Alle Datenbankbenutzer kennen reguläre Aggregatfunktionen, die für eine gesamte Tabelle gelten und mit einer GROUP BY-Klausel verwendet werden. Aber nur sehr wenige Leute verwenden Fensterfunktionen in SQL. Diese arbeiten mit einer Reihe von Zeilen und geben für jede Zeile einen einzelnen aggregierten Wert zurück.
Der Hauptvorteil der Verwendung von Fensterfunktionen gegenüber regulären Aggregatfunktionen ist: Fensterfunktionen führen nicht dazu, dass Zeilen zu einer einzigen Ausgabezeile gruppiert werden, die Zeilen behalten ihre separaten Identitäten bei und jeder Zeile wird ein aggregierter Wert hinzugefügt.
Werfen wir einen Blick darauf, wie Fensterfunktionen funktionieren, und sehen uns dann einige Beispiele für die Verwendung in der Praxis an, um sicherzustellen, dass die Dinge klar sind und wie SQL und Ausgabe mit denen für SUM() -Funktionen verglichen werden.
Stellen Sie wie immer sicher, dass Sie vollständig gesichert sind, insbesondere wenn Sie neue Dinge mit Ihrer Datenbank ausprobieren.
Einführung in Fensterfunktionen
Fensterfunktionen arbeiten mit einer Reihe von Zeilen und geben für jede Zeile einen einzelnen aggregierten Wert zurück. Das Term-Fenster beschreibt den Satz von Zeilen in der Datenbank, für die die Funktion ausgeführt wird.
Wir definieren das Fenster (Satz von Zeilen, auf denen Funktionen arbeitet) mit einer OVER() Klausel. Wir werden mehr über die OVER() Klausel im folgenden Artikel diskutieren.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Wenn Sie ALLE einschließen, werden alle Werte einschließlich doppelter Werte gezählt. DISTINCT wird in Fensterfunktionen nicht unterstützt
expression
Die Zielspalte oder der Ausdruck, mit dem die Funktionen arbeiten. Mit anderen Worten, der Name der Spalte, für die wir einen aggregierten Wert benötigen. Zum Beispiel eine Spalte, die den Bestellbetrag enthält, damit wir die insgesamt eingegangenen Bestellungen sehen können.
OVER
Gibt die Fensterklauseln für Aggregatfunktionen an.
PARTITION BY partition_list
Definiert das Fenster (Satz von Zeilen, auf denen Fensterfunktion arbeitet) für Fensterfunktionen. Wir müssen ein Feld oder eine Liste von Feldern für die Partition nach der PARTITION BY-Klausel bereitstellen. Mehrere Felder müssen wie üblich durch ein Komma getrennt werden. Wenn PARTITION BY nicht angegeben ist, wird die gesamte Tabelle gruppiert und die Werte entsprechend aggregiert.
ORDER BY order_list
Sortiert die Zeilen innerhalb jeder Partition. Wenn ORDER BY nicht angegeben ist, verwendet ORDER BY die gesamte Tabelle.
Beispiele
Lassen Sie uns eine Tabelle erstellen und Dummy-Datensätze einfügen, um weitere Abfragen zu schreiben. Führen Sie den folgenden Code aus.
Fensterfunktionen aggregieren
SUM()
Wir alle kennen die Aggregatfunktion SUM(). Es macht die Summe der angegebenen Felder für die angegebene Gruppe (wie Stadt, Bundesland, Land usw.) oder für die gesamte Tabelle, wenn group nicht angegeben ist. Wir werden sehen, was die Ausgabe der regulären SUM () Aggregatfunktion und der window SUM () Aggregatfunktion sein wird.
Das Folgende ist ein Beispiel für eine reguläre SUM()-Aggregatfunktion. Es summiert den Bestellbetrag für jede Stadt.
Sie können der Ergebnismenge entnehmen, dass eine reguläre Aggregatfunktion mehrere Zeilen in einer einzigen Ausgabezeile gruppiert, wodurch einzelne Zeilen ihre Identität verlieren.
|
1
2
3
4
|
Stadt AUSWÄHLEN, SUMME(order_amount) total_order_amount
VON . NACH Stadt GRUPPIEREN
|

Dies geschieht nicht mit Fensteraggregatfunktionen. Zeilen behalten ihre Identität und zeigen für jede Zeile einen aggregierten Wert an. Im folgenden Beispiel führt die Abfrage dasselbe aus, nämlich aggregiert sie die Daten für jede Stadt und zeigt die Summe der Gesamtbestellmenge für jede von ihnen an. Die Abfrage fügt jedoch jetzt eine weitere Spalte für den Gesamtauftragsbetrag ein, sodass jede Zeile ihre Identität beibehält. Die mit grand_total gekennzeichnete Spalte ist die neue Spalte im folgenden Beispiel.
AVG()
AVG oder Average funktioniert genauso mit einer Fensterfunktion.
Die folgende Abfrage gibt Ihnen die durchschnittliche Bestellmenge für jede Stadt und jeden Monat (obwohl wir der Einfachheit halber nur Daten in einem Monat verwendet haben).
Wir geben mehr als einen Durchschnitt an, indem wir mehrere Felder in der Partitionsliste angeben.
Es ist auch erwähnenswert, dass Sie Ausdrücke in den Listen wie MONTH(order_date) wie in der folgenden Abfrage gezeigt verwenden können. Wie immer können Sie diese Ausdrücke so komplex machen, wie Sie möchten, solange die Syntax korrekt ist!
Aus dem obigen Bild können wir deutlich sehen, dass wir im Durchschnitt Bestellungen von 12.333 für Arlington City für April 2017 erhalten haben.
Durchschnittliche Bestellmenge = Gesamtbestellmenge / Gesamtbestellungen
= (20,000 + 15,000 + 2,000) / 3
= 12.333
Sie können auch die Kombination von SUM() & COUNT() -Funktion, um einen Durchschnitt zu berechnen.
MIN()
Die Aggregatfunktion MIN() ermittelt den Mindestwert für eine bestimmte Gruppe oder für die gesamte Tabelle, wenn group nicht angegeben ist.
Zum Beispiel suchen wir nach der kleinsten Bestellung (Mindestbestellmenge) für jede Stadt, die wir mit der folgenden Abfrage verwenden würden.
MAX()
So wie die MIN() -Funktionen den Minimalwert angeben, identifiziert die MAX() -Funktion den größten Wert eines angegebenen Felds für eine bestimmte Zeilengruppe oder für die gesamte Tabelle, wenn keine Gruppe angegeben ist.
Lassen Sie uns die größte Bestellung (maximale Bestellmenge) für jede Stadt finden.
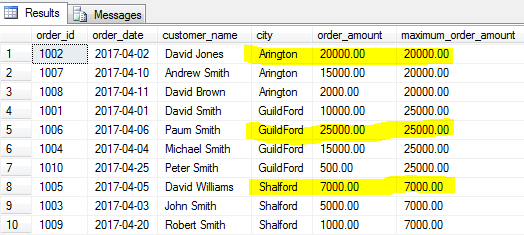
COUNT()
Die Funktion COUNT() zählt die Datensätze / Zeilen.
Beachten Sie, dass DISTINCT nicht mit der window COUNT() -Funktion unterstützt wird, während es für die reguläre COUNT() -Funktion unterstützt wird. DISTINCT hilft Ihnen, die unterschiedlichen Werte eines bestimmten Feldes zu finden.
Wenn wir beispielsweise sehen möchten, wie viele Kunden im April 2017 eine Bestellung aufgegeben haben, können wir nicht alle Kunden direkt zählen. Es ist möglich, dass derselbe Kunde im selben Monat mehrere Bestellungen aufgegeben hat.
COUNT(customer_name) gibt Ihnen ein falsches Ergebnis, da Duplikate gezählt werden. Während COUNT(DISTINCT customer_name) Ihnen das richtige Ergebnis liefert, da es jeden eindeutigen Kunden nur einmal zählt.
Gültig für die reguläre Funktion COUNT():
|
1
2
3
4
5
|
Stadt AUSWÄHLEN, ANZAHL(EINDEUTIGER Kundenname) Anzahl der Kunden
VON .
GRUPPE NACH Stadt
|
Ungültig für die Funktion window COUNT():
Die obige Abfrage mit der Fensterfunktion gibt Ihnen den folgenden Fehler.
Lassen Sie uns nun die Gesamtbestellung für jede Stadt mit der Funktion window COUNT() ermitteln.
Ranking-Fensterfunktionen
So wie Fensteraggregatfunktionen den Wert eines bestimmten Feldes aggregieren, ordnen RANKING-Funktionen die Werte eines bestimmten Feldes und kategorisieren sie nach ihrem Rang.
Die häufigste Verwendung von RANKING-Funktionen besteht darin, die obersten (N) Datensätze basierend auf einem bestimmten Wert zu finden. Zum Beispiel Top 10 bestbezahlte Mitarbeiter, Top 10 Studenten, Top 50 größte Aufträge usw.
Folgende RANKING-Funktionen werden unterstützt:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
Lassen Sie uns eins nach dem anderen diskutieren.
RANK()
Mit der Funktion RANK() wird jedem Datensatz ein eindeutiger Rang zugewiesen, der auf einem bestimmten Wert basiert, z. B. Gehalt, Bestellbetrag usw.
Wenn zwei Datensätze denselben Wert haben, weist die Funktion RANK() beiden Datensätzen denselben Rang zu, indem der nächste Rang übersprungen wird. Das bedeutet – wenn es zwei identische Werte auf Rang 2 gibt, wird beiden Datensätzen derselbe Rang 2 zugewiesen und dann Rang 3 übersprungen und Rang 4 dem nächsten Datensatz zugewiesen.
Ordnen wir jede Bestellung nach ihrer Bestellmenge.
|
1
2
3
4
5
|
WÄHLEN SIE order_id, order_date,customer_name, Stadt,
RANG() ÜBER(ORDER BY order_amount DESC)
VON .
|
Aus dem obigen Bild können Sie sehen, dass der gleiche Rang (3) zwei identischen Datensätzen zugewiesen wird (jeder mit einer Bestellmenge von 15.000) und dann der nächste Rang 4) und ordnen Rang 5 zum nächsten Datensatz.
DENSE_RANK()
Die Funktion DENSE_RANK() ist identisch mit der Funktion RANK(), außer dass sie keinen Rang überspringt. Dies bedeutet, dass, wenn zwei identische Datensätze gefunden werden, DENSE_RANK() beiden Datensätzen denselben Rang zuweist, aber nicht den nächsten Rang überspringt.
Mal sehen, wie das in der Praxis funktioniert.
Wie Sie oben deutlich sehen können, wird zwei identischen Datensätzen derselbe Rang zugewiesen (jeder mit dem gleichen Bestellbetrag) und dann wird dem nächsten Datensatz die nächste Rangnummer zugewiesen, ohne einen Rangwert zu überspringen.
ROW_NUMBER()
Der Name ist selbsterklärend. Diese Funktionen weisen jedem Datensatz eine eindeutige Zeilennummer zu.
Die Zeilennummer wird für jede Partition zurückgesetzt, wenn PARTITION BY angegeben ist. Mal sehen, wie ROW_NUMBER() ohne PARTITION BY und dann mit PARTITION BY .
ROW_NUMBER() ohne PARTITION VON
ROW_NUMBER() mit PARTITION VON
Beachten Sie, dass wir die Partition auf Stadt gemacht haben. Dies bedeutet, dass die Zeilennummer für jede Stadt zurückgesetzt wird und somit wieder bei 1 neu gestartet wird. Die Reihenfolge der Zeilen wird jedoch durch den Bestellbetrag bestimmt, so dass für jede gegebene Stadt der größte Bestellbetrag die erste Zeile ist und somit die Zeilennummer 1 zugewiesen wird.
NTILE()
NTILE() ist eine sehr hilfreiche Fensterfunktion. Es hilft Ihnen zu identifizieren, in welches Perzentil (oder Quartil oder eine andere Unterteilung) eine bestimmte Zeile fällt.
Dies bedeutet, dass Sie, wenn Sie 100 Zeilen haben und 4 Quartile basierend auf einem angegebenen Wertefeld erstellen möchten, dies einfach tun und sehen können, wie viele Zeilen in jedes Quartil fallen.
Sehen wir uns ein Beispiel an. In der folgenden Abfrage haben wir angegeben, dass wir vier Quartile basierend auf der Bestellmenge erstellen möchten. Wir wollen dann sehen, wie viele Aufträge in jedes Quartil fallen.
NTILE erstellt Kacheln basierend auf der folgenden Formel:
Anzahl der Zeilen in jeder Kachel = Anzahl der Zeilen in der Ergebnismenge / Anzahl der angegebenen Kacheln
Hier ist unser Beispiel, wir haben insgesamt 10 Zeilen und 4 Kacheln sind in der Abfrage angegeben, so dass die Anzahl der Zeilen in jeder Kachel 2,5 (10/4) beträgt. Die Anzahl der Zeilen sollte eine ganze Zahl sein, keine Dezimalzahl. SQL Engine weist 3 Zeilen für die ersten beiden Gruppen und 2 Zeilen für die verbleibenden zwei Gruppen zu.
Wertefensterfunktionen
LAG() und LEAD()
Die Funktionen LEAD() und LAG() sind sehr leistungsfähig, können aber komplex zu erklären sein.
Da dies ein einführender Artikel ist, betrachten wir ein sehr einfaches Beispiel, um zu veranschaulichen, wie man sie benutzt.
Die LAG-Funktion ermöglicht den Zugriff auf Daten aus der vorherigen Zeile in derselben Ergebnismenge ohne Verwendung von SQL-Joins. Sie können im folgenden Beispiel sehen, mit der LAG-Funktion haben wir das vorherige Bestelldatum gefunden.
Skript zum Auffinden des vorherigen Bestelldatums mithilfe der Funktion LAG():
Die LEAD-Funktion ermöglicht den Zugriff auf Daten aus der nächsten Zeile in derselben Ergebnismenge ohne Verwendung von SQL-Joins. Sie können im folgenden Beispiel sehen, dass wir mit der LEAD-Funktion das nächste Bestelldatum gefunden haben.
Skript zum Finden des nächsten Bestelldatums mithilfe der Funktion LEAD():
FIRST_VALUE() und LAST_VALUE()
Diese Funktionen helfen Ihnen, den ersten und letzten Datensatz innerhalb einer Partition oder einer gesamten Tabelle zu identifizieren, wenn PARTITION BY nicht angegeben ist.
Lassen Sie uns die erste und letzte Reihenfolge jeder Stadt aus unserem vorhandenen Datensatz ermitteln. Hinweis ORDER BY Klausel ist obligatorisch für FIRST_VALUE() und LAST_VALUE() Funktionen
Aus dem obigen Bild können wir deutlich sehen, dass die erste Bestellung am 02.04.2017 und die letzte Bestellung am 11.04.2017 für Arlington City eingegangen ist und für andere Städte genauso funktioniert.
Nützliche Links
- Backup-Typen & Strategien für SQL-Datenbanken
- TechNet-Artikel über die OVER-Klausel
- MSDN-Artikel über DENSE_RANK
Weitere großartige Artikel von Ben
Wie SQL Server ein Deadlock-Opfer auswählt
Fensterfunktionen
- Autor
- Letzte Beiträge
Alle Beiträge von Ben Richardson anzeigen
- Power BI: Wasserfalldiagramme und kombinierte Grafiken – 19. Januar 2021
- Power BI: Bedingte Formatierung und Datenfarben in Aktion – 14. Januar 2021
- Power BI: Importieren von Daten aus SQL Server und MySQL – 12. Januar 2021