mikä on säännöllinen lauseke Pythonissa?
säännöllinen lauseke (RE) ohjelmointikielessä on erityinen tekstimerkkijono, jota käytetään hakukuvion kuvaamiseen. Se on erittäin hyödyllinen tietojen purkamiseen tekstistä, kuten koodista, tiedostoista, lokista, laskentataulukoista tai jopa asiakirjoista.
Python-säännöllistä lauseketta käytettäessä on ensimmäiseksi tunnistettava, että kaikki on pohjimmiltaan merkkiä, ja kirjoitamme kuvioita vastaamaan tiettyä merkkijonoksi kutsuttua merkkisarjaa. ASCII tai latinalaiset kirjaimet ovat niitä, jotka ovat näppäimistöissä ja Unicode käytetään vastaamaan ulkomaista tekstiä. Se sisältää numeroita ja välimerkkejä ja kaikki erikoismerkit, kuten $#@!% jne.
tässä Python RegEx – opetusohjelmassa opimme –
- säännöllisen lausekkeen syntaksi
- esimerkki w+: sta ja ^ lausekkeen
- esimerkki \s lausekkeesta re: ssä.jakofunktio
- käyttäen säännöllisen lausekkeen menetelmiä
- käyttäen re.match ()
- Löytökuvio tekstissä (re.haku ())
- käyttäen re.findall tekstille
- Python Liput
- esimerkki re: stä.M-tai Moniriviliput
esimerkiksi Pythonin säännöllinen lauseke voisi kertoa ohjelman etsivän merkkijonosta tiettyä tekstiä ja tulostavan tuloksen sen mukaisesti. Lauseke voi sisältää
- tekstisovitus
- Haaroittaminen
- kuvio-sommittelu jne.
toisto
säännöllinen lauseke tai RegEx Pythonissa merkitään re (REs, regexes tai regex pattern) tuodaan re-moduulin kautta. Python tukee säännöllistä lauseketta kirjastojen kautta. RegEx Pythonissa tukee erilaisia asioita, kuten modifioijia, tunnisteita ja valkoisia välilyöntimerkkejä.
| Identifiers | Modifiers | valkoiset avaruusmerkit | |
|---|---|---|---|
| \D= Mikä tahansa luku (numero) | \d edustaa numeroa.Ex: \d{1,5} se ilmoittaa numeron välillä 1,5, kuten 424,444,545 jne. | \n = uusi rivi | . + * ? $ ^ () {} | \ |
| \d = anything but a non-digit) | += matches 1 or more | \s = space | \s = space (tab,space,newline jne.) | ? = matches 0 or 1 | \t =tab |
| \S= anything but a space | * = 0 or more | \e = escape | |
| \w = letters ( Match alphanumeric character, including ”_”) | $ match end of a string | \r = carriage return | |
| \W =anything but letters ( Matches a non-alphanumeric character excluding ”_”) | ^ match start of a string | \f= form feed | |
| . = anything but letters (periods) | | matches either or x/y | —————– | |
| \b = any character except for new line | = range or ”variance” | —————- | |
| \. | {x} = tämä edellisen koodin määrä | —————– |
säännöllinen lauseke(RE) syntaksi
import re
- ”re” – moduuli, joka sisältyy Pythoniin ja jota käytetään pääasiassa merkkijonojen etsintään ja manipulointiin
- käytetään usein myös web-sivun ”kaavintaan” (Pura suuri määrä data from websites)
aloitamme lausekkeen opetusohjelman tällä yksinkertaisella harjoituksella käyttämällä lausekkeita (W+) ja (^).
esimerkki w+ – ja ^ – lausekkeesta
- ”^”: Tämä lauseke vastaa merkkijonon alkua
- ”w+”: tämä lauseke vastaa merkkijonon aakkosnumeerista merkkiä
Tässä näemme Python RegEx-esimerkin siitä, miten voimme käyttää w+ – ja ^ – lauseketta koodissamme. Me kattaa toiminnon re.findall () Pythonissa, myöhemmin tässä opetusohjelmassa, mutta jonkin aikaa keskitymme vain \W+ ja \^ ilmaisuun.
esimerkiksi merkkijonollemme ”guru99, koulutus on hauskaa”, jos suoritamme koodin w+: lla ja^, se antaa tulosteen ”guru99”.
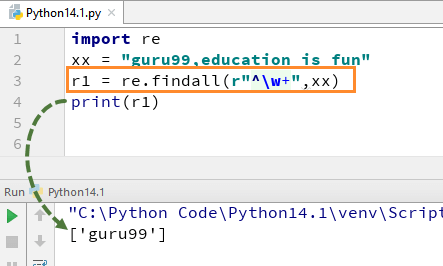
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print(r1)
muista, että jos poistat + – merkin w+: sta, tuloste muuttuu, ja se antaa vain ensimmäisen kirjaimen ensimmäisen merkin eli
esimerkin \s lausekkeesta re.jakofunktio
- ”s”: tätä lauseketta käytetään luomaan välilyönti merkkijonoon
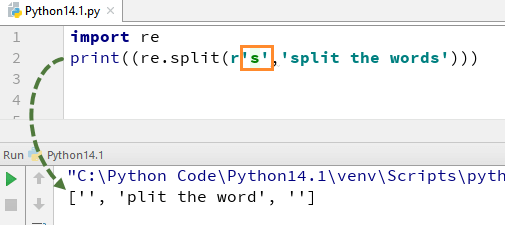
ymmärtääksemme, miten tämä RegEx Pythonissa toimii, aloitamme yksinkertaisella Pythonin RegEx-esimerkillä jaetusta funktiosta. Esimerkissä olemme jakaneet jokaisen sanan käyttäen ” re.split ” funktio ja samalla olemme käyttäneet lauseke \s, joka mahdollistaa jäsentää jokaisen sanan merkkijono erikseen.

kun suoritat tämän koodin, se antaa tulosteen .
nyt katsotaan, mitä tapahtuu, jos poistetaan ”\” S: stä. tulosteessa ei ole ”s” – aakkostoa, tämä johtuu siitä, että olemme poistaneet ” \ ”merkkijonosta, ja se arvioi ”S”: n säännöllisenä merkkinä ja jakaa näin sanat sinne, missä se löytää ” S ” merkkijonosta.
samoin on olemassa sarja muita Pythonin säännöllisiä lausekkeita, joita voit käyttää Pythonissa eri tavoin, kuten \d,\D,$,\., \b jne.
tässä on täydellinen koodi
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print((re.split(r'\s','we are splitting the words')))print((re.split(r's','split the words')))
seuraavaksi käydään läpi, millaisia menetelmiä Pythonissa käytetään säännöllisen lausekkeen kanssa.
säännöllisen lausekkeen menetelmiä käyttäen
”re” – paketti tarjoaa useita menetelmiä kyselyiden suorittamiseen tulomerkkijonolla. Re: n metodit Pythonissa nähdään:
- re.ottelu ()
- re.haku ()
- re.findall ()
Huom: säännöllisten lausekkeiden perusteella Python tarjoaa kaksi erilaista alkeisoperaatiota. Ottelumenetelmä tarkistaa ottelun vain merkkijonon alussa, kun taas haku tarkistaa ottelun missä tahansa merkkijonossa.
re.ottelu ()
re.match () funktio re Pythonissa etsii säännöllisen lausekkeen kuvion ja palauttaa ensimmäisen esiintymän. Python RegEx Match method tarkistaa ottelun vain merkkijonon alussa. Joten, jos osuma löytyy ensimmäisellä rivillä, se palauttaa match objekti. Mutta jos vastaavuus löytyy joltain muulta riviltä, Python RegEx Match-toiminto palauttaa nollan.
tarkastellaan esimerkiksi seuraavaa Python re: n koodia.match () – funktio. Ilmaisut ” w+” ja ”\W ” vastaavat G-kirjaimella alkavia sanoja, ja sen jälkeen mitään, mitä ei aloiteta g-kirjaimella, ei tunnisteta. Voit tarkistaa ottelu kunkin elementin luettelossa tai merkkijono, suoritamme forloop tässä Python re.match () esimerkki.

re.haku (): Löytökuvio tekstissä
re.haku () – funktio etsii säännöllisen lausekekuvion ja palauttaa ensimmäisen esiintymän. Toisin kuin Python re.match (), Se tarkistaa kaikki rivit syöttömerkkijonon. Python re.haku () – funktio palauttaa vastaavuuskohteen, kun kuvio löytyy, ja ”null” jos kuviota ei löydy
käyttääksesi haku () – funktiota, sinun on tuotava ensin Python re-moduuli ja suoritettava sitten koodi. Python re.search () – funktio ottaa ”pattern” ja ”text” – komennon skannatakseen pääjonostamme
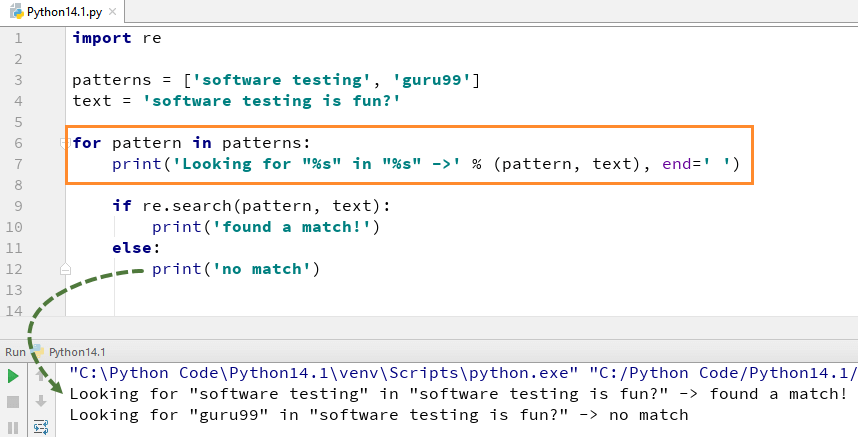
esimerkiksi tässä etsitään kahta kirjaimellista merkkijonoa ”Software testing” ”guru99”, tekstijonossa ”Software Testing is fun”. Varten ”ohjelmistojen testaus” löysimme ottelun joten se palauttaa tuotos Python re.haku () esimerkki ”löytyi match”, kun taas sanalle ”guru99” Emme löytäneet merkkijonoa, joten se palauttaa tuotoksen ”ei osumaa”.
re.findall ()
findall () – moduulia käytetään etsimään ”kaikkia” esiintymiä, jotka vastaavat tiettyä kaavaa. Sen sijaan haku () – moduuli palauttaa vain ensimmäisen annetun kuvion mukaisen esiintymän. findall () iteroi tiedoston kaikki rivit ja palauttaa kaikki ei-päällekkäiset kuvion osumat yhdessä vaiheessa.
esimerkiksi tässä meillä on lista sähköpostiosoitteista, ja haluamme, että kaikki sähköpostiosoitteet haetaan luettelosta, käytämme menetelmää re.findall () Python-kielellä. Se löytää kaikki sähköpostiosoitteet luettelosta.
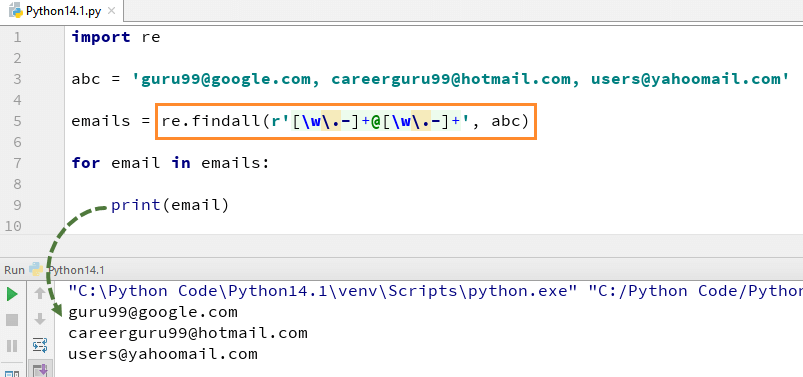
tässä on täydellinen koodi esimerkiksi re.findall ()
import relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print((z.groups())) patterns = text = 'software testing is fun?'for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!')else: print('no match')abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print(email)
Pythonin Liput
monissa Pythonin Regex-menetelmissä ja Regex-funktioissa käytetään valinnaista argumenttia nimeltä Flags. Nämä liput voivat muuttaa tietyn Python-Regex-kuvion merkitystä. Näiden ymmärtämiseksi näemme muutaman esimerkin näistä lipuista.
Various flags used in Python includes
| Syntax for Regex Flags | What does this flag do |
|---|---|
| Make begin/end consider each line | |
| It ignores case | |
| Make | |
| Make { \w,\W,\b,\B} follows Unicode rules | |
| Make {\w,\W,\b,\B} follow locale | |
| Allow comment in Regex |
Example of re.M-tai Moniriviliput
monirivisessä kuviomerkki vastaa merkkijonon ensimmäistä merkkiä ja jokaisen rivin alkua (seuraa heti jokaisen uuden rivin jälkeen). Vaikka lauseke pieni ” w ” käytetään merkitä tilaa merkkiä. Kun käytät koodia, ensimmäinen muuttuja ” k1 ”tulostaa vain sanan guru99 merkin ”g”, kun taas kun lisäät monirivisen lipun, se hakee ensimmäiset merkit kaikista merkkijonon elementeistä.
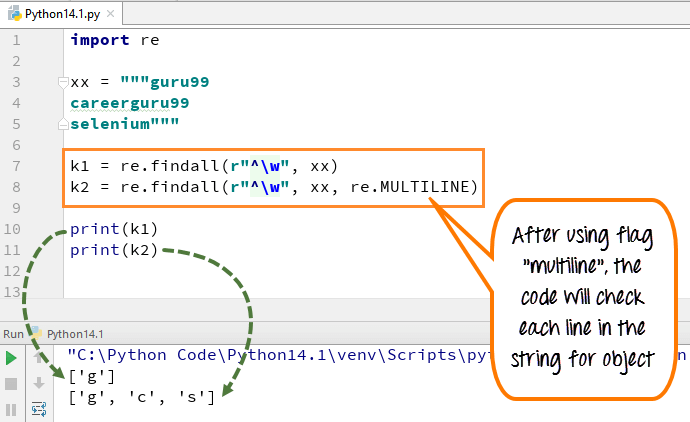
tässä on koodi
import rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print(k1)print(k2)
- julistimme muuttujan xx merkkijonolle ” guru99…. careerguru99….selenium ”
- Suorita koodi käyttämättä lippuja monirivinen, se antaa tulosteen vain ”g” riveistä
- Suorita koodi lipulla ”monirivinen”, kun tulostat ” k2 ”se antaa tulosteen ”g”, ” c ” ja ” s ”
- niin, erotuksen voimme nähdä monirivisten lisäämisen jälkeen ja ennen yllä olevassa esimerkissä.
samoin voi käyttää myös muita Python-lippuja, kuten re.U (Unicode), re.L (seuraa locale), re.X (salli kommentti), jne.
Python 2 Esimerkki
yllä olevat koodit ovat Python 3 Esimerkkejä, jos haluat suorittaa Python 2: ssa, harkitse seuraavaa koodia.
# Example of w+ and ^ Expressionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print r1# Example of \s expression in re.split functionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print (re.split(r'\s','we are splitting the words'))print (re.split(r's','split the words'))# Using re.findall for textimport relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print(z.groups()) patterns = text = 'software testing is fun?'for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!'else: print 'no match'abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print email# Example of re.M or Multiline Flagsimport rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print k1print k2
Yhteenveto
säännöllinen lauseke ohjelmointikielessä on erityinen tekstijono, jota käytetään hakukuvion kuvaamiseen. Se sisältää numeroita ja välimerkkejä ja kaikki erikoismerkit, kuten $#@!% jne. Lauseke voi sisältää kirjaimellisen
- tekstin sovittamisen
- toistoon
- haaroittamisen
- kuvion sommittelun jne.
Pythonissa säännöllinen lauseke merkitään siten, että Re (REs, regexes tai regex pattern) upotetaan Pythonin re-moduulin kautta.
- Pythonilla mukana oleva”re” – moduuli, jota käytetään pääasiassa merkkijonojen etsimiseen ja manipulointiin
- käytetään myös usein verkkosivujen ”kaavintaan” (poimia suuri määrä dataa verkkosivuilta)
- säännöllisen lausekkeen menetelmiin kuuluu re.ottelu (), re.search ()& re.findall ()
- muita Pythonin RegEx-korvaavia menetelmiä ovat sub() ja subn (), joita käytetään korvaamaan vastaavat merkkijonot re
- Pythonin lipuissa monet Pythonin Regex-menetelmät ja Regex-funktiot ottavat valinnaisen parametrin nimeltä Flags
- tämä lippu voi muuttaa annetun Regex-kuvion merkitystä
- useat Regex-menetelmissä käytetyt Python-liput ovat re.M, re.Minä, re.S, jne.