpning funktion vi hittade tidigare orderdatum.
Script för att hitta tidigare orderdatum med hjälp av LAG () – funktionen:
LEAD-funktionen gör det möjligt att komma åt data från nästa rad i samma resultatuppsättning utan att använda några SQL-anslutningar. Du kan se i nedanstående exempel, med hjälp av bly funktion vi hittade nästa orderdatum.
skript för att hitta nästa orderdatum med LEAD () – funktion:
FIRST_VALUE() och LAST_VALUE ()
dessa funktioner hjälper dig att identifiera första och sista posten i en partition eller hela tabellen om PARTITION BY inte anges.
Låt oss hitta den första och sista ordningen i varje stad från vår befintliga dataset. Obs ORDER BY klausul är obligatorisk för FIRST_VALUE() och LAST_VALUE () funktioner
från bilden ovan kan vi tydligt se att första order mottagen på 2017-04-02 och sista order mottagen på 2017-04-11 för Arlington city och det fungerar på samma sätt för andra städer.
användbara länkar
- Backup typer& strategier för SQL-databaser
- TechNet artikel om Överklausulen
- MSDN artikel om DENSE_RANK
andra stora artiklar från Ben
hur SQL Server väljer ett dödläge offer
hur SQL Server väljer ett dödläge offer
hur för att använda fönsterfunktioner
- författare
- senaste inlägg
Visa alla inlägg av Ben Richardson
- Power BI: Vattenfallsdiagram och kombinerade bilder – 19 januari 2021
- Power BI: Villkorlig formatering och datafärger i aktion-14 januari 2021
- Power BI: importera data från SQL Server och MySQL-12 januari 2021