Gesichtserkennung — Schritt für Schritt
Lassen Sie uns dieses Problem Schritt für Schritt angehen. Für jeden Schritt lernen wir einen anderen Algorithmus für maschinelles Lernen kennen. Ich werde nicht jeden einzelnen Algorithmus vollständig erklären, um zu verhindern, dass daraus ein Buch wird, aber Sie werden die Hauptideen hinter jedem einzelnen lernen und lernen, wie Sie Ihr eigenes Gesichtserkennungssystem in Python mit OpenFace und dlib erstellen können.
Schritt 1: Alle Gesichter finden
Der erste Schritt in unserer Pipeline ist die Gesichtserkennung. Natürlich müssen wir die Gesichter auf einem Foto lokalisieren, bevor wir versuchen können, sie auseinander zu halten!
Wenn Sie in den letzten 10 Jahren eine Kamera verwendet haben, haben Sie wahrscheinlich die Gesichtserkennung in Aktion gesehen:

Die Gesichtserkennung ist eine großartige Funktion für Kameras. Wenn die Kamera automatisch Gesichter auswählen kann, kann sie sicherstellen, dass alle Gesichter fokussiert sind, bevor sie das Bild aufnimmt. Aber wir werden es für einen anderen Zweck verwenden – die Bereiche des Bildes zu finden, die wir an den nächsten Schritt in unserer Pipeline weitergeben möchten.Die Gesichtserkennung wurde in den frühen 2000er Jahren zum Mainstream, als Paul Viola und Michael Jones eine Methode zur Erkennung von Gesichtern erfanden, die schnell genug war, um mit billigen Kameras ausgeführt zu werden. Es gibt jedoch jetzt viel zuverlässigere Lösungen. Wir werden eine 2005 erfundene Methode namens Histogramm orientierter Gradienten — oder kurz HOG – verwenden.
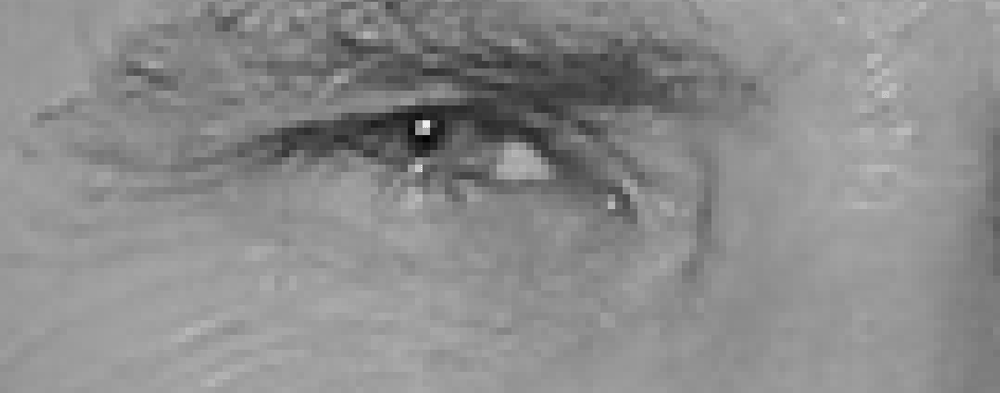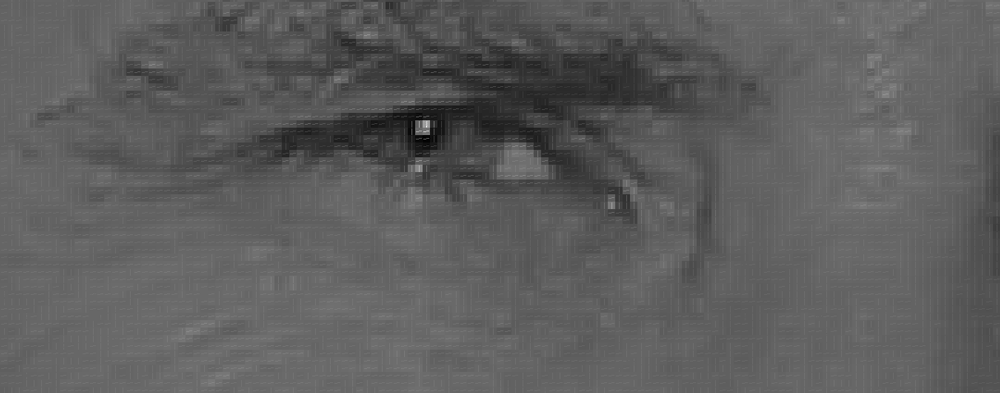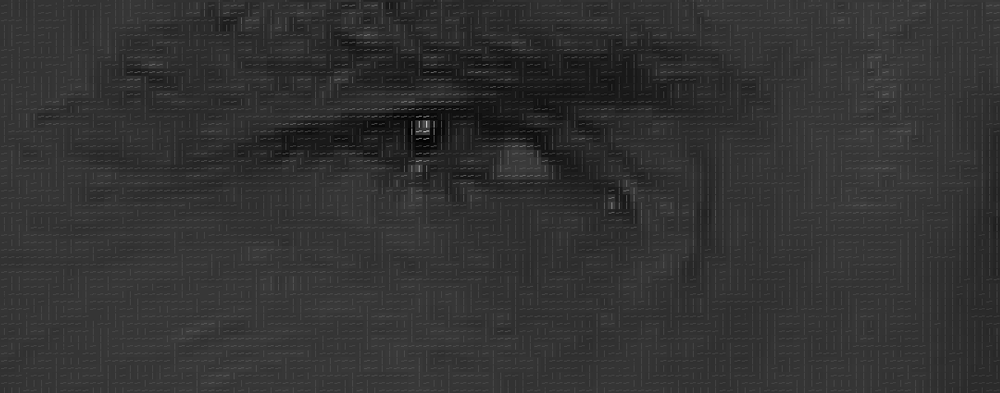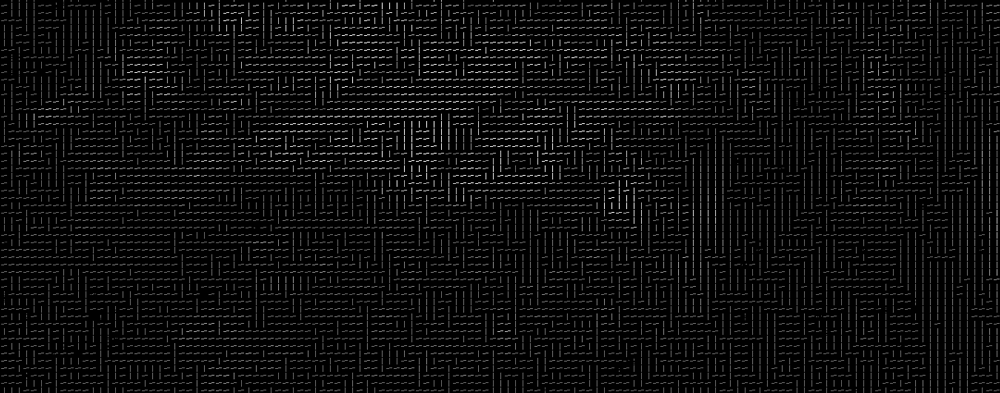
Um Gesichter in einem Bild zu finden, machen wir zunächst unser Bild schwarzweiß, da wir keine Farbdaten benötigen, um Gesichter zu finden:

Dann betrachten wir jedes einzelne Pixel in unserem Bild einzeln. Für jedes einzelne Pixel möchten wir die Pixel betrachten, die es direkt umgeben:

Unser Ziel finde heraus, wie dunkel das aktuelle Pixel im Vergleich zu den Pixeln ist, die es direkt umgeben. Dann möchten wir einen Pfeil zeichnen, der zeigt, in welche Richtung das Bild dunkler wird:

Wenn Sie diesen Vorgang für jedes einzelne Pixel im Bild wiederholen, wird jedes Pixel durch einen Pfeil ersetzt. Diese Pfeile werden als Farbverläufe bezeichnet und zeigen den Fluss von hell nach dunkel über das gesamte Bild:
wie eine zufällige Sache, aber es gibt einen wirklich guten Grund, die Pixel durch Farbverläufe zu ersetzen. Wenn wir Pixel direkt analysieren, haben wirklich dunkle Bilder und wirklich helle Bilder derselben Person völlig unterschiedliche Pixelwerte. Wenn Sie jedoch nur die Richtung berücksichtigen, in die sich die Helligkeit ändert, erhalten sowohl wirklich dunkle als auch wirklich helle Bilder dieselbe exakte Darstellung. Das macht das Problem viel einfacher zu lösen!
Aber das Speichern des Verlaufs für jedes einzelne Pixel gibt uns viel zu viele Details. Am Ende fehlt uns der Wald für die Bäume. Es wäre besser, wenn wir nur den grundlegenden Fluss von Helligkeit / Dunkelheit auf einer höheren Ebene sehen könnten, damit wir das Grundmuster des Bildes sehen könnten.
Dazu teilen wir das Bild in kleine Quadrate von jeweils 16×16 Pixel auf. In jedem Quadrat zählen wir auf, wie viele Gradienten in jede Hauptrichtung zeigen (wie viele Punkte nach oben, nach rechts, nach rechts usw.). Dann ersetzen wir das Quadrat im Bild durch die Pfeilrichtungen, die am stärksten waren.
Das Endergebnis ist, dass wir das Originalbild in eine sehr einfache Darstellung verwandeln, die die Grundstruktur eines Gesichts auf einfache Weise erfasst:

Um Gesichter in diesem Schweinebild zu finden, müssen wir nur den Teil unseres Bildes finden, der einem bekannten Schweinemuster am ähnlichsten ist, das aus einer Reihe anderer Trainingsgesichter extrahiert wurde:

Mit dieser Technik können wir jetzt leicht Gesichter in jedem Bild finden:

Wenn sie um diesen Schritt selbst mit Python und dlib auszuprobieren, finden Sie hier Code, der zeigt, wie Sie Schweinedarstellungen von Bildern generieren und anzeigen.
Schritt 2: Posieren und Projizieren von Gesichtern
Puh, wir haben die Gesichter in unserem Bild isoliert. Aber jetzt müssen wir uns mit dem Problem befassen, dass Gesichter in verschiedene Richtungen völlig anders aussehen als bei einem Computer:

Um dies zu berücksichtigen, werden wir versuchen, jedes Bild so zu verzerren, dass sich Augen und Lippen immer an derselben Stelle im Bild befinden. Dies wird es uns in den nächsten Schritten viel einfacher machen, Gesichter zu vergleichen.
Dazu verwenden wir einen Algorithmus namens Face Landmark Estimation. Es gibt viele Möglichkeiten, dies zu tun, aber wir werden den Ansatz verwenden, der 2014 von Vahid Kazemi und Josephine Sullivan erfunden wurde.
Die Grundidee ist, dass wir 68 spezifische Punkte (sogenannte Landmarken) auf jedem Gesicht finden — die Oberseite des Kinns, die Außenkante jedes Auges, die Innenkante jeder Augenbraue usw. Dann werden wir einen maschinellen Lernalgorithmus trainieren, um diese 68 spezifischen Punkte auf jedem Gesicht finden zu können:

Hier ist das Ergebnis der Lokalisierung der 68 Gesicht Orientierungspunkte auf unserem Testbild:

Nachdem wir nun wissen, wo Augen und Mund sind, drehen, skalieren und scheren wir das Bild einfach so, dass Augen und Mund so gut wie möglich zentriert sind. Wir werden keine ausgefallenen 3D-Verzerrungen vornehmen, da dies zu Verzerrungen im Bild führen würde. Wir werden nur grundlegende Bildtransformationen wie Rotation und Skalierung verwenden, die parallele Linien beibehalten (affine Transformationen genannt):

wie das Gesicht gedreht wird, sind wir in der Lage, die Augen und Mund sind in etwa die gleiche Position im Bild zu zentrieren. Dies wird unseren nächsten Schritt viel genauer machen.
Wenn Sie diesen Schritt selbst mit Python und dlib ausprobieren möchten, finden Sie hier den Code zum Suchen von Gesichts-Landmarken und hier den Code zum Transformieren des Bildes mithilfe dieser Landmarken.
Schritt 3: Gesichter kodieren
Jetzt sind wir beim Fleisch des Problems — Gesichter tatsächlich auseinander zu halten. Hier wird es wirklich interessant!Der einfachste Ansatz zur Gesichtserkennung besteht darin, das unbekannte Gesicht, das wir in Schritt 2 gefunden haben, direkt mit allen Bildern von Personen zu vergleichen, die bereits markiert wurden. Wenn wir ein zuvor markiertes Gesicht finden, das unserem unbekannten Gesicht sehr ähnlich sieht, muss es dieselbe Person sein. Scheint eine ziemlich gute Idee zu sein, oder?
Es gibt tatsächlich ein großes Problem mit diesem Ansatz. Eine Website wie Facebook mit Milliarden von Nutzern und einer Billion Fotos kann unmöglich jedes zuvor markierte Gesicht durchlaufen, um es mit jedem neu hochgeladenen Bild zu vergleichen. Das würde viel zu lange dauern. Sie müssen in der Lage sein, Gesichter in Millisekunden zu erkennen, nicht in Stunden.
Was wir brauchen, ist eine Möglichkeit, ein paar grundlegende Messungen von jedem Gesicht zu extrahieren. Dann könnten wir unser unbekanntes Gesicht auf die gleiche Weise messen und das bekannte Gesicht mit den nächsten Messungen finden. Zum Beispiel können wir die Größe jedes Ohrs, den Abstand zwischen den Augen, die Länge der Nase usw. messen. Wenn Sie jemals eine schlechte Krimishow wie CSI gesehen haben, wissen Sie, wovon ich spreche:
Der zuverlässigste Weg, ein Gesicht zu messen
Ok, welche Messungen sollten wir von jedem Gesicht sammeln, um unsere bekannte Gesichtsdatenbank zu erstellen? Ohr größe? Nasenlänge? Augenfarbe? Etwas anderes?Es stellt sich heraus, dass die Messungen, die uns Menschen offensichtlich erscheinen (wie die Augenfarbe), für einen Computer, der einzelne Pixel in einem Bild betrachtet, nicht wirklich Sinn machen. Forscher haben herausgefunden, dass der genaueste Ansatz darin besteht, den Computer die Messungen ermitteln zu lassen, um sich selbst zu sammeln. Deep Learning kann besser als Menschen herausfinden, welche Teile eines Gesichts wichtig zu messen sind.
Die Lösung besteht darin, ein tiefes faltungsneurales Netzwerk zu trainieren (genau wie in Teil 3). Aber anstatt das Netzwerk so zu trainieren, dass es mehr Objekte erkennt, wie wir es beim letzten Mal getan haben, werden wir es trainieren, um 128 Messungen für jedes Gesicht zu generieren.
Der Trainingsprozess funktioniert, indem 3 Gesichtsbilder gleichzeitig betrachtet werden:
- Laden Sie ein Trainingsgesichtsbild einer bekannten Person
- Laden Sie ein anderes Bild derselben bekannten Person
- Laden Sie ein Bild einer völlig anderen Person
Dann betrachtet der Algorithmus die Messungen, die er derzeit für jedes dieser drei Bilder generiert. Anschließend wird das neuronale Netzwerk leicht optimiert, sodass sichergestellt wird, dass die Messungen, die es für #1 und #2 generiert, etwas näher beieinander liegen, während sichergestellt wird, dass die Messungen für #2 und #3 etwas weiter voneinander entfernt sind:

Nachdem dieser Schritt millionenfach für Millionen von Bildern Tausender verschiedener Personen wiederholt wurde, lernt das neuronale Netzwerk, zuverlässig 128 Messungen für jede Person zu generieren. Zehn verschiedene Bilder derselben Person sollten ungefähr die gleichen Maße ergeben.
Maschinelles Lernen Menschen nennen die 128 Messungen jedes Gesichts eine Einbettung. Die Idee, komplizierte Rohdaten wie ein Bild in eine Liste computergenerierter Zahlen zu reduzieren, kommt beim maschinellen Lernen (insbesondere bei der Sprachübersetzung) häufig vor. Der genaue Ansatz für Gesichter, den wir verwenden, wurde 2015 von Google-Forschern erfunden, aber es gibt viele ähnliche Ansätze.
Codierung unseres Gesichtsbildes
Dieser Prozess des Trainings eines faltungsneuralen Netzwerks zur Ausgabe von Gesichtseinbettungen erfordert eine Menge Daten und Computerleistung. Selbst mit einer teuren NVidia Telsa-Grafikkarte sind etwa 24 Stunden kontinuierliches Training erforderlich, um eine gute Genauigkeit zu erzielen.
Aber sobald das Netzwerk trainiert wurde, kann es Messungen für jedes Gesicht generieren, auch für solche, die es noch nie zuvor gesehen hat! Dieser Schritt muss also nur einmal durchgeführt werden. Glücklicherweise haben die guten Leute von OpenFace dies bereits getan und mehrere trainierte Netzwerke veröffentlicht, die wir direkt nutzen können. Dank Brandon Amos und Team!Alles, was wir selbst tun müssen, ist, unsere Gesichtsbilder durch ihr vortrainiertes Netzwerk zu führen, um die 128 Messungen für jedes Gesicht zu erhalten. Hier sind die Messungen für unser Testbild:

Also, welche Teile des Gesichts messen diese 128 Zahlen genau? Es stellt sich heraus, dass wir keine Ahnung haben. Es spielt für uns keine Rolle. Alles, was uns interessiert, ist, dass das Netzwerk fast die gleichen Zahlen generiert, wenn zwei verschiedene Bilder derselben Person betrachtet werden.
Wenn Sie diesen Schritt selbst ausprobieren möchten, stellt OpenFace ein Lua-Skript zur Verfügung, das Einbettungen aller Bilder in einem Ordner generiert und in eine CSV-Datei schreibt. Sie führen es so.
Schritt 4: Den Namen der Person aus der Kodierung finden
Dieser letzte Schritt ist eigentlich der einfachste Schritt im gesamten Prozess. Alles, was wir tun müssen, ist die Person in unserer Datenbank bekannter Personen zu finden, die unserem Testbild am nächsten kommt.
Sie können dies tun, indem Sie einen beliebigen grundlegenden Klassifizierungsalgorithmus für maschinelles Lernen verwenden. Es sind keine ausgefallenen Deep-Learning-Tricks erforderlich. Wir verwenden einen einfachen linearen SVM-Klassifikator, aber viele Klassifizierungsalgorithmen könnten funktionieren.
Alles, was wir tun müssen, ist einen Klassifikator zu trainieren, der die Messungen von einem neuen Testbild aufnehmen kann und sagt, welche bekannte Person die nächste Übereinstimmung ist. Das Ausführen dieses Klassifikators dauert Millisekunden. Das Ergebnis des Klassifikators ist der Name der Person!
Also lasst uns unser System ausprobieren. Zuerst trainierte ich einen Klassifikator mit den Einbettungen von jeweils etwa 20 Bildern von Will Ferrell, Chad Smith und Jimmy Falon: