Kasvontunnistus — askel askeleelta
puututaan tähän ongelmaan askel kerrallaan. Jokainen vaihe, opimme eri koneoppimisen algoritmi. En aio selittää jokaista algoritmia kokonaan, jotta tämä ei muuttuisi kirjaksi, mutta opit pääideat jokaisen takana ja opit, miten voit rakentaa oman kasvojentunnistusjärjestelmän Pythonissa Openfacen ja dlib: n avulla.
Vaihe 1: Kaikkien kasvojen löytäminen
ensimmäinen vaihe putkessamme on kasvojentunnistus. On selvää, että kasvot on löydettävä valokuvasta, ennen kuin niitä voi yrittää erottaa toisistaan!
Jos olet käyttänyt jotain kameraa viimeisen 10 vuoden aikana, olet todennäköisesti nähnyt kasvojentunnistuksen toiminnassa:

kasvojentunnistus on loistava ominaisuus kameroille. Kun kamera voi automaattisesti valita kasvot, se voi varmistaa, että kaikki kasvot ovat tarkentuneet ennen kuin se ottaa kuvan. Mutta käytämme sitä eri tarkoitukseen-löytää alueet kuvan haluamme siirtää seuraavaan vaiheeseen meidän putki.
kasvojentunnistus nousi valtavirtaan 2000-luvun alussa, kun Paul Viola ja Michael Jones keksivät keinon tunnistaa kasvoja, jotka toimivat riittävän nopeasti halvoilla kameroilla. Nyt on kuitenkin olemassa paljon luotettavampia ratkaisuja. Aiomme käyttää vuonna 2005 keksittyä menetelmää nimeltä suunnattujen kaltevuuksien Histogrammi — tai lyhyesti HOG.
kasvojen löytämiseksi kuvasta aloitetaan tekemällä kuva mustavalkoiseksi, koska kasvojen löytämiseen ei tarvita väridataa:

sitten katsomme jokaista kuvamme pikseliä yksi kerrallaan. Haluamme tarkastella jokaista pikseliä ympäröiviä pikseleitä.:

tavoitteenamme on selvittää, kuinka tumma nykyinen pikseli on verrattuna sitä suoraan ympäröiviin pikseleihin. Sitten haluamme piirtää nuolen, joka näyttää, mihin suuntaan kuva tummuu.:

Jos toistat kyseisen prosessin kuvan jokaiselle pikselille, päädyt siihen, että jokainen pikseli korvataan nuolella. Näitä nuolia kutsutaan gradienteiksi ja ne näyttävät virtauksen valosta pimeään koko Kuvassa:
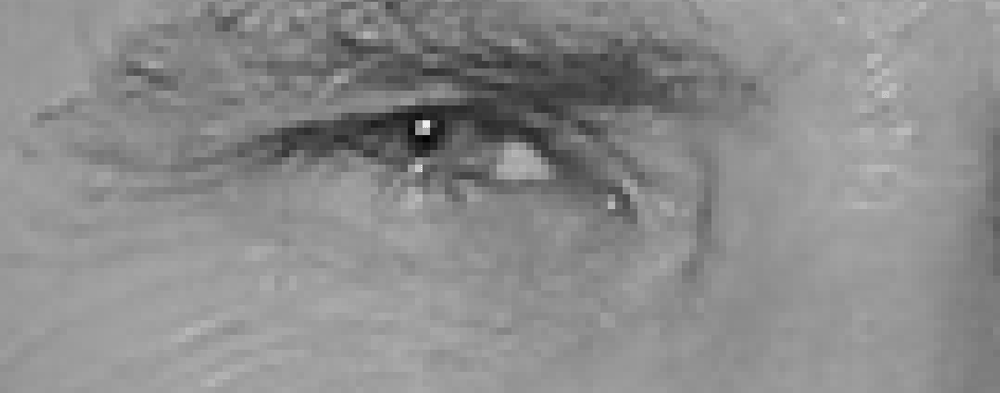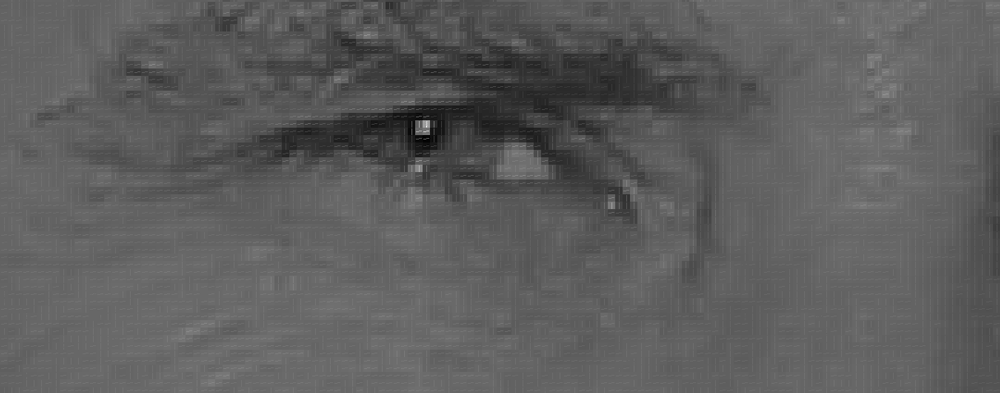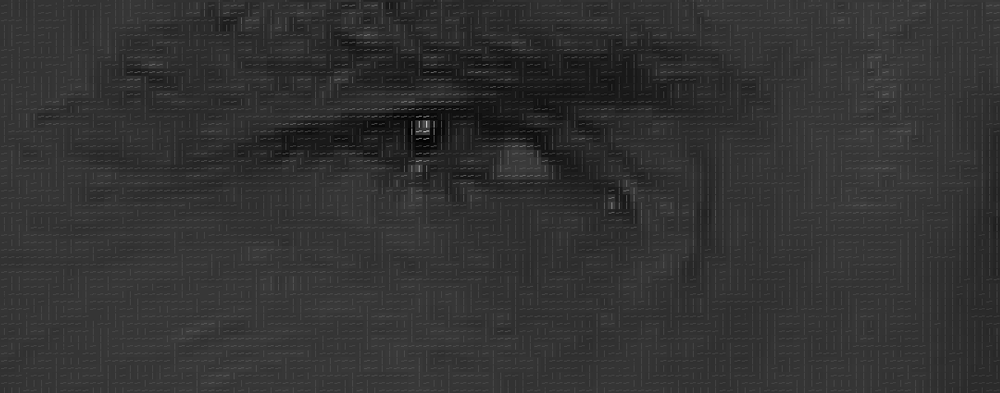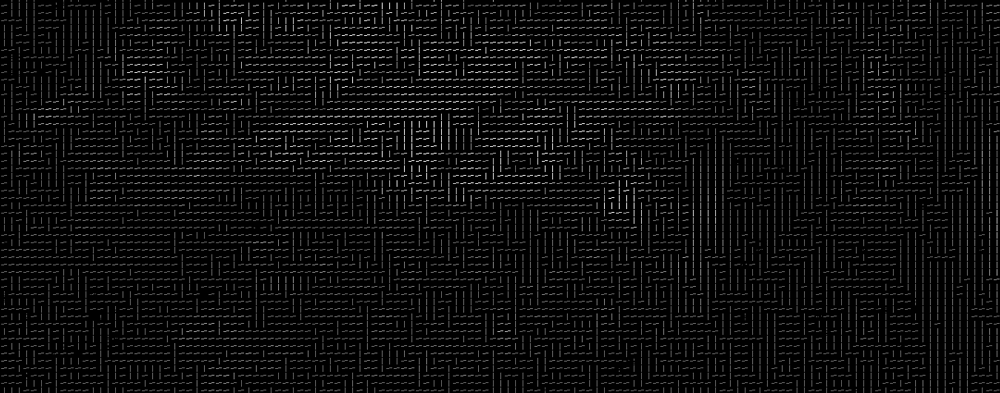
tämä saattaa tuntua satunnaiselta, mutta pikselien korvaamiselle gradienteilla on todella hyvä syy. Jos analysoimme pikseleitä suoraan, saman henkilön todella tummilla kuvilla ja todella kevyillä kuvilla on täysin erilaiset pikseliarvot. Mutta vain pohtimalla, mihin suuntaan kirkkaus muuttuu, sekä todella tummat kuvat että todella kirkkaat kuvat päätyvät samaan täsmälliseen esitykseen. Se tekee ongelman paljon helpompi ratkaista!
mutta jokaisen pikselin gradientin tallentaminen antaa meille aivan liikaa yksityiskohtia. Jäämme kaipaamaan metsää puiden takia. Olisi parempi, jos voisimme vain nähdä valoisuuden/pimeyden perusvirran korkeammalla tasolla, jotta näkisimme kuvan peruskuvion.
tätä varten hajotamme kuvan pieniin ruutuihin, joissa kussakin on 16×16 pikseliä. Kussakin neliössä, me laskea, kuinka monta gradientit osoittavat kunkin suuren suuntaan (kuinka monta kohta ylös, kohta ylös-oikea, kohta oikealle, jne…). Sitten vaihdamme kuvan ruudun nuolisuuntiin, jotka olivat vahvimmat.
lopputulos on, että muutamme alkuperäisen kuvan hyvin yksinkertaiseksi kuvaukseksi, joka vangitsee kasvojen perusrakenteen yksinkertaisella tavalla:

löytääksemme kasvot tästä SIKAKUVASTA, meidän tarvitsee vain löytää se osa kuvaamme, joka muistuttaa eniten tunnettua SIKAKUVIOTA, joka on poimittu joukosta muita treenikasvoja:

tällä tekniikalla voidaan nyt helposti löytää kasvoja mistä tahansa kuvasta:

Jos haluat kokeilla tätä askelta itse pythonin ja dlib: n avulla, tässä on koodi, joka näyttää kuinka luoda ja tarkastella Hog-kuvia.
Vaihe 2: poseeraavat ja projisoivat Kasvot
erotimme Kasvot kuvaamme. Mutta nyt meidän täytyy käsitellä ongelmaa, että kasvot kääntyi eri suuntiin näyttää täysin eri tietokoneeseen:

tämän vuoksi pyrimme vääristämään jokaista kuvaa niin, että silmät ja huulet ovat aina otospaikalla kuvassa. Tämä helpottaa kasvojen vertailua seuraavissa vaiheissa.
tähän käytetään algoritmia nimeltä face landmark estimation. Keinoja on monia, mutta aiomme käyttää Vahid Kazemin ja Josephine Sullivanin vuonna 2014 keksimää lähestymistapaa.
perusidea on, että keksimme 68 tiettyä kohtaa (joita kutsutaan maamerkeiksi), joita on jokaisella kasvolla — leuan yläosa, kunkin silmän ulkoreuna, jokaisen kulmakarvan sisäreuna jne. Sitten koulutamme koneoppimisen algoritmin, jotta voimme löytää nämä 68 tiettyä kohtaa miltä tahansa kasvolta.:

tässä tulos 68 kasvopaikan paikantamisesta testikuvassamme:

nyt kun tiedämme, että silmät ja suu ovat, pyöritämme, Skaalaamme ja leikkaamme kuvaa niin, että silmät ja suu ovat mahdollisimman keskitettyjä. Emme tee mitään hienoja 3d-vääntöjä, koska se toisi vääristymiä kuvaan. Käytämme vain peruskuvan muunnoksia, kuten rotaatiota ja mittakaavaa, jotka säilyttävät yhdensuuntaiset viivat (kutsutaan affiinimuunnoksiksi):

nyt ei ole väliä miten kasvot käännetään, pystymme keskittämään silmät ja suu ovat kuvassa suurin piirtein samassa asennossa. Tämä tekee seuraavasta askeleesta paljon tarkemman.
Jos haluat kokeilla tätä askelta itse Pythonin ja dlib: n avulla, tässä on koodi kasvojen maamerkkien löytämiseen ja tässä koodi kuvan muuttamiseen näiden maamerkkien avulla.
Vaihe 3: Koodaamalla kasvoja
nyt ollaan ongelman lihassa — itse asiassa erotellaan Kasvot toisistaan. Tässä kohtaa asiat muuttuvat todella mielenkiintoisiksi!
yksinkertaisin lähestymistapa kasvojentunnistukseen on verrata suoraan vaiheessa 2 löytämiämme tuntemattomia kasvoja kaikkiin kuviimme ihmisistä, jotka on jo merkitty. Kun löydämme aiemmin merkityt kasvot, jotka näyttävät hyvin samanlaisilta kuin tuntemattomat kasvomme, sen täytyy olla sama henkilö. Kuulostaa hyvältä idealta.
siinä lähestymistavassa on oikeastaan valtava ongelma. Sivusto, kuten Facebook, jossa on miljardeja käyttäjiä ja biljoona kuvaa, ei voi mitenkään kiertää jokaisen aiemmin merkityn kasvon läpi vertaillakseen sitä jokaiseen äskettäin ladattuun kuvaan. Se veisi aivan liian kauan. Heidän pitää pystyä tunnistamaan kasvot millisekunneissa, ei tunneissa.
tarvitaan tapa, jolla jokaisesta kasvosta saadaan poimittua muutama perusmitta. Sitten voisimme mitata tuntemattomat kasvot samalla tavalla ja löytää tunnetut kasvot lähimmillä mittauksilla. Voisimme esimerkiksi mitata kunkin korvan koon,silmien välisen etäisyyden, nenän pituuden jne. Jos olet joskus katsonut CSI: n kaltaista huonoa rikosohjelmaa, tiedät mistä puhun:
div>
luotettavin tapa mitata Kasvot
Ok, joten mitä mittoja meidän pitäisi kerätä jokaiselta kasvolta rakentaaksemme tunnetun kasvotietokantamme? Korvan koko? Nenän pituus? Silmien väri? Jotain muuta?
kävi ilmi, että meille ihmisille itsestään selviltä näyttävissä mittauksissa (kuten silmien värissä) ei ole mitään järkeä, jos tietokone katsoo yksittäisiä pikseleitä kuvassa. Tutkijat ovat havainneet, että tarkin lähestymistapa on antaa tietokoneen selvittää mittauksia kerätäkseen itse. Syväoppiminen tekee ihmistä parempaa työtä sen selvittämisessä, mitkä kasvojen osat ovat tärkeitä mitata.
ratkaisu on kouluttaa syvä Convolutionaalinen neuroverkko (aivan kuten teimme osassa 3). Mutta sen sijaan, että koulutamme verkoston tunnistamaan kuvia, kuten viimeksi, – aiomme kouluttaa sen tuottamaan 128 mittausta jokaiselle kasvolle.
harjoitusprosessi toimii katsomalla 3 kasvokuvaa kerrallaan:
- Lataa treenikasvokuva tunnetusta henkilöstä
- lataa toinen kuva samasta tunnetusta henkilöstä
- Lataa kuva täysin eri henkilöstä
sitten algoritmi katsoo mittoja, joita se tällä hetkellä tuottaa kullekin näistä kolmesta kuvasta. Sen jälkeen se hienosäätää neuroverkkoa hieman niin, että se varmistaa #1: lle ja #2: lle tuottamiensa mittausten olevan hieman lähempänä ja varmistaa samalla, että #2: n ja #3: n mittaukset ovat hieman kauempana toisistaan:

toistettuaan tämän vaiheen miljoonia kertoja miljoonille kuville tuhansista eri ihmisistä neuroverkko oppii tuottamaan luotettavasti 128 mittausta jokaista henkilöä kohti. Kaikki kymmenen eri kuvaa samasta henkilöstä pitäisi antaa suurin piirtein samat mitat.
Koneoppineet kutsuvat jokaisen kasvon 128 mittausta upotukseksi. Ajatus monimutkaisten raakadatan, kuten kuvan, vähentämisestä tietokoneella luotujen lukujen luetteloksi tulee esiin paljon koneoppimisessa (erityisesti kielenkääntämisessä). Tarkka lähestymistapa Kasvot käytämme keksittiin vuonna 2015 tutkijat Google, mutta monia vastaavia lähestymistapoja on olemassa.
kasvokuvamme koodaaminen
Tämä prosessi, jossa convolutionaalinen neuroverkko koulutetaan tuottamaan kasvojen upotuksia, vaatii paljon dataa ja tietokonetehoa. Jopa kalliilla NVidia Telsa-näytönohjaimella hyvän tarkkuuden saavuttaminen vaatii noin 24 tuntia jatkuvaa harjoittelua.
mutta kun verkko on koulutettu, se voi tuottaa mittoja mille tahansa kasvolle, jopa sellaisille, joita se ei ole ennen nähnyt! Joten tämä vaihe tarvitsee tehdä vain kerran. Onneksemme, hieno ihmiset openface jo tehnyt tämän ja he julkaisivat useita koulutettuja verkostoja, joita voimme suoraan käyttää. Kiitos Brandon Amos ja joukkue!
joten kaikki mitä meidän tarvitsee tehdä itse, on ajaa kasvokuvamme heidän ennalta koulutetun verkostonsa kautta, jotta saamme 128 mittausta jokaiselle kasvolle. Tässä testikuvan mitat:

mitä Tahkon osia nämä 128 lukua tarkalleen mittaavat? Meillä ei ole aavistustakaan. Sillä ei ole väliä meille. Välitämme vain siitä, että verkko tuottaa lähes samat numerot, kun katsoo kahta eri kuvaa samasta henkilöstä.
Jos haluat kokeilla tätä vaihetta itse, OpenFace tarjoaa lua-skriptin, joka luo upotukset kaikki kuvat kansioon ja kirjoittaa ne csv-tiedostoon. Pyöritä sitä näin.
Vaihe 4: henkilön nimen löytäminen koodauksesta
Tämä viimeinen vaihe on itse asiassa helpoin vaihe koko prosessissa. Meidän täytyy vain löytää tietokannastamme henkilö, jolla on lähimmät mitat testikuvastamme.
sen voi tehdä millä tahansa koneoppimisen perustason luokittelualgoritmilla. Mitään hienoja syväoppimistemppuja ei tarvita. Käytämme yksinkertaista lineaarista SVM-luokittelijaa, mutta monet luokittelualgoritmit voisivat toimia.
meidän tarvitsee vain kouluttaa luokittelija, joka voi ottaa mitat uudesta testikuvasta ja kertoo, kuka tunnettu henkilö on lähin vastine. Tämän luokittelijan suorittaminen vie millisekunteja. Luokittelijan tulos on henkilön nimi!
kokeillaan siis systeemiä. Ensin koulutin luokittelijan, jolla oli noin 20 kuvaa jokaisesta Will Ferrellistä, Chad Smithistä ja Jimmy Falonista: