
tässä tutoriaalissa opit logistista regressiota. Täällä tiedät, mitä on logistinen regressio, ja näet myös esimerkin Pythonilla. Logistinen regressio on tärkeä koneoppimisen aihe ja yritän tehdä siitä mahdollisimman yksinkertaista.
1900-luvun alussa logistista regressiota käytettiin lähinnä biologiassa tämän jälkeen, sitä käytettiin joissakin yhteiskuntatieteellisissä sovelluksissa. Jos olet utelias, saatat kysyä, missä meidän pitäisi käyttää logistista regressiota? Käytämme siis logistista regressiota, kun itsenäinen muuttujamme on kategorinen.
esimerkkejä:
- ennustaaksemme, ostaako henkilö auton (1) vai (0)
- tietääksemme, onko kasvain pahanlaatuinen (1) vai (0)
nyt tarkastellaan skenaariota, jossa on luokiteltava, ostaako henkilö auton vai ei. Tässä tapauksessa, jos käytämme yksinkertaista lineaarista regressiota, meidän on määriteltävä kynnys, jolle luokittelu voidaan tehdä.
sanotaan, että todellinen luokka on henkilö, joka ostaa auton, ja ennustettu jatkuva arvo on 0,45 ja tarkastelemamme raja-arvo on 0.5, Sitten tätä datapistettä pidetään henkilönä, joka ei osta autoa, ja tämä johtaa väärään ennusteeseen.
näin voimme päätellä, että emme voi käyttää lineaarista regressiota tämäntyyppiseen luokitteluongelmaan. Kuten tiedämme lineaarinen regressio on rajoitettu, joten tässä tulee logistinen regressio, jossa arvo tiukasti vaihtelee 0: sta 1: een.
yksinkertainen logistinen regressio:
lähtö: 0 tai 1
hypoteesi: K = W * X + b
hΘ(x) = sigmoid(K)
Sigmoid-funktio:


logistisen Regression tyypit:
binäärisen logistisen Regression
vain kaksi mahdollista lopputulosta(Luokka).
esimerkki:henkilö ostaa auton tai ei.
monikansallinen logistinen regressio
yli kaksi luokkaa mahdollista ilman tilausta.
Ordinaalinen logistinen regressio
enemmän kuin kaksi luokkaa mahdollista järjestämällä.
reaalimaailman esimerkki Pythonilla:
nyt ratkaistaan reaalimaailman ongelma Logistisella regressiolla. Meillä on tietojoukko, jossa on 5 saraketta eli: käyttäjätunnus, sukupuoli, ikä, arvioitu Salary ja ostettu. Nyt meidän on rakennettava malli, joka voi ennustaa, ostaako henkilö annetulla parametrilla auton vai ei.
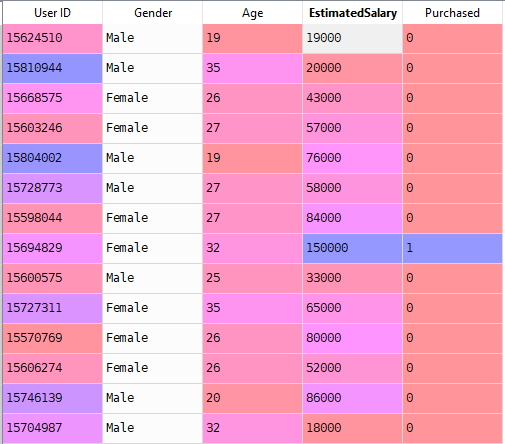
mallin rakentamisen vaiheet:
1. Importing the libraries
tänne tuodaan kirjastoja, joita tarvitaan mallin rakentamiseen.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
tuomme tietokokonaisuutemme muuttujana (eli datajoukkona) käyttäen pandoja.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
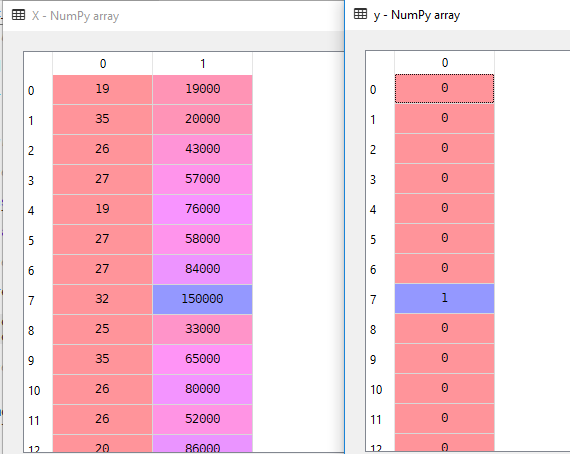
aineistossamme pidämme ikää ja estimoitua muuttujaa itsenäisenä muuttujana ja ostettuna riippuvaisena muuttujana.
X = dataset.iloc].valuesy = dataset.iloc.valuestässä X on itsenäinen muuttuja ja y on riippuvainen muuttuja.
3. Splitting the Data set into the Training Set and Test Set
Harjoitustietoja käytetään
logistisen mallimme kouluttamiseen ja testitietoja käytetään mallimme validointiin. Käytämme Sklearnia jakaaksemme tietomme. Tuomme train_test_splitin sklearnista.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
nyt teemme ominaisuus skaalaus skaalata tietoja välillä 0 ja 1 saada parempaa tarkkuutta.
tässä skaalaus on tärkeää, koska iän ja arvioidun päivän välillä on valtava ero.
- tuo StandardScaler sklearnista.esikäsittely
- tee sitten instanssi sc_X objektista StandardScaler
- sitten Sovita ja transform X_train and transform X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
nyt rakennetaan luokittelijamme (logistinen).
- tuo logistiikkarepressio sklearnilta.linear_model
- tee objektilogisticregression instanssiluokittaja ja anna
random_state = 0, jotta saadaan joka kerta sama tulos. - Käytä Nyt tätä luokittelijaa sovittaaksesi X_train ja y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Kippis!! Suoritettuaan edellä komennon sinulla on luokittelija, joka voi ennustaa, ostaako henkilö auton vai ei.
käytä luokittelijaa nyt testiaineiston ennustamiseen ja tarkkuuden etsimiseen Sekaannusmatriisin avulla.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)nyt saadaan y_pred

nyt voimme käyttää y_testiä (todellinen tulos) ja y_prediä ( ennustettu tulos) saadaksemme mallimme tarkkuuden.
7. Making the Confusion Matrix
Sekaannusmatriisin avulla saadaan mallimme tarkkuus.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)saat matriisin cm .

käytä cm: ää tarkkuuden laskemiseen alla esitetyllä tavalla:
tarkkuus = ( cm + cm) /(testin kokonaispisteet)

tässä saadaan 89 prosentin tarkkuus . Kippis!! saamme hyvää tarkkuutta.
lopuksi visualisoidaan Treenisarjan tulos ja testisarjan tulos. Käytämme matplotlibia piirtääksemme tietomme.
harjoitussarjan tuloksen visualisointi
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()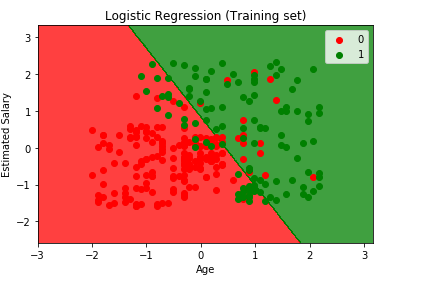
testisarjan tuloksen visualisointi
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
nyt voit rakentaa oman luokittelijan logistista regressiota varten.
Thanks!! Jatkakaa Koodausta !!
Huom: Tämä on vieraileva viesti, ja mielipide tässä artikkelissa on vierailevasta kirjoittajasta. Jos sinulla on ongelmia jonkin artikkeleita lähetetty www.marktechpost.com please contact at [email protected]
Advertisement
