BasicsEdit
först, några ordförråd:
| aktivering | = tillstånd värdet av neuronen. För binära neuroner är detta vanligtvis 0 / 1 eller +1 / -1. |
| CAM | = innehåll adresserbart minne. Återkalla ett minne med ett partiellt mönster istället för en minnesadress. |
| konvergens | = stabilisering av ett aktiveringsmönster i ett nätverk. I SL betyder konvergens stabilisering av vikter & fördomar snarare än aktiveringar. |
| diskriminerande | = relaterat till igenkänningsuppgifter. Även kallad analys (i Mönsterteori) eller inferens. |
| energi | = en makroskopisk mängd som beskriver aktiveringsmönstret i ett nätverk. (se nedan) |
| generalisering | = beter sig exakt på tidigare un-stött ingångar |
| generativ | = maskin inbillade och minns uppgift. ibland kallas syntes (i Mönsterteori), mimik eller djupa förfalskningar. |
| slutsats | = ” kör ” – fasen (i motsats till träning). Under inferens utför nätverket den uppgift det är utbildat att göra – antingen känner igen ett mönster (SL) eller skapar ett (UL). Vanligtvis går slutsatsen ned i gradienten för en energifunktion. Till skillnad från SL sker gradient nedstigning under träning, inte inferens. |
| maskinsyn | = maskininlärning på bilder. |
| NLP | = naturlig språkbehandling. Maskininlärning av mänskliga språk. |
| mönster | = nätverksaktiveringar som har en intern ordning i någon mening, eller som kan beskrivas mer kompakt av funktioner i aktiveringarna. Till exempel har pixelmönstret för en noll, oavsett om den ges som data eller föreställs av nätverket, en funktion som kan beskrivas som en enda slinga. Funktionerna är kodade i de dolda neuronerna. |
| utbildning | = inlärningsfasen. Här justerar nätverket sina vikter & förspänningar för att lära av ingångarna. |
uppgifter

UL-metoder förbereder vanligtvis ett nätverk för generativa uppgifter snarare än erkännande, men att gruppera uppgifter som övervakade eller inte kan vara disigt. Till exempel började handskriftsigenkänning på 1980-talet som SL. Sedan 2007 används UL för att prime nätverket för SL efteråt. För närvarande har SL återfått sin position som den bättre metoden.
utbildning
under inlärningsfasen försöker ett oövervakat nätverk att efterlikna de data som det ges och använder felet i sin efterliknade utgång för att korrigera sig själv (t.ex. dess vikter & fördomar). Detta liknar barns mimikbeteende när de lär sig ett språk. Ibland uttrycks felet som en låg sannolikhet för att den felaktiga utgången inträffar, eller det kan uttryckas som ett instabilt högenergitillstånd i nätverket.
energi
en energifunktion är ett makroskopiskt mått på ett nätverks tillstånd. Denna analogi med fysiken är inspirerad av Ludwig Boltzmanns analys av en gas’ makroskopisk energi från de mikroskopiska sannolikheterna för partikelrörelse p sekundärt {\displaystyle \propto }

eE/kT, där k är Boltzmann-konstanten och T är temperaturen. I RBM-nätverket är förhållandet p = e-E / Z, där p & e varierar över alla möjliga aktiveringsmönster och Z = 0 A L L P a t T e R n s {\displaystyle \sum _{AllPatterns}}

E-E(mönster). För att vara mer exakt, p(A) = e-E(a) / Z, där a är ett aktiveringsmönster för alla neuroner (synliga och dolda). Därför bär tidiga neurala nätverk namnet Boltzmann Machine. Paul Smolensky kallar-e harmonin. Ett nätverk söker låg energi vilket är hög harmoni.
nätverk
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
 |
 autoencoder
|
 variational autoencoder
|
Boltzmann och Helmholtz kom före neurala nätverks formuleringar, men dessa nätverk lånade från sina analyser, så dessa nätverk bär sina namn. Hopfield bidrog dock direkt till UL.
IntermediateEdit
Här kommer distributionerna p(x) och q (x) att förkortas som p och q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Det används mest I SL, men förtjänar ett omnämnande här. |
| 1982 | Ising variant Hopfield net beskrivs som Kammar och klassificerare av John Hopfield. |
| 1983 | Ising variant Boltzmann maskin med probabilistiska neuroner som beskrivs av Hinton & Sejnowski efter Sherington & Kirkpatrick ’ s 1975 arbete. |
| 1986 | Paul Smolensky publicerar Harmoniteori, som är en RBM med praktiskt taget samma Boltzmann-energifunktion. Smolensky gav inte ett praktiskt träningssystem. Hinton gjorde i mitten av 2000-talet |
| 1995 | Schmidthuber introducerar LSTM-neuronen för språk. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| Sannolikhet | |
| CDF | = kumulativ fördelningsfunktion. integralen i pdf-filen. Sannolikheten att komma nära 3 är området under kurvan mellan 2,9 och 3,1. |
| kontrastiv divergens | = en inlärningsmetod där man sänker energin på träningsmönster och höjer energin på oönskade mönster utanför träningsuppsättningen. Detta skiljer sig mycket från KL-divergensen, men delar en liknande formulering. |
| förväntat värde | = e(x) = 2 {\displaystyle \sum _{x}}
 x * p(x). Detta är medelvärdet eller medelvärdet. För kontinuerlig ingång x, ersätt summeringen med en integral. |
| latent variabel | = en obemärkt mängd som hjälper till att förklara observerade data. till exempel kan en influensainfektion (obemärkt) förklara varför en person nysar (observerad). I probabilistiska neurala nätverk fungerar dolda neuroner som latenta variabler, även om deras latenta Tolkning inte uttryckligen är känd. |
| = sannolikhetstäthetsfunktion. Sannolikheten att en slumpmässig variabel tar på sig ett visst värde. För kontinuerlig pdf kan p (3) = 1/2 fortfarande betyda att det finns nära noll chans att uppnå detta exakta värde på 3. Vi rationaliserar detta med cdf. | |
| stokastisk | = beter sig enligt en väl beskriven sannolikhetsdensitetsformel. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Det är det maximala reversibla arbetet som kan utföras av ett värmesystem vid konstant temperatur och tryck. fri energi G = värme-temperatur * entropi |
| information | = informationsmängden för ett meddelande x = -log p(x) |
| KLD | = relativ entropi. För probabilistiska nätverk är detta analogen till felet mellan ingången & mimicked output. Kullback-Liebler-divergensen (KLD) mäter entropiavvikelsen för 1 distribution från en annan distribution. KLD( p, q)=X {\displaystyle \sum _{x}}
p * log( p / q). Vanligtvis återspeglar p ingångsdata, q återspeglar nätverkets tolkning av det och KLD återspeglar skillnaden mellan de två. |
jämförelse av nätverk
| Boltzmann | RBM | Helmholtz | autoencoder | vae | användning ¬ables | cam, resande säljare problem | cam. Anslutningsfriheten gör det här nätverket svårt att analysera. | mönsterigenkänning (mnist, taligenkänning) | fantasi, mimik | språk: kreativt skrivande, översättning. Vision: förbättra suddiga bilder | generera realistiska data |
|---|---|---|---|---|---|---|---|---|---|
| neuron | deterministiskt binärt tillstånd. Aktivering = { 0 (eller -1) om x är negativt, 1 annars } | stokastisk binär Hopfield neuron | stokastisk binär. Utökad till realvärderad i mitten av 2000-talet | binär, sigmoid | språk: LSTM. vision: lokala mottagliga fält. vanligtvis verkliga värderas Relu aktivering. | ||||
| anslutningar | 1-lager med symmetriska vikter. Inga självanslutningar. | 2-lager. 1-dold & 1-synlig. symmetriska vikter. | 2-lager. symmetriska vikter. inga sidoanslutningar i ett lager. | 3-lager: asymmetriska vikter. 2 nätverk kombineras till 1. | 3-lager. Ingången betraktas som ett lager även om det inte har några inkommande vikter. återkommande lager för NLP. feedforward omvälvningar för vision. ingång & utgång har samma neuronantal. | 3-lager: ingång, kodare, distribution sampler avkodare. provtagaren anses inte vara ett lager (e) | |||
| inferens& energi | energi ges av Gibbs sannolikhetsmått : E = − 1 2 CCL i , J w I j S i S j + CCL i CCL i S i {\displaystyle E=-{\frac {1}{2}}\sum _{I,j}{w_{ij}{s_{i}}{s_{j}}+\sum _{i} {\theta _{i}} {s_{i}}}
 |
samma | samma | samma | minimera kl divergens | slutledning är endast feed-forward. tidigare UL-nätverk sprang framåt och bakåt | minimera fel = rekonstruktionsfel-KLD | ||
| träning | Aubbiwij = si*sj, för +1/-1 neuron | Aubbiwij = e*(pij – p ’ IJ). Detta härrör från att minimera KLD. e = inlärningsfrekvens, p ’ = förutsagd och p = faktisk fördelning. | kontrastiv divergens w/ Gibbs Sampling | wake-sleep 2 phase training | tillbaka sprida återuppbyggnadsfelet | omparameterisera dold tillstånd för backprop | |||
| styrka | liknar fysiska system så att det ärver deras ekvationer | <— samma. dolda neuroner fungerar som intern representation av den yttre världen | snabbare mer praktiskt träningssystem än Boltzmann-maskiner | mildt anatomiskt. analyserbar w/ informationsteori & statistisk mekanik | |||||
| svaghet | hopfield | svårt att träna på grund av sidoanslutningar | RBM | Helmholtz |
specifika nätverk
här markerar vi några egenskaper hos varje nätverk. Ferromagnetism inspirerade Hopfield-nätverk, Boltzmann-maskiner och RBMs. En neuron motsvarar en järndomän med binära magnetiska moment upp och ner, och neurala anslutningar motsvarar domänens inflytande på varandra. Symmetriska anslutningar möjliggör en global energiformulering. Under inferens uppdaterar nätverket varje tillstånd med hjälp av standardaktiveringsstegsfunktionen. Symmetriska vikter garanterar konvergens till ett stabilt aktiveringsmönster.Hopfield-nätverk används som Kammar och garanteras att lösa sig till ett visst mönster. Utan symmetriska vikter är nätverket mycket svårt att analysera. Med rätt energifunktion kommer ett nätverk att konvergera.
Boltzmann maskiner är stokastiska Hopfield nät. Deras tillståndsvärde samplas från denna pdf enligt följande: Antag att en binär neuron brinner med Bernoulli-sannolikheten p(1) = 1/3 och vilar med p(0) = 2/3. Ett samplar från det genom att ta ett jämnt fördelat slumptal y och ansluta det till den inverterade kumulativa fördelningsfunktionen, som i detta fall är stegfunktionen tröskelvärde vid 2/3. Den inverse funktionen = { 0 if x <= 2/3, 1 if x > 2/3 }
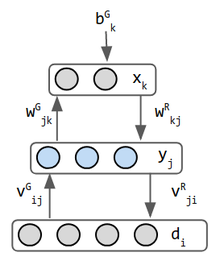
Helmholtz maskiner är tidiga inspirationer för variations Auto kodare. Det är 2 nätverk kombineras till en-framåt vikter Driver erkännande och bakåt vikter genomför fantasi. Det är kanske det första nätverket som gör båda. Helmholtz arbetade inte i maskininlärning men han inspirerade synen på” statistisk inferensmotor vars funktion är att härleda sannolika orsaker till sensorisk inmatning ” (3). den stokastiska binära neuronen matar ut en sannolikhet att dess tillstånd är 0 eller 1. Datainmatningen anses normalt inte vara ett lager, men i Helmholtz-maskingenereringsläget mottar dataskiktet inmatning från mellanskiktet har separata vikter för detta ändamål, så det anses vara ett lager. Därför har detta nätverk 3 lager.Variational Autoencoder (VAE) är inspirerade av Helmholtz-maskiner och kombinerar sannolikhetsnätverk med neurala nätverk. En Autoencoder är ett 3-lagers CAM-nätverk, där Mellanskiktet ska vara en viss intern representation av ingångsmönster. Vikterna heter phi & theta snarare än W och V som i Helmholtz—en kosmetisk skillnad. Kodaren neurala nätverket är en sannolikhetsfördelning Q(Z|x) och avkodaren nätverket är P(X|z). Dessa 2 nätverk här kan vara helt anslutna, eller använd ett annat nn-schema.
Hebbian Learning, ART, SOM
det klassiska exemplet på oövervakat lärande i studien av neurala nätverk är Donald Hebbs princip, det vill säga neuroner som brinner ihop ihop. I Hebbiskt lärande förstärks anslutningen oberoende av ett fel, men är uteslutande en funktion av sammanfallet mellan åtgärdspotentialer mellan de två neuronerna. En liknande version som modifierar synaptiska vikter tar hänsyn till tiden mellan åtgärdspotentialerna (spike-timing-beroende plasticitet eller STDP). Hebbiskt lärande har antagits ligga till grund för en rad kognitiva funktioner, såsom mönsterigenkänning och erfarenhetsinlärning.
bland neurala nätverksmodeller används den självorganiserande kartan (SOM) och adaptiv resonansteori (ART) ofta i oövervakade inlärningsalgoritmer. SOM är en topografisk organisation där närliggande platser på kartan representerar ingångar med liknande egenskaper. ART-modellen gör att antalet kluster kan variera med problemstorlek och låter användaren styra graden av likhet mellan medlemmar i samma kluster med hjälp av en användardefinierad konstant som kallas vaksamhetsparametern. KONSTNÄTVERK används för många mönsterigenkänningsuppgifter, såsom automatisk måligenkänning och seismisk signalbehandling.