
”det finns tre typer av lögner – lögner, jävla lögner och statistik.”- Benjamin Disraeli
statistiska analyser har historiskt varit en stalwart av högteknologiska och avancerade affärsindustrier, och idag är de viktigare än någonsin. Med ökningen av avancerad teknik och globaliserad verksamhet ger statistiska analyser företag en inblick i att lösa marknadens extrema osäkerheter. Studier främjar välgrundat beslutsfattande, Sunda bedömningar och åtgärder som utförs på vikten av bevis, inte antaganden.
eftersom företag ofta tvingas följa en svårtolkad marknadsvägkarta kan statistiska metoder hjälpa till med planeringen som är nödvändig för att navigera i ett landskap fyllt med potholes, fallgropar och fientlig konkurrens. Statistiska studier kan också hjälpa till med marknadsföring av varor eller tjänster och att förstå varje målmarknads unika värdedrivare. I den digitala tidsåldern förbättras och utnyttjas dessa funktioner endast ytterligare genom implementering av avancerad teknik och affärsintelligensprogramvara. Om allt detta är sant, vad är problemet med statistik?
det finns faktiskt inget problem i sig – men det kan vara. Statistik är ökända för sin förmåga och potential att existera som vilseledande och dåliga data.
Vad är en vilseledande statistik?
vilseledande statistik är helt enkelt missbruket – målmedvetet eller inte – av en numerisk data. Resultaten ger en vilseledande information till mottagaren, som sedan tror något fel om han eller hon inte märker felet eller inte har den fullständiga databilden.
med tanke på betydelsen av data i dagens snabbt växande digitala värld är det viktigt att känna till grunderna för vilseledande statistik och övervakning. Som en övning i due diligence kommer vi att granska några av de vanligaste formerna av missbruk av statistik och olika alarmerande (och tyvärr vanliga) vilseledande statistikexempel från det offentliga livet.
är statistiken tillförlitlig?
73,6% av statistiken är falsk. Jaså? Nej, det är naturligtvis ett sminknummer (även om en sådan studie skulle vara intressant att veta – men igen, kan ha alla brister som den försöker samtidigt att påpeka). Statistisk tillförlitlighet är avgörande för att säkerställa analysens precision och giltighet. För att säkerställa att tillförlitligheten är hög finns det olika tekniker att utföra – först av dem är kontrolltesterna, som borde ha liknande resultat när man reproducerar ett experiment under liknande förhållanden. Dessa kontrollåtgärder är väsentliga och bör ingå i alla experiment eller undersökningar – tyvärr är det inte alltid fallet.
medan siffror inte ljuger kan de faktiskt användas för att vilseleda med halvsanningar. Detta kallas ”missbruk av statistik.”Det antas ofta att missbruk av statistik är begränsat till de individer eller företag som försöker få vinst från att förvränga sanningen, vare sig det är ekonomi, utbildning eller massmedia.
men berättandet av halvsanningar genom studier är inte bara begränsat till Matematiska amatörer. En undersökande undersökning från 2009 av Dr. Daniele Fanelli från University of Edinburgh fann att 33.7% av de undersökta forskarna medgav tvivelaktiga forskningsmetoder, inklusive modifiering av resultat för att förbättra resultaten, subjektiv datatolkning, undanhållande av analytiska detaljer och släppa observationer på grund av magkänslor…. Forskare!
medan siffror inte alltid måste tillverkas eller vilseledande, är det uppenbart att även samhällen mest betrodda numeriska gatekeepers inte är immuna mot slarv och bias som kan uppstå med statistiska tolkningsprocesser. Det finns olika sätt hur statistik kan vara vilseledande som vi kommer att beskriva senare. Den vanligaste är naturligtvis korrelation kontra orsakssamband, som alltid lämnar ut en annan (eller två eller tre) faktor som är den faktiska orsaken till problemet. Dricka te ökar diabetes med 50%, och skallighet ökar risken för hjärt-kärlsjukdom upp till 70%! Glömde vi att nämna mängden socker som läggs i teet, eller det faktum att skallighet och ålderdom är relaterade – precis som risker för hjärt-kärlsjukdomar och ålderdom?
så kan statistik manipuleras? De kan säkert. Ljuger siffror? Du kan vara domare.
hur statistik kan vara vilseledande

kom ihåg att missbruk av statistik kan vara oavsiktligt eller ändamålsenligt. Medan en skadlig avsikt att suddiga linjer med vilseledande statistik säkert kommer att förstora bias, är avsikt inte nödvändigt för att skapa missförstånd. Missbruk av statistik är ett mycket bredare problem som nu genomsyrar flera branscher och ämnesområden. Här är några potentiella missöden som ofta leder till missbruk:
- felaktig polling
det sätt på vilket frågor formuleras kan ha en enorm inverkan på hur en publik svarar på dem. Specifika formuleringsmönster har en övertygande effekt och får respondenterna att svara på ett förutsägbart sätt. Till exempel, på en undersökning som söker skatteutlåtanden, låt oss titta på de två potentiella frågorna:
– tror du att du ska beskattas så att andra medborgare inte behöver arbeta?- Tror du att regeringen borde hjälpa de människor som inte kan hitta arbete?
dessa två frågor kommer sannolikt att framkalla mycket olika svar, även om de behandlar samma ämne för statligt stöd. Det här är exempel på ” laddade frågor.”
ett mer exakt sätt att formulera frågan skulle vara, ” stöder du regeringens biståndsprogram för arbetslöshet?”eller, (ännu mer neutralt) ”Vad är din syn på arbetslöshetshjälp?”
de senare två exemplen på de ursprungliga frågorna eliminerar alla slutsatser eller förslag från polleren och är därmed betydligt mer opartiska. En annan orättvis metod för omröstning är att ställa en fråga, men föregå den med ett villkorligt uttalande eller ett faktum. Att stanna med vårt exempel skulle se ut så här: ”med tanke på de stigande kostnaderna för medelklassen, stöder du Statliga biståndsprogram?”
en bra tumregel är att alltid ta polling med ett saltkorn och försöka granska de frågor som faktiskt presenterades. De ger stor insikt, ofta mer än svaren.
- felaktiga korrelationer
problemet med korrelationer är detta: om du mäter tillräckligt med variabler kommer det så småningom att visas att vissa av dem korrelerar. Eftersom en av tjugo oundvikligen kommer att anses vara signifikant utan någon direkt korrelation kan studier manipuleras (med tillräckligt med data) för att bevisa en korrelation som inte existerar eller som inte är tillräckligt stor för att bevisa orsakssamband.
för att illustrera denna punkt ytterligare, låt oss anta att en studie har funnit en korrelation mellan en ökning av bilolyckor i delstaten New York i juni månad (a) och en ökning av björnattacker i delstaten New York i juni månad (B).
det betyder att det sannolikt kommer att finnas sex möjliga förklaringar:
– bilolyckor (a) orsakar björnattacker (B)- Björnattacker (B) orsakar bilolyckor (a)- bilolyckor (A) och björnattacker (B) orsakar delvis varandra – bilolyckor (a) och björnattacker (B) orsakas av en tredje faktor (C)- Björnattacker (B) orsakas av en tredje faktor (C) som korrelerar med bilolyckor (a)- korrelationen är bara chans
varje förnuftig person skulle lätt identifiera det faktum att bilolyckor inte orsakar Björnattacker. Var och en är sannolikt ett resultat av en tredje faktor, det vill säga: en ökad befolkning, på grund av hög turistsäsong i juni månad. Det skulle vara befängt att säga att de orsakar varandra… och det är just därför det är vårt exempel. Det är lätt att se en korrelation.
men vad sägs om orsakssamband? Vad händer om de uppmätta variablerna var olika? Tänk om det var något mer trovärdigt, som Alzheimers och ålderdom? Det finns uppenbarligen en korrelation mellan de två, men finns det orsakssamband? Många skulle felaktigt anta, ja, enbart baserat på korrelationens styrka. Trampa försiktigt, för antingen medvetet eller okunnigt, kommer korrelationsjakt att fortsätta att existera inom statistiska studier.
- datafiske
detta vilseledande dataexempel kallas också” data muddring ” (och relaterat till felaktiga korrelationer). Det är en Data mining teknik där extremt stora datamängder analyseras i syfte att upptäcka relationer mellan datapunkter. Att söka en relation mellan data är inte ett missbruk av data i sig, i alla fall, att göra det utan en hypotes är.
datamuddring är en egennyttig teknik som ofta används för det oetiska syftet att kringgå traditionella data mining tekniker, för att söka ytterligare data slutsatser som inte existerar. Detta är inte att säga att det inte finns någon korrekt användning av data mining, eftersom det faktiskt kan leda till överraskande avvikare och intressanta analyser. Dock, oftare än sällan, datamuddring används för att anta att det finns datarelationer utan ytterligare studier.
ofta resulterar datafiske i studier som är mycket publicerade på grund av deras viktiga eller outlandish fynd. Dessa studier motsägs mycket snart av andra viktiga eller outlandish fynd. Dessa falska korrelationer lämnar ofta allmänheten mycket förvirrad och söker efter svar angående betydelsen av orsakssamband och korrelation.
på samma sätt är en annan vanlig praxis med data utelämnandet, vilket innebär att efter att ha tittat på en stor datamängd svar väljer du bara de som stöder dina åsikter och resultat och lämnar ut de som motsäger det. Som nämnts i början av denna artikel har det visat sig att en tredjedel av forskarna medgav att de hade tvivelaktiga forskningsmetoder, inklusive att hålla tillbaka analytiska detaljer och modifiera resultat…! Men då står vi inför en studie som själv kan falla i dessa 33% av tvivelaktiga metoder, felaktig omröstning, selektiv bias… Det blir svårt att tro på någon analys!
- vilseledande datavisualisering
insiktsfulla grafer och diagram innehåller mycket grundläggande, men väsentliga, gruppering av element. Oavsett vilka typer av datavisualisering du väljer att använda måste den förmedla:
– de använda skalorna – startvärdet (noll eller på annat sätt)- beräkningsmetoden (t.ex. dataset och tidsperiod)
om dessa element saknas bör visuella datarepresentationer ses med ett saltkorn, med hänsyn till de vanliga datavisualiseringsfel man kan göra. Mellanliggande datapunkter bör också identifieras och sammanhang ges om det skulle ge mervärde till den presenterade informationen. Med det ökande beroendet av intelligent lösningsautomatisering för jämförelser av variabla datapunkter bör bästa praxis (dvs. design och skalning) implementeras innan data från olika källor, datamängder, tider och platser jämförs.
- målmedveten och selektiv bias
det sista av våra vanligaste exempel på missbruk av statistik och vilseledande data är kanske det allvarligaste. Målmedveten bias är det avsiktliga försöket att påverka dataresultat utan att ens låtsas professionell ansvarighet. Bias är mest sannolikt att ta form av data utelämnanden eller justeringar.
den selektiva förspänningen är något mer diskret för vem som inte läser de små raderna. Det faller vanligtvis på urvalet av undersökta personer. Till exempel arten av den undersökta gruppen: fråga en klass högskolestudent om den lagliga dricksåldern eller en grupp pensionärer om äldreomsorgen. Du kommer att sluta med ett statistiskt fel som kallas ”selektiv bias”.
- använda procentuell förändring i kombination med en liten provstorlek
ett annat sätt att skapa vilseledande statistik, också kopplad till valet av prov som diskuterats ovan, är storleken på nämnda prov. När ett experiment eller en undersökning leds på en helt inte signifikant provstorlek, kommer resultaten inte bara att vara oanvändbara, men sättet att presentera dem – nämligen som procentsatser – kommer att vara helt vilseledande.
ställa en fråga till en provstorlek på 20 personer, där 19 svarar ”ja” (=95% säger ja) jämfört med att ställa samma fråga till 1000 personer och 950 svarar ”ja” (=95% också): giltigheten av procentsatsen är helt klart inte densamma. Att tillhandahålla enbart procentuell förändring utan det totala antalet eller provstorleken kommer att vara helt vilseledande. xkdc ’s comic illustrerar detta mycket bra för att visa hur det” snabbast växande ” påståendet är ett helt relativt marknadsföringstal:

på samma sätt påverkas den nödvändiga provstorleken av den typ av fråga Du ställer, den statistiska signifikansen du behöver (klinisk studie vs affärsstudie) och den statistiska tekniken. Om du utför en kvantitativ analys är provstorlekar under 200 personer vanligtvis ogiltiga.
vilseledande Statistikexempel i verkligheten
nu när vi har granskat flera av de vanligaste metoderna för missbruk av data, låt oss titta på olika digitala åldersexempel på vilseledande statistik över tre distinkta men relaterade spektrum: media och politik, reklam och vetenskap. Medan vissa ämnen som listas här sannolikt kommer att röra känslor beroende på ens synvinkel, är deras inkludering endast för datademonstrationsändamål.
- exempel på vilseledande statistik i media och politik
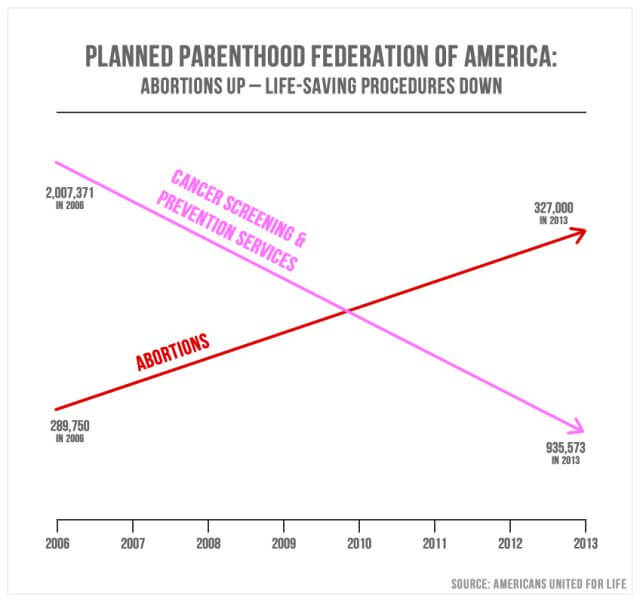
vilseledande statistik i Media är ganska vanligt. På September. 29, 2015, Republikaner från den amerikanska kongressen ifrågasatte Cecile Richards, presidenten för Planned Parenthood, angående missbruk av 500 miljoner dollar i årlig federal finansiering. Ovanstående diagram / diagram presenterades som en betoning.
representant Jason Chaffetz från Utah förklarade: ”i rosa är det minskningen av bröstundersökningarna, och den röda är ökningen av aborterna. Det är vad som händer i din organisation.”
baserat på strukturen i diagrammet verkar det faktiskt visa att antalet aborter sedan 2006 upplevde en betydande tillväxt, medan antalet cancerundersökningar minskade avsevärt. Avsikten är att förmedla ett skifte i fokus från cancerundersökningar till abort. Diagrampunkterna tycks indikera att 327 000 aborter är större i inneboende värde än 935 573 cancerundersökningar. Ändå kommer närmare undersökning att avslöja att diagrammet inte har någon definierad y-axel. Detta innebär att det inte finns någon definierbar motivering för placeringen av de synliga mätlinjerna.
Politifact, en faktakontrollwebbplats, granskade rep.Chaffetzs siffror via en jämförelse med Planned Parenthoods egna årsrapporter. Med hjälp av en tydligt definierad skala ser informationen ut:

och så här med en annan giltig skala:
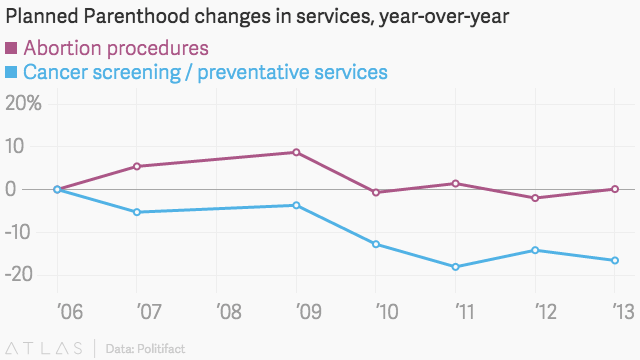
en gång placerad inom en tydligt definierad skala blir det uppenbart att medan antalet cancerundersökningar faktiskt har minskat, överstiger det fortfarande långt antalet abortprocedurer som utförs årligen. Som sådan är detta ett bra vilseledande statistikexempel, och vissa kan argumentera för partiskhet med tanke på att diagrammet inte härstammar från kongressledamoten, utan från amerikaner United for Life, en anti-abortgrupp. Detta är bara ett av många exempel på vilseledande statistik i media och politik.
- vilseledande statistik i reklam

under 2007 beställdes Colgate av Advertising Standards Authority (ASA) i Storbritannien att överge sitt påstående: ”mer än 80% av tandläkare rekommenderar Colgate.”Parollen i fråga placerades på en reklamskylt i Storbritannien och ansågs bryta mot Storbritanniens reklamregler.
påståendet, som baserades på undersökningar av Tandläkare och hygienister utförda av tillverkaren, visade sig vara felaktigt eftersom det gjorde det möjligt för deltagarna att välja ett eller flera tandkrämmärken. ASA uppgav att påståendet ”… skulle förstås av läsarna att betyda att 80 procent av Tandläkarna rekommenderar Colgate utöver andra märken, och de återstående 20 procenten skulle rekommendera olika märken.”
ASA fortsatte, ” eftersom vi förstod att en annan konkurrents varumärke rekommenderades nästan lika mycket som Colgate-varumärket av de undersökta Tandläkarna, drog vi slutsatsen att påståendet vilseledande antydde 80 procent av tandläkare rekommenderar Colgate tandkräm i stället för alla andra märken.”Asa hävdade också att de skript som användes för undersökningen informerade deltagarna om att forskningen utfördes av ett oberoende forskningsföretag, vilket i sig var falskt.
baserat på de missbrukstekniker vi täckte är det säkert att säga att den här tekniken från Colgate är ett tydligt exempel på vilseledande statistik i reklam och skulle falla under felaktig polling och direkt bias.
- vilseledande statistik inom vetenskapen
precis som abort är global uppvärmning ett annat politiskt laddat ämne som sannolikt kommer att väcka känslor. Det råkar också vara ett ämne som kraftfullt stöds av både motståndare och förespråkare via studier. Låt oss ta en titt på några av bevisen för och emot.
det är allmänt överens om att den globala medeltemperaturen 1998 var 58,3 grader Fahrenheit. Detta är enligt NASA: s Goddard Institute for Space Studies. År 2012 mättes den globala medeltemperaturen vid 58,2 grader. Det hävdas därför av motståndare till global uppvärmning att eftersom det var en 0.1-graders minskning av den globala medeltemperaturen under en 14-årsperiod, motbevisas den globala uppvärmningen.
nedanstående graf är den som oftast refereras för att motbevisa den globala uppvärmningen. Det visar förändringen i lufttemperaturen (Celsius) från 1998 till 2012.
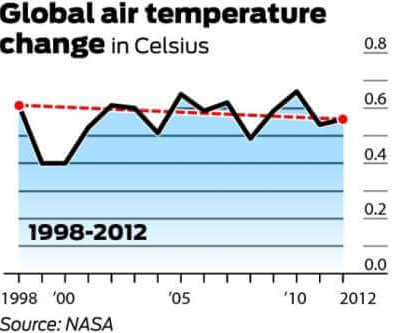
det är värt att nämna att 1998 var ett av de hetaste åren på rekord på grund av en onormalt stark El ni Uruguabovindström. Det är också värt att notera att, eftersom det finns en stor grad av variation inom klimatsystemet, mäts temperaturen vanligtvis med minst en 30-årig cykel. Nedanstående diagram uttrycker den 30-åriga förändringen i globala medeltemperaturer.
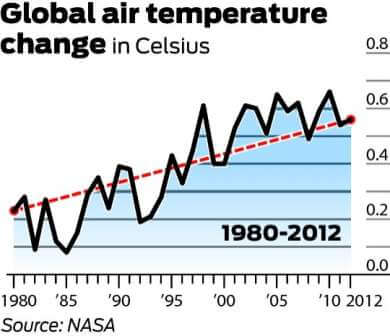
och nu titta på trenden från 1900 till 2012: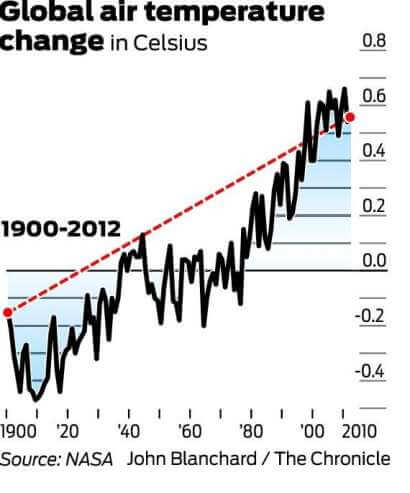
även om de långsiktiga data kan tyckas återspegla en platå, målar det tydligt en bild av gradvis uppvärmning. Att använda den första grafen, och endast den första grafen, för att motbevisa global uppvärmning är därför ett perfekt vilseledande statistikexempel.
hur man läser statistik med avstånd
en första bra sak skulle naturligtvis vara att stå framför en ärlig undersökning/experiment/forskning – välj den du har under dina ögon – som har tillämpat rätt tekniker för insamling och tolkning av data. Men du kan inte veta förrän du ställer dig själv ett par frågor och analyserar resultaten du har mellan dina händer.
som entreprenör och tidigare konsult Mark Suster ger råd i en artikel borde du undra vem som gjorde den primära forskningen av nämnda analys. Oberoende universitet studiegrupp, lab-anslutna forskargrupp, konsultföretag? Därifrån härrör naturligtvis frågan: vem betalade dem? Eftersom ingen arbetar gratis är det alltid intressant att veta vem som sponsrar forskningen. På samma sätt, vilka är motiven bakom forskningen? Vad försökte forskaren eller statistikerna räkna ut? Slutligen, hur stort var provet och vem var en del av det? Hur inkluderande var det?
dessa är viktiga frågor att fundera över och svara på innan de sprids överallt sneda eller förspända resultat – även om det händer hela tiden på grund av förstärkning. Ett typiskt exempel på förstärkning händer ofta med tidningar och journalister, som tar en bit data och behöver göra den till rubriker – alltså ofta ur sitt ursprungliga sammanhang. Ingen köper en tidning där det står att nästa år kommer samma sak att hända på XYZ – marknaden som i år-även om det är sant. Redaktörer, kunder och människor vill ha något nytt, inte något de vet; det är därför vi ofta slutar med ett förstärkningsfenomen som blir echoed och mer än det borde.
missbruk av statistik-En sammanfattning
till frågan ” Kan statistik manipuleras?”, vi kan ta itu med 6 metoder som ofta används-med avsikt eller inte – som snedvrider analysen och resultaten. Här är vanliga typer av missbruk av statistik:
- felaktig polling
- felaktiga korrelationer
- datafiske
- vilseledande datavisualisering
- målmedveten och selektiv bias
- använda procentuell förändring i kombination med en liten provstorlek
nu när du känner till dem blir det lättare att upptäcka dem och ifrågasätta all statistik som ges till dig varje dag. På samma sätt, för att säkerställa att du håller ett visst avstånd till de studier och undersökningar du läser, kom ihåg frågorna att ställa dig själv – vem undersökte och varför, vem betalade för det, vad var provet.
transparens och datadrivna affärslösningar
även om det är helt klart att statistiska data har potential att missbrukas, kan det också etiskt driva marknadsvärdet i den digitala världen. Big data har förmågan att ge digital ålder företag med en färdplan för effektivitet och öppenhet, och så småningom, lönsamhet. Avancerade tekniska lösningar som online rapportering programvara kan förbättra statistiska datamodeller, och ge digital ålder företag med ett steg upp på deras konkurrens.
oavsett om det gäller marknadsinformation, kundupplevelse eller affärsrapportering är framtiden för data nu. Var noga med att tillämpa data ansvarsfullt, etiskt och visuellt och se din transparenta företagsidentitet växa.