
In diesem Tutorial lernen Sie die logistische Regression. Hier wissen Sie, was genau logistische Regression ist, und Sie sehen auch ein Beispiel mit Python. Logistische Regression ist ein wichtiges Thema des maschinellen Lernens und ich werde versuchen, es so einfach wie möglich zu machen.
Im frühen zwanzigsten Jahrhundert wurde die logistische Regression hauptsächlich in der Biologie verwendet, danach wurde sie in einigen sozialwissenschaftlichen Anwendungen verwendet. Wenn Sie neugierig sind, fragen Sie sich vielleicht, wo wir die logistische Regression einsetzen sollen? Wir verwenden also die logistische Regression, wenn unsere unabhängige Variable kategorisch ist.
Beispiele:
- Um vorherzusagen, ob eine Person ein Auto kaufen wird (1) oder (0)
- Um zu wissen, ob der Tumor bösartig ist (1) oder (0)
Betrachten wir nun ein Szenario, in dem Sie klassifizieren müssen, ob eine Person ein Auto kaufen wird oder nicht. Wenn wir in diesem Fall eine einfache lineare Regression verwenden, müssen wir einen Schwellenwert angeben, an dem die Klassifizierung vorgenommen werden kann.Nehmen wir an, die tatsächliche Klasse ist die Person, die das Auto kaufen wird, und der vorhergesagte kontinuierliche Wert ist 0,45 und die Schwelle, die wir in Betracht gezogen haben, ist 0.5, dann wird dieser Datenpunkt berücksichtigt, da die Person das Auto nicht kauft und dies zu einer falschen Vorhersage führt.
Wir kommen also zu dem Schluss, dass wir für diese Art von Klassifizierungsproblem keine lineare Regression verwenden können. Wie wir wissen, ist die lineare Regression begrenzt, Also kommt hier die logistische Regression, bei der der Wert streng von 0 bis 1 reicht.
Einfache logistische Regression:
Ausgabe: 0 oder 1
Hypothese: K = W * X + B
hΘ(x) = Sigmoid(K)
Sigmoidfunktion:


Arten der logistischen Regression:
Binäre Logistische Regression
Nur zwei mögliche Ergebnisse(Kategorie).
Beispiel: Die Person wird ein Auto kaufen oder nicht.
Multinomiale logistische Regression
Mehr als zwei Kategorien ohne Bestellung möglich.
Ordinale logistische Regression
Mehr als zwei Kategorien bei Bestellung möglich.
Reales Beispiel mit Python:
Jetzt lösen wir ein reales Problem mit Logistischer Regression. Wir haben einen Datensatz mit 5 Spalten, nämlich: Benutzer-ID, Geschlecht, Alter, geschätzter Gehalt und Gekauft. Jetzt müssen wir ein Modell bauen, das vorhersagen kann, ob auf dem gegebenen Parameter eine Person ein Auto kaufen wird oder nicht.
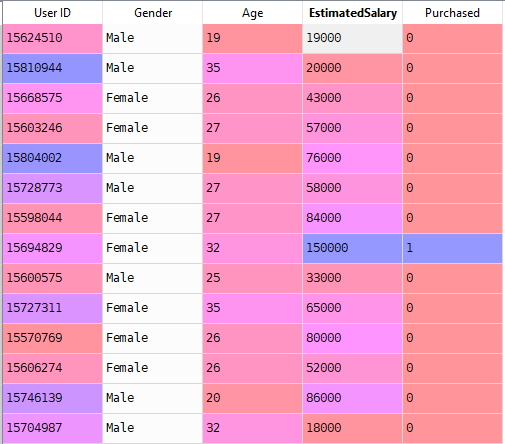
Schritte zum Erstellen des Modells:
1. Importing the libraries
Hier importieren wir Bibliotheken, die zum Erstellen des Modells benötigt werden.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
Wir importieren unseren Datensatz in eine Variable (dh Datensatz) mit Pandas.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
In unserem Datensatz betrachten wir Alter und geschätztes Gehalt als unabhängige Variable und gekauft als abhängige Variable.
X = dataset.iloc].valuesy = dataset.iloc.valuesHier ist X eine unabhängige Variable und y eine abhängige Variable.
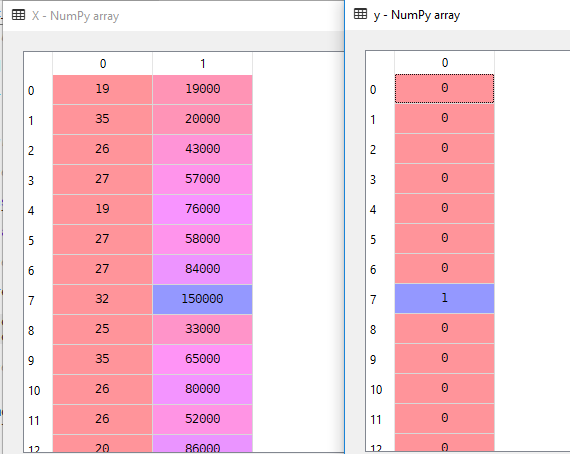
3. Splitting the Data set into the Training Set and Test Set
Jetzt teilen wir unseren Datensatz in Trainingsdaten und Testdaten auf. Trainingsdaten werden verwendet, um unser
Logistikmodell zu trainieren, und Testdaten werden verwendet, um unser Modell zu validieren. Wir verwenden Sklearn, um unsere Daten aufzuteilen. Wir importieren train_test_split von sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
Jetzt machen wir Feature skalierung, um unsere Daten zwischen 0 und 1 zu skalieren, um eine bessere Genauigkeit zu erzielen.
Hier Skalierung ist wichtig, weil es einen großen Unterschied zwischen Alter und EstimatedSalay.
- StandardScaler aus sklearn importieren.vorverarbeitung
- Dann machen Sie eine Instanz sc_X des Objekts StandardScaler
- Dann passen und transformieren Sie X_train und transformieren Sie X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Jetzt bauen wir unseren Klassifikator (Logistisch).
- Importieren Sie LogisticRegression aus sklearn.linear_model
- Erstellen Sie einen Instanzklassifikator des Objekts LogisticRegression und geben Sie
random_state = 0 , um jedes Mal das gleiche Ergebnis zu erhalten. - Verwenden Sie nun diesen Klassifikator, um X_train und y_train anzupassen
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Prost!! Nachdem Sie den obigen Befehl ausgeführt haben, haben Sie einen Klassifikator, der vorhersagen kann, ob eine Person ein Auto kaufen wird oder nicht.
Verwenden Sie nun den Klassifikator, um die Vorhersage für den Testdatensatz zu treffen und die Genauigkeit mithilfe der Verwirrungsmatrix zu ermitteln.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)Jetzt bekommen wir y_pred

Jetzt können wir y_test (Tatsächliches Ergebnis) und y_pred (Vorhergesagtes Ergebnis) verwenden, um die Genauigkeit unseres Modells zu erhalten.
7. Making the Confusion Matrix
Mithilfe der Verwirrungsmatrix können wir die Genauigkeit unseres Modells ermitteln.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)Sie erhalten eine Matrix cm .

Verwenden Sie cm, um die Genauigkeit wie unten gezeigt zu berechnen:
Genauigkeit = ( cm + cm ) / (Gesamttestdatenpunkte)

Hier erhalten wir eine Genauigkeit von 89 % . Prost!! wir bekommen eine gute Genauigkeit.
Schließlich visualisieren wir unser Trainingsset-Ergebnis und das Testset-Ergebnis. Wir verwenden matplotlib, um unseren Datensatz zu zeichnen.
Visualisierung des Ergebnisses des Trainingssatzes
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()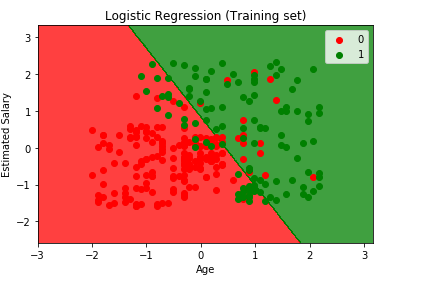
Visualisierung des Ergebnisses des Testsatzes
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Jetzt können Sie Ihren eigenen Klassifikator für die logistische Regression erstellen.
Vielen Dank!! Codieren Sie weiter!!
Hinweis: Dies ist ein Gastbeitrag, und die Meinung in diesem Artikel ist vom Gastautor. Wenn Sie Probleme mit einem der unter www veröffentlichten Artikel haben.in: marktechpost.com please contact at [email protected]
Advertisement
