Was ist regulärer Ausdruck in Python?
Ein regulärer Ausdruck (RE) in einer Programmiersprache ist eine spezielle Textzeichenfolge, die zur Beschreibung eines Suchmusters verwendet wird. Es ist äußerst nützlich, um Informationen aus Text wie Code, Dateien, Protokollen, Tabellenkalkulationen oder sogar Dokumenten zu extrahieren.
Bei der Verwendung des regulären Python-Ausdrucks ist zunächst zu erkennen, dass alles im Wesentlichen ein Zeichen ist und wir Muster schreiben, die einer bestimmten Zeichenfolge entsprechen, die auch als Zeichenfolge bezeichnet wird. Ascii- oder lateinische Buchstaben befinden sich auf Ihren Tastaturen, und Unicode wird verwendet, um den Fremdtext abzugleichen. Es enthält Ziffern und Satzzeichen und alle Sonderzeichen wie $ #@!% usw.
In diesem Python RegEx Tutorial lernen wir-
- Syntax für reguläre Ausdrücke
- Beispiel für w+ und ^ Ausdruck
- Beispiel für \s Ausdruck in re.split-Funktion
- Mit regulären Ausdrucksmethoden
- Mit re.match()
- Muster im Text finden (re.suche())
- Mit re.findall für Text
- Python Flags
- Beispiel für re.M oder Mehrzeilige Flags
Zum Beispiel könnte ein regulärer Python-Ausdruck ein Programm anweisen, nach einem bestimmten Text aus der Zeichenfolge zu suchen und dann das Ergebnis entsprechend auszudrucken. Der Ausdruck kann
- Textübereinstimmung
- Wiederholung
- Verzweigung
- Musterzusammensetzung usw. enthalten.
Regulärer Ausdruck oder RegEx in Python wird als RE bezeichnet (REs, Regexes oder Regex-Muster) werden über das re-Modul importiert. Python unterstützt reguläre Ausdrücke über Bibliotheken. RegEx in Python unterstützt verschiedene Dinge wie Modifikatoren, Bezeichner und Leerzeichen.
| Bezeichner | Modifikatoren | Leerzeichen | Escape erforderlich |
|---|---|---|---|
| \d= beliebige Zahl (eine Ziffer) | \d steht für eine Ziffer.Ex: \d{1,5} es wird eine Ziffer zwischen 1,5 wie 424,444,545 usw. deklariert. | \n = neue Zeile | . + * ? $ ^ () {} | \ |
| \D= alles andere als eine Zahl (eine Nicht-Ziffer) | + = entspricht 1 oder mehr | \s= Leerzeichen | |
| \s = Leerzeichen (Tabulator, Leerzeichen, Zeilenumbruch usw.) | ? = matches 0 or 1 | \t =tab | |
| \S= anything but a space | * = 0 or more | \e = escape | |
| \w = letters ( Match alphanumeric character, including „_“) | $ match end of a string | \r = carriage return | |
| \W =anything but letters ( Matches a non-alphanumeric character excluding „_“) | ^ match start of a string | \f= form feed | |
| . = anything but letters (periods) | | matches either or x/y | —————– | |
| \b = any character except for new line | = range or „variance“ | —————- | |
| \. | {x} = diese Menge an vorhergehendem Code | —————– |
Regulärer Ausdruck(RE) Syntax
import re
- „re“ -Modul mit Python in erster Linie für String-Suche und Manipulation verwendet
- Auch häufig für Web-Seite „Scraping“ verwendet (extrahieren große Menge an Daten von Websites)
Wir beginnen das Expression-Tutorial mit dieser einfachen Übung, indem wir die Ausdrücke (w+) und (^) verwenden.
Beispiel für w+ und ^ Ausdruck
- „^“: Dieser Ausdruck entspricht dem Anfang einer Zeichenfolge
- „w+“: Dieser Ausdruck entspricht dem alphanumerischen Zeichen in der Zeichenfolge
Hier sehen wir ein Python-RegEx-Beispiel, wie wir verwenden können w+ und ^ Ausdruck in unserem Code. Wir decken die Funktion re.findall() in Python, später in diesem Tutorial, aber für eine Weile konzentrieren wir uns einfach auf \w+ und \^ Ausdruck.
Zum Beispiel für unsere Zeichenfolge „guru99, Bildung macht Spaß“ Wenn wir den Code mit w+ und^ ausführen, wird es die Ausgabe „guru99“ geben.
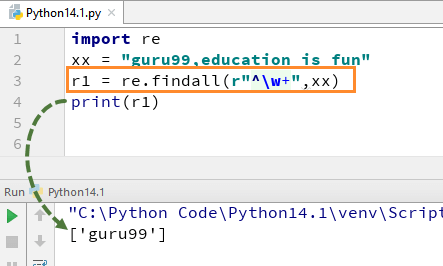
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print(r1)
Denken Sie daran, wenn Sie das Zeichen +aus dem w+entfernen, ändert sich die Ausgabe und gibt nur das erste Zeichen des ersten Buchstabens an, d. H.
Beispiel für \s Ausdruck in re.split-Funktion
- „s“: Dieser Ausdruck wird zum Erstellen eines Leerzeichens in der Zeichenfolge verwendet
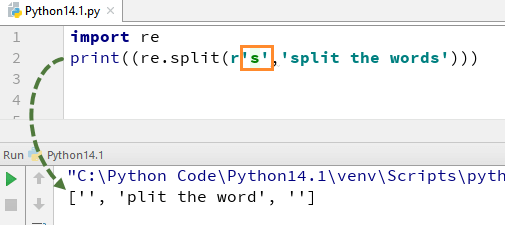
Um zu verstehen, wie diese RegEx in Python funktioniert, beginnen wir mit einem einfachen Python-RegEx-Beispiel einer Split-Funktion. Im Beispiel haben wir jedes Wort mit dem „re.split“ -Funktion und gleichzeitig haben wir den Ausdruck \s verwendet, mit dem jedes Wort in der Zeichenfolge separat analysiert werden kann.

Wenn Sie diesen Code ausführen, erhalten Sie die Ausgabe. Es gibt kein ’s‘-Alphabet in der Ausgabe, dies liegt daran, dass wir ‚\‘ aus der Zeichenfolge entfernt haben, und es wertet „s“ als reguläres Zeichen aus und teilt somit die Wörter dort auf, wo es „s“ in der Zeichenfolge findet.
Ebenso gibt es eine Reihe anderer regulärer Python-Ausdrücke, die Sie in Python auf verschiedene Arten verwenden können, z. B. \d,\D,$,\ .,\b usw.
Hier ist der vollständige Code
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print((re.split(r'\s','we are splitting the words')))print((re.split(r's','split the words')))
Als nächstes werden wir die Arten von Methoden sehen, die mit regulären Ausdrücken in Python verwendet werden.
Reguläre Ausdrucksmethoden verwenden
Das Paket „re“ bietet mehrere Methoden, um tatsächlich Abfragen an einer Eingabezeichenfolge durchzuführen. Wir werden die Methoden von re in Python sehen:
- re.spiel()
- re.suche()
- re.findall()
Hinweis: Basierend auf den regulären Ausdrücken bietet Python zwei verschiedene primitive Operationen. Die match-Methode sucht nur am Anfang der Zeichenfolge nach einer Übereinstimmung, während search an einer beliebigen Stelle in der Zeichenfolge nach einer Übereinstimmung sucht.
re.spiel()
re.die Funktion match() von re in Python durchsucht das Muster für reguläre Ausdrücke und gibt das erste Vorkommen zurück. Die Python-RegEx-Match-Methode sucht nur am Anfang der Zeichenfolge nach einer Übereinstimmung. Wenn also in der ersten Zeile eine Übereinstimmung gefunden wird, wird das Übereinstimmungsobjekt zurückgegeben. Wenn jedoch in einer anderen Zeile eine Übereinstimmung gefunden wird, gibt die Python-RegEx-Übereinstimmungsfunktion null zurück.
Betrachten Sie beispielsweise den folgenden Code von Python re.match() Funktion. Der Ausdruck „w +“ und „\ W“ stimmen mit den Wörtern überein, die mit dem Buchstaben „g“ beginnen, und danach wird alles, was nicht mit „g“ beginnt, nicht identifiziert. Um die Übereinstimmung für jedes Element in der Liste oder Zeichenfolge zu überprüfen, führen wir den forloop in diesem Python-Re aus.spiel() Beispiel.

re.search(): Muster im Text finden
re.die Funktion search () durchsucht das Muster des regulären Ausdrucks und gibt das erste Vorkommen zurück. Im Gegensatz zu Python re.match() überprüft alle Zeilen der Eingabezeichenfolge. Die Python re.die Funktion search() gibt ein Übereinstimmungsobjekt zurück, wenn das Muster gefunden wird, und „null“, wenn das Muster nicht gefunden wird
Um die Funktion search() zu verwenden, müssen Sie zuerst das Python-re-Modul importieren und dann den Code ausführen. Die Python re.search() Funktion nimmt das „Muster“ und „Text“ von unserer Hauptzeichenfolge zu scannen
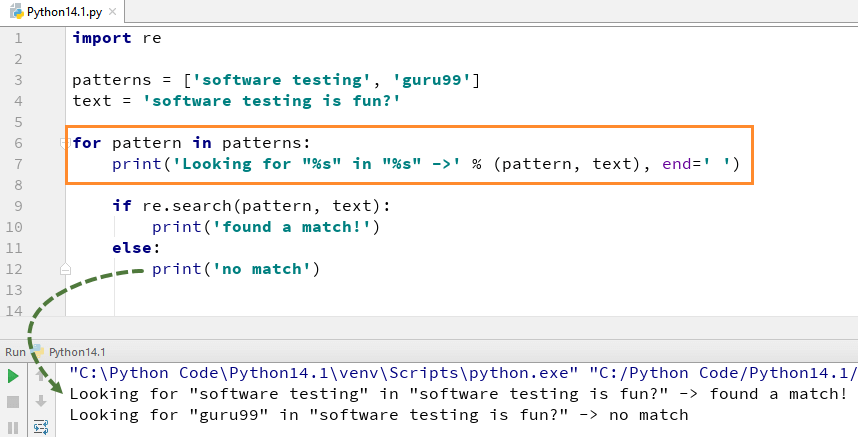
Zum Beispiel suchen wir hier nach zwei literalen Strings „Software testing“ „guru99“, in einer Textzeichenfolge „Software Testing is fun“. Für „Softwaretests“ haben wir die Übereinstimmung gefunden, daher wird die Ausgabe von Python re zurückgegeben.search () Beispiel als „eine Übereinstimmung gefunden“, während wir für das Wort „guru99“ keine Zeichenfolge finden konnten, daher wird die Ausgabe als „Keine Übereinstimmung“ zurückgegeben.
re.findall()
Das Modul findall() wird verwendet, um nach „allen“ Vorkommen zu suchen, die einem bestimmten Muster entsprechen. Im Gegensatz dazu gibt das Modul search () nur das erste Vorkommen zurück, das dem angegebenen Muster entspricht. findall() iteriert über alle Zeilen der Datei und gibt alle nicht überlappenden Übereinstimmungen des Musters in einem einzigen Schritt zurück.
Zum Beispiel, hier haben wir eine Liste von E-Mail-Adressen, und wir wollen alle E-Mail-Adressen aus der Liste geholt werden, wir verwenden die Methode re.findall() in Python. Es werden alle E-Mail-Adressen aus der Liste zu finden.
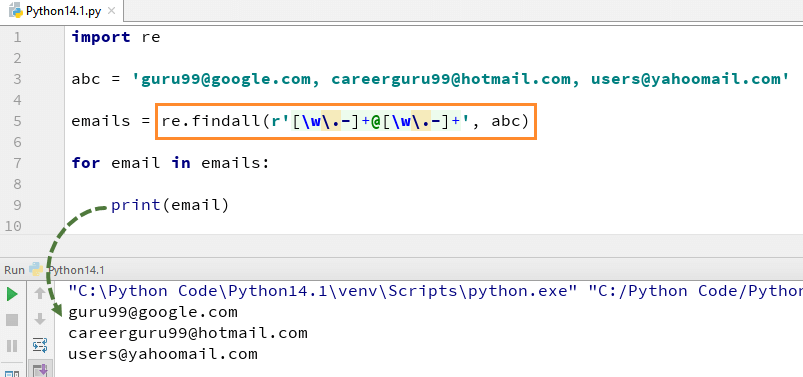
Hier ist der vollständige Code zum Beispiel von re.findall()
import relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print((z.groups())) patterns = text = 'software testing is fun?'for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!')else: print('no match')abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print(email)
Python-Flags
Viele Python-Regex-Methoden und Regex-Funktionen verwenden ein optionales Argument namens Flags. Diese Flags können die Bedeutung des angegebenen Python-Regex-Musters ändern. Um diese zu verstehen, werden wir ein oder zwei Beispiele dieser Flags sehen.
Various flags used in Python includes
| Syntax for Regex Flags | What does this flag do |
|---|---|
| Make begin/end consider each line | |
| It ignores case | |
| Make | |
| Make { \w,\W,\b,\B} follows Unicode rules | |
| Make {\w,\W,\b,\B} follow locale | |
| Allow comment in Regex |
Example of re.M oder Multiline Flags
In multiline entspricht das Musterzeichen dem ersten Zeichen der Zeichenfolge und dem Anfang jeder Zeile (unmittelbar nach jeder neuen Zeile). Der Ausdruck kleines „w“ wird verwendet, um den Raum mit Zeichen zu markieren. Wenn Sie den Code ausführen, druckt die erste Variable „k1“ nur das Zeichen „g“ für word guru99 aus, während beim Hinzufügen eines mehrzeiligen Flags die ersten Zeichen aller Elemente in der Zeichenfolge abgerufen werden.
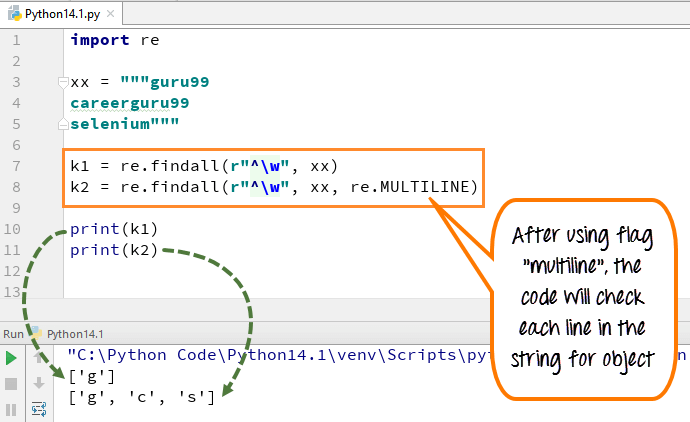
Hier ist der Code
import rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print(k1)print(k2)
- Wir haben die Variable xx für die Zeichenfolge “ guru99…. karriereguru99….selenium“
- Führen Sie den Code ohne Flags multiline, es gibt die Ausgabe nur ‚g‘ aus den Zeilen
- Führen Sie den Code mit Flag „multiline“, wenn Sie drucken ‚k2‘ es gibt die Ausgabe als ‚g‘, ‚c‘ und ’s‘
- Also, der Unterschied, den wir nach und vor dem Hinzufügen von Multi-Zeilen im obigen Beispiel sehen können.
Ebenso können Sie auch andere Python-Flags wie re verwenden.U (Unicode), re.L (Folgen Sie dem Gebietsschema), re.X (Kommentar zulassen) usw.
Python 2 Beispiel
Obige Codes sind Python 3 Beispiele, Wenn Sie in Python 2 ausführen möchten, beachten Sie bitte folgenden Code.
# Example of w+ and ^ Expressionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print r1# Example of \s expression in re.split functionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print (re.split(r'\s','we are splitting the words'))print (re.split(r's','split the words'))# Using re.findall for textimport relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print(z.groups()) patterns = text = 'software testing is fun?'for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!'else: print 'no match'abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print email# Example of re.M or Multiline Flagsimport rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print k1print k2
Zusammenfassung
Ein regulärer Ausdruck in einer Programmiersprache ist eine spezielle Textzeichenfolge, die zur Beschreibung eines Suchmusters verwendet wird. Es enthält Ziffern und Satzzeichen und alle Sonderzeichen wie $ #@!% usw. Der Ausdruck kann literal enthalten
- Textübereinstimmung
- Wiederholung
- Verzweigung
- Musterzusammensetzung usw.
In Python wird ein regulärer Ausdruck als RE bezeichnet (REs, Regexes oder Regex pattern) werden über das Python re Modul eingebettet.
- „re“ -Modul in Python enthalten, das hauptsächlich für die Suche und Manipulation von Zeichenfolgen verwendet wird
- Wird auch häufig für das „Scraping“ von Webseiten verwendet (Extrahieren großer Datenmengen von Websites)
- Zu den regulären Ausdrucksmethoden gehört re.spiel(),re.suche()& re.findall()
- Andere Python-RegEx-Ersetzungsmethoden sind sub() und subn(), mit denen übereinstimmende Zeichenfolgen in re ersetzt werden
- Python-Flags Viele Python-Regex-Methoden und Regex-Funktionen verwenden ein optionales Argument namens Flags
- Diese Flags können die Bedeutung des angegebenen Regex-Musters ändern
- Verschiedene Python-Flags, die in Regex-Methoden verwendet werden, sind re.M, re.Ich, re.S, etc.