
„Es gibt drei Arten von Lügen – Lügen, verdammte Lügen und Statistiken.“ – Benjamin Disraeli
Statistische Analysen waren in der Vergangenheit ein fester Bestandteil der Hightech- und fortschrittlichen Wirtschaftsbranchen und sind heute wichtiger denn je. Mit dem Aufkommen fortschrittlicher Technologien und globalisierter Abläufe gewähren statistische Analysen Unternehmen einen Einblick in die Lösung der extremen Unsicherheiten des Marktes. Studien fördern fundierte Entscheidungen, fundierte Urteile und Handlungen, die auf der Grundlage von Beweisen und nicht von Annahmen durchgeführt werden.
Da Unternehmen oft gezwungen sind, einer schwer zu interpretierenden Markt-Roadmap zu folgen, können statistische Methoden bei der Planung helfen, die notwendig ist, um sich in einer Landschaft voller Schlaglöcher, Fallstricke und feindseliger Konkurrenz zurechtzufinden. Statistische Studien können auch bei der Vermarktung von Waren oder Dienstleistungen und beim Verständnis der einzigartigen Werttreiber der einzelnen Zielmärkte helfen. Im digitalen Zeitalter werden diese Fähigkeiten nur durch die Implementierung fortschrittlicher Technologie und Business Intelligence-Software weiter verbessert und genutzt. Wenn das alles stimmt, was ist das Problem mit Statistiken?
Eigentlich gibt es kein Problem per se – aber es kann sein. Statistiken sind berüchtigt für ihre Fähigkeit und ihr Potenzial, als irreführende und schlechte Daten zu existieren.
Was ist eine irreführende Statistik?
Irreführende Statistiken sind einfach der Missbrauch – absichtlich oder nicht – numerischer Daten. Die Ergebnisse liefern eine irreführende Information für den Empfänger, der dann etwas Falsches glaubt, wenn er oder sie den Fehler nicht bemerkt oder das vollständige Datenbild nicht hat.
Angesichts der Bedeutung von Daten in der sich schnell entwickelnden digitalen Welt von heute ist es wichtig, mit den Grundlagen irreführender Statistiken und Aufsicht vertraut zu sein. Im Rahmen der Sorgfaltspflicht werden wir einige der häufigsten Formen des Missbrauchs von Statistiken sowie verschiedene alarmierende (und leider häufig vorkommende) irreführende Statistikbeispiele aus dem öffentlichen Leben überprüfen.
Sind Statistiken zuverlässig?
73,6% der Statistiken sind falsch. Echt? Nein, natürlich ist es eine erfundene Zahl (obwohl eine solche Studie interessant zu wissen wäre – aber auch hier könnte sie alle Fehler aufweisen, auf die sie gleichzeitig hinzuweisen versucht). Statistische Zuverlässigkeit ist entscheidend, um die Genauigkeit und Validität der Analyse zu gewährleisten. Um sicherzustellen, dass die Zuverlässigkeit hoch ist, müssen verschiedene Techniken durchgeführt werden – zunächst die Kontrolltests, die bei der Reproduktion eines Experiments unter ähnlichen Bedingungen ähnliche Ergebnisse erzielen sollten. Diese Kontrollmaßnahmen sind essentiell und sollten Teil eines jeden Experiments oder einer Umfrage sein – leider ist das nicht immer der Fall.
Während Zahlen nicht lügen, können sie tatsächlich verwendet werden, um mit Halbwahrheiten in die Irre zu führen. Dies wird als „Missbrauch von Statistiken“ bezeichnet.“ Es wird oft angenommen, dass der Missbrauch von Statistiken auf diejenigen Personen oder Unternehmen beschränkt ist, die von der Verzerrung der Wahrheit profitieren wollen, sei es in Wirtschaft, Bildung oder Massenmedien.
Das Erzählen von Halbwahrheiten durch Studium beschränkt sich jedoch nicht nur auf mathematische Amateure. Eine investigative Umfrage von 2009 von Dr. Daniele Fanelli von der University of Edinburgh ergab, dass 33.7% der befragten Wissenschaftler fragwürdige Forschungspraktiken zugaben, einschließlich der Änderung der Ergebnisse zur Verbesserung der Ergebnisse, der subjektiven Dateninterpretation, des Zurückhaltens analytischer Details und des Fallenlassens von Beobachtungen aufgrund von Bauchgefühlen …. Wissenschaftler!
Während Zahlen nicht immer gefälscht oder irreführend sein müssen, ist es klar, dass selbst die vertrauenswürdigsten numerischen Gatekeeper nicht immun gegen die Sorglosigkeit und Voreingenommenheit sind, die bei statistischen Interpretationsprozessen auftreten können. Es gibt verschiedene Möglichkeiten, wie Statistiken irreführend sein können, auf die wir später eingehen werden. Die häufigste ist natürlich Korrelation versus Kausalität, die immer einen anderen (oder zwei oder drei) Faktor auslässt, der die tatsächliche Ursache des Problems ist. Das Trinken von Tee erhöht den Diabetes um 50% und Haarausfall erhöht das Risiko für Herz-Kreislauf-Erkrankungen um bis zu 70%! Haben wir vergessen, die Zuckermenge im Tee zu erwähnen, oder die Tatsache, dass Haarausfall und Alter zusammenhängen – genau wie das Risiko für Herz-Kreislauf-Erkrankungen und das Alter?
Können Statistiken also manipuliert werden? Das können sie sicher. Lügen Zahlen? Du kannst der Richter sein.
Wie Statistiken irreführend sein können

Denken Sie daran, dass der Missbrauch von Statistiken zufällig oder absichtlich sein kann. Während eine böswillige Absicht, Linien mit irreführenden Statistiken zu verwischen, sicherlich Verzerrungen verstärken wird, ist Absicht nicht notwendig, um Missverständnisse zu erzeugen. Der Missbrauch von Statistiken ist ein viel umfassenderes Problem, das mittlerweile mehrere Branchen und Studienbereiche durchdringt. Hier sind einige mögliche Pannen, die häufig zu Missbrauch führen:
- Fehlerhafte Abfrage
Die Art und Weise, wie Fragen formuliert werden, kann einen großen Einfluss darauf haben, wie ein Publikum sie beantwortet. Spezifische Formulierungsmuster haben eine überzeugende Wirkung und veranlassen die Befragten, vorhersehbar zu antworten. Schauen wir uns zum Beispiel bei einer Umfrage, die nach Steuermeinungen sucht, die beiden möglichen Fragen an:
– Glauben Sie, dass Sie besteuert werden sollten, damit andere Bürger nicht arbeiten müssen?- Denken Sie, dass die Regierung den Menschen helfen sollte, die keine Arbeit finden?
Diese beiden Fragen werden wahrscheinlich sehr unterschiedliche Antworten hervorrufen, obwohl sie sich mit demselben Thema der staatlichen Unterstützung befassen. Dies sind Beispiele für „geladene Fragen.“
Eine genauere Formulierung der Frage wäre: „Unterstützen Sie die staatlichen Hilfsprogramme für Arbeitslosigkeit?“ oder (noch neutraler) „Was ist Ihr Standpunkt zur Arbeitslosenhilfe?“
Die beiden letztgenannten Beispiele der ursprünglichen Fragen eliminieren jegliche Rückschlüsse oder Vorschläge des Pollers und sind daher wesentlich unparteiischer. Eine andere unfaire Abfragemethode besteht darin, eine Frage zu stellen, ihr jedoch eine bedingte Aussage oder eine Tatsachenbehauptung vorauszugehen. In unserem Beispiel würde das so aussehen: „Unterstützen Sie angesichts der steigenden Kosten für die Mittelschicht staatliche Hilfsprogramme?“
Eine gute Faustregel ist, Umfragen immer mit einem Körnchen Salz zu betrachten und zu versuchen, die tatsächlich gestellten Fragen zu überprüfen. Sie bieten großartige Einblicke, oft mehr als die Antworten.
- Fehlerhafte Korrelationen
Das Problem mit Korrelationen ist folgendes: Wenn Sie genügend Variablen messen, wird es schließlich scheinen, dass einige von ihnen korrelieren. Da einer von zwanzig unweigerlich ohne direkte Korrelation als signifikant erachtet wird, können Studien manipuliert werden (mit genügend Daten), um eine Korrelation nachzuweisen, die nicht existiert oder die nicht signifikant genug ist, um die Kausalität nachzuweisen.
Um diesen Punkt weiter zu veranschaulichen, nehmen wir an, dass eine Studie eine Korrelation zwischen einer Zunahme von Autounfällen im Bundesstaat New York im Monat Juni (A) und einer Zunahme von Bärenangriffen im Bundesstaat New York im Monat Juni (B) gefunden hat.
Das bedeutet, dass es wahrscheinlich sechs mögliche Erklärungen geben wird:
– Autounfälle (A) verursachen Bärenangriffe (B)- Bärenangriffe (B) verursachen Autounfälle (A)- Autounfälle (A) und Bärenangriffe (B) verursachen sich teilweise gegenseitig- Autounfälle (A) und Bärenangriffe (B) werden durch einen dritten Faktor verursacht (C)- Bärenangriffe (B) werden durch einen dritten Faktor verursacht ein dritter Faktor (C), der mit Autounfällen korreliert (A) – Die Korrelation ist nur Zufall
Jede vernünftige Person würde leicht erkennen, dass Autounfälle keine Bärenangriffe verursachen. Jeder ist wahrscheinlich ein Ergebnis eines dritten Faktors, nämlich: eine erhöhte Bevölkerung, aufgrund der hohen Tourismus-Saison im Monat Juni. Es wäre absurd zu sagen, dass sie sich gegenseitig verursachen… und genau deshalb ist es unser Beispiel. Es ist leicht, eine Korrelation zu erkennen.
Aber was ist mit der Ursache? Was wäre, wenn die Messgrößen unterschiedlich wären? Was wäre, wenn es etwas Glaubwürdigeres wäre, wie Alzheimer und Alter? Klar gibt es eine Korrelation zwischen den beiden, aber gibt es eine Kausalität? Viele würden fälschlicherweise annehmen, ja, allein aufgrund der Stärke der Korrelation. Seien Sie vorsichtig, denn wissentlich oder unwissentlich wird die Korrelationsjagd in statistischen Studien weiterhin bestehen.
- Datenfischen
Dieses irreführende Datenbeispiel wird auch als „Datenbaggern“ bezeichnet (und bezieht sich auf fehlerhafte Korrelationen). Es ist eine Data-Mining-Technik, bei der extrem große Datenmengen analysiert werden, um Beziehungen zwischen Datenpunkten zu entdecken. Die Suche nach einer Beziehung zwischen Daten ist per se kein Datenmissbrauch, dies jedoch ohne Hypothese.
Das Ausbaggern von Daten ist eine eigennützige Technik, die häufig zum unethischen Zweck eingesetzt wird, traditionelle Data-Mining-Techniken zu umgehen, um zusätzliche Datenschlussfolgerungen zu ziehen, die nicht existieren. Dies bedeutet nicht, dass Data Mining nicht ordnungsgemäß eingesetzt wird, da es tatsächlich zu überraschenden Ausreißern und interessanten Analysen führen kann. In den meisten Fällen wird jedoch das Ausbaggern von Daten verwendet, um die Existenz von Datenbeziehungen ohne weitere Untersuchung anzunehmen.
Oft führt Data Fishing zu Studien, die aufgrund ihrer wichtigen oder ausgefallenen Ergebnisse stark publiziert werden. Diese Studien werden sehr bald durch andere wichtige oder ausgefallene Ergebnisse widerlegt. Diese falschen Korrelationen lassen die Öffentlichkeit oft sehr verwirrt zurück und suchen nach Antworten bezüglich der Bedeutung von Kausalität und Korrelation.
Ebenso ist eine andere gängige Praxis mit Daten das Weglassen, was bedeutet, dass Sie nach dem Betrachten eines großen Datensatzes von Antworten nur diejenigen auswählen, die Ihre Ansichten und Ergebnisse unterstützen und diejenigen auslassen, die ihnen widersprechen. Wie zu Beginn dieses Artikels erwähnt, hat sich gezeigt, dass ein Drittel der Wissenschaftler zugegeben hat, fragwürdige Forschungspraktiken zu haben, einschließlich der Zurückhaltung analytischer Details und der Änderung von Ergebnissen…! Andererseits stehen wir vor einer Studie, die selbst in diese 33% fragwürdiger Praktiken, fehlerhafter Umfragen und selektiver Voreingenommenheit fallen könnte… Es wird schwer, jede Analyse zu glauben!
- Irreführende Datenvisualisierung
Aufschlussreiche Grafiken und Diagramme enthalten eine sehr einfache, aber wesentliche Gruppierung von Elementen. Unabhängig von der Art der Datenvisualisierung, die Sie verwenden möchten, muss sie Folgendes vermitteln:
– Die verwendeten Skalen – Der Startwert (Null oder anders)- Die Berechnungsmethode (z. B. Datensatz und Zeitraum)
Ohne diese Elemente sollten visuelle Datendarstellungen mit einem Körnchen Salz betrachtet werden, wobei die üblichen Fehler bei der Datenvisualisierung zu berücksichtigen sind. Zwischendatenpunkte sollten ebenfalls identifiziert und der Kontext angegeben werden, wenn dies den dargestellten Informationen einen Mehrwert verleihen würde. Mit der zunehmenden Abhängigkeit von intelligenter Lösungsautomatisierung für variable Datenpunktvergleiche sollten Best Practices (d. H. Design und Skalierung) implementiert werden, bevor Daten aus verschiedenen Quellen, Datensätzen, Zeiten und Orten verglichen werden.
- Gezielte und selektive Verzerrung
Das letzte unserer häufigsten Beispiele für den Missbrauch von Statistiken und irreführenden Daten ist vielleicht das schwerwiegendste. Zielgerichtete Voreingenommenheit ist der bewusste Versuch, Datenergebnisse zu beeinflussen, ohne auch nur die berufliche Verantwortlichkeit vorzutäuschen. Verzerrungen treten am ehesten in Form von Datenauslassungen oder -anpassungen auf.
Die selektive Verzerrung ist etwas diskreter, für wen die kleinen Zeilen nicht gelesen werden. Es fällt normalerweise auf die Stichprobe der befragten Personen. Zum Beispiel, die Art der Gruppe der befragten Personen: eine Klasse von College-Studenten über das gesetzliche Trinkalter zu fragen, oder eine Gruppe von Rentnern über das Altenpflegesystem. Sie werden mit einem statistischen Fehler namens „Selective Bias“ enden.
- Verwendung der prozentualen Veränderung in Kombination mit einer kleinen Stichprobengröße
Eine andere Möglichkeit, irreführende Statistiken zu erstellen, die auch mit der oben diskutierten Stichprobenauswahl verbunden ist, ist die Größe dieser Stichprobe. Wenn ein Experiment oder eine Umfrage mit einer völlig nicht signifikanten Stichprobengröße durchgeführt wird, sind die Ergebnisse nicht nur unbrauchbar, sondern die Art und Weise, sie darzustellen – nämlich als Prozentsätze – ist völlig irreführend.
Eine Frage an eine Stichprobengröße von 20 Personen stellen, wobei 19 mit „Ja“ antworten (=95% sagen Ja) gegenüber 1.000 Personen und 950 mit „Ja“ antworten (= ebenfalls 95%): Die Gültigkeit des Prozentsatzes ist eindeutig nicht dieselbe. Es ist völlig irreführend, nur den Prozentsatz der Veränderung ohne die Gesamtzahl oder den Stichprobenumfang anzugeben. der Comic von xkdc veranschaulicht dies sehr gut, um zu zeigen, wie der „am schnellsten wachsende“ Anspruch eine völlig relative Marketingrede ist:

Ebenso wird die erforderliche Stichprobengröße von der Art der Frage beeinflusst, die Sie stellen, die statistische Signifikanz, die Sie benötigen (klinische Studie vs. Geschäftsstudie) und die statistische Technik. Wenn Sie eine quantitative Analyse durchführen, sind Stichprobengrößen unter 200 Personen normalerweise ungültig.
Irreführende Statistikbeispiele im wirklichen Leben
Nachdem wir nun einige der häufigsten Methoden des Datenmissbrauchs überprüft haben, schauen wir uns verschiedene Beispiele für irreführende Statistiken im digitalen Zeitalter in drei verschiedenen, aber verwandten Bereichen an: Medien und Politik, Werbung und Wissenschaft. Während bestimmte hier aufgeführte Themen je nach Sichtweise Emotionen auslösen können, dient ihre Einbeziehung nur Datendemonstrationszwecken.
- Beispiele für irreführende Statistiken in den Medien und in der Politik
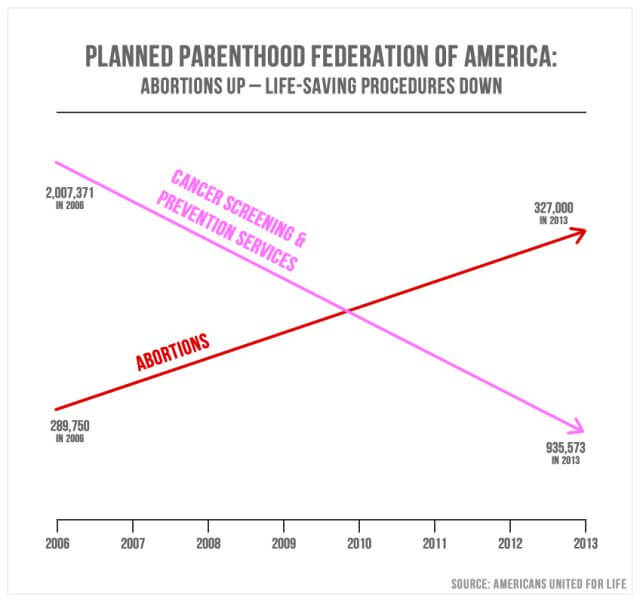
Irreführende Statistiken in den Medien sind weit verbreitet. Am Sept. 29, 2015, Republikaner aus dem US-Kongress befragt Cecile Richards, der Präsident von Planned Parenthood, in Bezug auf die Veruntreuung von $ 500 Millionen in jährlichen Bundesmitteln. Das obige Diagramm / Diagramm wurde als Schwerpunkt dargestellt.
Basierend auf der Struktur des Diagramms scheint es tatsächlich zu zeigen, dass die Zahl der Abtreibungen seit 2006 erheblich zugenommen hat, während die Zahl der Krebsvorsorgeuntersuchungen erheblich zurückgegangen ist. Die Absicht ist es, eine Verschiebung des Fokus von Krebsvorsorgeuntersuchungen auf Abtreibung zu vermitteln. Die Diagrammpunkte scheinen darauf hinzudeuten, dass 327.000 Abtreibungen einen höheren inhärenten Wert haben als 935.573 Krebsvorsorgeuntersuchungen. Bei näherer Betrachtung zeigt sich jedoch, dass das Diagramm keine definierte y-Achse hat. Dies bedeutet, dass es keine definierbare Begründung für die Platzierung der sichtbaren Messlinien gibt.
Politifact, eine Website zur Überprüfung von Fakten, überprüfte die Zahlen von Rep. Chaffetz anhand eines Vergleichs mit den eigenen Jahresberichten von Planned Parenthood. Anhand einer klar definierten Skala sehen die Informationen folgendermaßen aus:

Und so mit einer anderen gültigen Skala:
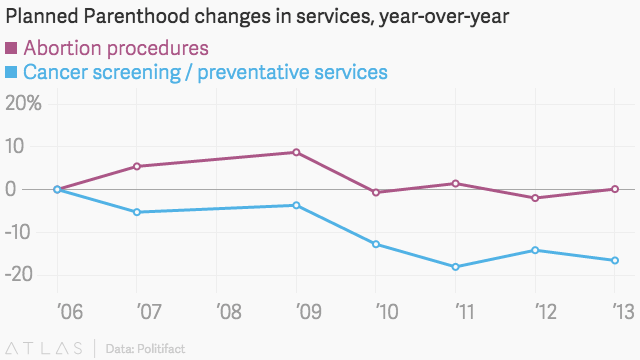
Einmal innerhalb einer klar definierten Skala platziert, wird deutlich, dass die Anzahl der Krebsvorsorgeuntersuchungen zwar zurückgegangen ist, die Anzahl der jährlich durchgeführten Abtreibungsverfahren jedoch bei weitem übertrifft. So wie, Dies ist ein großartiges Beispiel für irreführende Statistiken, und einige könnten Voreingenommenheit argumentieren, wenn man bedenkt, dass das Diagramm nicht vom Kongressabgeordneten stammt, aber von Americans United for Life, eine Anti-Abtreibungsgruppe. Dies ist nur eines von vielen Beispielen für irreführende Statistiken in Medien und Politik.
- Irreführende Statistiken in der Werbung

Im Jahr 2007 wurde Colgate von der Advertising Standards Authority (ASA) der GROßBRITANNIEN, um ihre Behauptung aufzugeben: „Mehr als 80% der Zahnärzte empfehlen Colgate.“ Der fragliche Slogan wurde auf einer Werbetafel in Großbritannien positioniert und als Verstoß gegen die britischen Werberegeln angesehen.
Die Behauptung, die auf Umfragen des Herstellers bei Zahnärzten und Hygienikern beruhte, erwies sich als falsch, da die Teilnehmer eine oder mehrere Zahnpastamarken auswählen konnten. Die ASA erklärte, dass die Behauptung „… von den Lesern so verstanden würde, dass 80 Prozent der Zahnärzte Colgate über andere Marken hinaus empfehlen und die restlichen 20 Prozent verschiedene Marken empfehlen würden.“
Die ASA fuhr fort: „Da wir verstanden haben, dass die Marke eines anderen Wettbewerbers von den befragten Zahnärzten fast genauso empfohlen wurde wie die Marke Colgate, kamen wir zu dem Schluss, dass die Behauptung irreführend implizierte, dass 80 Prozent der Zahnärzte Colgate-Zahnpasta allen anderen Marken vorziehen.“ Die ASA behauptete auch, dass die für die Umfrage verwendeten Skripte die Teilnehmer darüber informierten, dass die Forschung von einem unabhängigen Forschungsunternehmen durchgeführt wurde, was von Natur aus falsch war.
Basierend auf den von uns behandelten Missbrauchstechniken kann man mit Sicherheit sagen, dass diese Taschenspielertrick-Technik von Colgate ein klares Beispiel für irreführende Statistiken in der Werbung ist und unter fehlerhafte Umfragen und völlige Voreingenommenheit fallen würde.
- Irreführende Statistiken in der Wissenschaft
Ähnlich wie Abtreibung ist die globale Erwärmung ein weiteres politisch aufgeladenes Thema, das wahrscheinlich Emotionen weckt. Es ist auch ein Thema, das sowohl von Gegnern als auch von Befürwortern durch Studien energisch unterstützt wird. Schauen wir uns einige der Beweise dafür und dagegen an.
Es ist allgemein vereinbart, dass die globale Durchschnittstemperatur im Jahr 1998 58,3 Grad Fahrenheit betrug. Das berichtet das Goddard Institute for Space Studies der NASA. Im Jahr 2012 wurde die globale Durchschnittstemperatur bei 58,2 Grad gemessen. Es wird daher von Gegnern der globalen Erwärmung argumentiert, dass die globale Erwärmung widerlegt wird, da die globale Durchschnittstemperatur über einen Zeitraum von 14 Jahren um 0,1 Grad gesunken ist.
Die folgende Grafik ist diejenige, auf die am häufigsten verwiesen wird, um die globale Erwärmung zu widerlegen. Es zeigt die Änderung der Lufttemperatur (Celsius) von 1998 bis 2012.
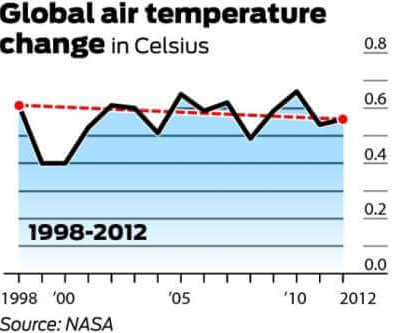
Es ist erwähnenswert, dass 1998 aufgrund einer ungewöhnlich starken El Niño-Windströmung eines der heißesten Jahre seit Beginn der Aufzeichnungen war. Es ist auch erwähnenswert, dass die Temperaturen aufgrund der großen Variabilität innerhalb des Klimasystems typischerweise mit einem Zyklus von mindestens 30 Jahren gemessen werden. Die folgende Grafik zeigt die 30-jährige Veränderung der globalen Durchschnittstemperaturen.
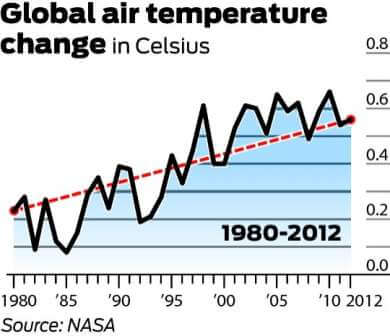
Und jetzt schauen Sie sich den Trend von 1900 bis 2012 an: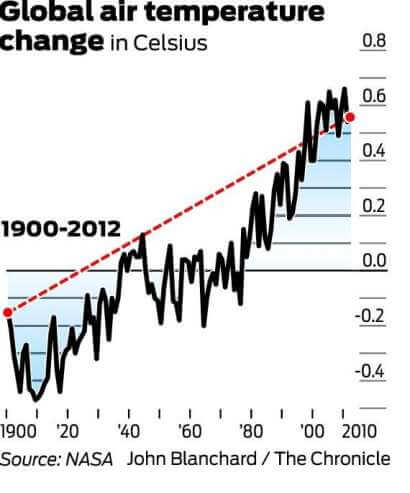
Die Langzeitdaten scheinen zwar ein Plateau widerzuspiegeln, zeichnen jedoch eindeutig ein Bild einer allmählichen Erwärmung. Daher ist die Verwendung des ersten Diagramms und nur des ersten Diagramms zur Widerlegung der globalen Erwärmung ein perfektes Beispiel für irreführende Statistiken.
Wie man Statistiken mit Abstand liest
Eine erste gute Sache wäre natürlich, vor einer ehrlichen Umfrage / Experiment / Forschung zu stehen – wählen Sie die, die Sie unter Ihren Augen haben –, die die richtigen Techniken der Sammlung und Interpretation von Daten angewendet hat. Aber Sie können es erst wissen, wenn Sie sich ein paar Fragen stellen und die Ergebnisse analysieren, die Sie zwischen Ihren Händen haben.
Wie der Unternehmer und ehemalige Berater Mark Suster in einem Artikel rät, sollten Sie sich fragen, wer die Primärforschung dieser Analyse durchgeführt hat. Unabhängige universitäre Studiengruppe, laborangegliedertes Forschungsteam, Beratungsunternehmen? Daraus ergibt sich natürlich die Frage: Wer hat sie bezahlt? Da niemand kostenlos arbeitet, ist es immer interessant zu wissen, wer die Forschung sponsert. Was sind die Motive hinter der Forschung? Was haben die Wissenschaftler oder Statistiker versucht herauszufinden? Schließlich, wie groß war das Sample-Set und wer war Teil davon? Wie inklusiv war es?
Dies sind wichtige Fragen, über die Sie nachdenken und die Sie beantworten müssen, bevor Sie überall verzerrte oder voreingenommene Ergebnisse verbreiten – obwohl dies aufgrund der Verstärkung ständig vorkommt. Ein typisches Beispiel dafür sind Zeitungen und Journalisten, die einzelne Daten in Überschriften umwandeln müssen – also oft aus ihrem ursprünglichen Kontext heraus. Niemand kauft eine Zeitschrift, in der es heißt, dass nächstes Jahr dasselbe auf dem Markt passieren wird wie in diesem Jahr – obwohl es wahr ist. Redakteure, Kunden und Leute wollen etwas Neues, nicht etwas, das sie wissen; Deshalb haben wir oft ein Verstärkungsphänomen, das wiederholt wird und mehr als es sollte.
Missbrauch von Statistiken – Eine Zusammenfassung
Zur Frage „Können Statistiken manipuliert werden?“, wir können adressieren 6 Methoden oft verwendet – absichtlich oder nicht – das verzerrt die Analyse und die Ergebnisse. Hier sind häufige Arten des Missbrauchs von Statistiken:
- Fehlerhafte Abfrage
- Fehlerhafte Korrelationen
- Datenangeln
- Irreführende Datenvisualisierung
- Gezielte und selektive Verzerrung
- Verwendung der prozentualen Änderung in Kombination mit einer kleinen Stichprobengröße
Jetzt, da Sie sie kennen, wird es einfacher sein, sie zu erkennen und alle Statistiken in Frage zu stellen, die Ihnen jeden Tag gegeben werden. Um sicherzustellen, dass Sie einen gewissen Abstand zu den von Ihnen gelesenen Studien und Umfragen einhalten, sollten Sie sich auch die Fragen merken, die Sie sich stellen sollten – wer hat recherchiert und warum, wer hat dafür bezahlt, was war die Stichprobe.
Transparenz und datengetriebene Geschäftslösungen
Es ist zwar klar, dass statistische Daten missbraucht werden können, aber sie können auch den Marktwert in der digitalen Welt ethisch steigern. Big Data hat die Fähigkeit, Unternehmen im digitalen Zeitalter einen Fahrplan für Effizienz und Transparenz und schließlich für Rentabilität zu bieten. Fortschrittliche Technologielösungen wie Online-Berichtssoftware können statistische Datenmodelle verbessern und Unternehmen im digitalen Zeitalter einen Wettbewerbsvorteil verschaffen.
Ob für Marktinformationen, Kundenerfahrung oder Geschäftsberichte, die Zukunft der Daten ist jetzt. Achten Sie darauf, Daten verantwortungsvoll, ethisch und visuell anzuwenden und beobachten Sie, wie Ihre transparente Corporate Identity wächst.