kaikki tietokannan käyttäjät tietävät säännöllisistä aggregaattifunktioista, jotka toimivat kokonaisessa taulukossa ja joita käytetään ryhmä lausekkeittain. Mutta hyvin harva käyttää SQL: ssä Ikkunafunktioita. Nämä toimivat riveillä ja palauttavat kullekin riville yhden aggregoidun arvon.
Ikkunafunktioiden käytön tärkein etu tavallisiin aggregaattifunktioihin verrattuna on: Ikkunafunktiot eivät aiheuta rivien ryhmittelyä yhdeksi lähtöriviksi, rivit säilyttävät erilliset identiteettinsä ja kullekin riville lisätään aggregoitu arvo.
Katsotaanpa, miten Ikkunafunktiot toimivat ja katsotaan sitten muutamia esimerkkejä sen käyttämisestä käytännössä varmistaaksemme, että asiat ovat selkeitä, ja myös miten SQL ja Lähtö vertautuvat siihen, että SUM() funktioille.
kuten aina, varmista, että olet täysin varmuuskopioitu, varsinkin jos olet kokeilemassa uusia asioita oman tietokannan kanssa.
Johdatus Ikkunafunktioihin
Ikkunafunktiot toimivat riveillä ja palauttavat kullekin riville yhden aggregoidun arvon. Termiikkuna kuvaa tietokannan rivijoukkoa, jolla funktio toimii.
määrittelemme ikkunan (rivijoukon, jolla funktiot toimivat) käyttämällä yli () – lauseketta. Keskustelemme lisää OVER () – lausekkeesta alla olevassa artikkelissa.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Kun lisäät kaikki se laskee kaikki arvot mukaan lukien päällekkäisiä. Erillisyyttä ei tueta ikkunafunktioissa
lauseke
kohdesarakkeessa tai lausekkeessa, jolla funktiot toimivat. Toisin sanoen sen sarakkeen nimi, jolle tarvitsemme yhteenlasketun arvon. Esimerkiksi sarake, joka sisältää tilauksen määrän, jotta voimme nähdä vastaanotettujen tilausten kokonaismäärän.
OVER
määrittää ikkunan lausekkeet yhteenlasketuille funktioille.
PARTITION BY partition_list
määrittelee ikkunan (rivien joukon, jolla ikkunafunktio toimii) ikkunafunktioille. Meidän täytyy tarjota kenttä tai luettelo kentät osio jälkeen osio lauseke. Useita kenttiä on erotettava pilkulla tavalliseen tapaan. Jos jakoa ei ole määritetty, ryhmittely tehdään koko taulukossa ja arvot aggregoidaan vastaavasti.
ORDER BY order_list
lajittelee rivit kunkin osion sisällä. Jos Order BY-tilausta ei ole määritelty, ORDER BY käyttää koko taulukkoa.
esimerkkejä
luodaan taulukko ja lisätään nuken tietueita lisäkyselyiden kirjoittamiseksi. Juokse koodin alapuolella.
Aggregaattiikkunafunktiot
SUM ()
me kaikki tunnemme SUM () – aggregaattifunktion. Se tekee summa tietyn kentän tietyn ryhmän (kuten kaupunki, valtio, maa jne.) tai koko taulukon osalta, jos ryhmää ei ole määritelty. Näemme, mikä on tuotos säännöllisen summan () yhteenlasketun funktion ja ikkunan summan () yhteenlasketun funktion.
Seuraavassa on esimerkki säännöllisestä summa () – aggregaattifunktiosta. Se summaa kunkin kaupungin tilaussumman.
voit nähdä tulosjoukosta, että säännöllinen aggregaattifunktio ryhmittelee useita rivejä yhdeksi lähtöriviksi, jolloin yksittäiset rivit menettävät identiteettinsä.
|
1
2
3
4
|
select City, Sum(order_amount) total_order_amount
from . Ryhmittely kaupungeittain
|

näin ei tapahdu ikkunoiden aggregaattifunktioilla. Rivit säilyttävät identiteettinsä ja osoittavat myös kunkin rivin yhteenlasketun arvon. Alla olevassa esimerkissä kysely tekee saman asian, eli se kokoaa tiedot kunkin kaupungin ja näyttää summa yhteensä tilauksen määrä kunkin niistä. Kysely kuitenkin lisää nyt toisen sarakkeen tilauksen kokonaismäärälle niin, että jokainen rivi säilyttää identiteettinsä. Sarake grand_total on uusi sarake alla olevassa esimerkissä.
AVG ()
AVG tai Average toimii täsmälleen samalla tavalla Ikkunafunktion kanssa.
seuraava kysely antaa sinulle keskimääräisen tilausmäärän jokaiselle kaupungille ja jokaiselle kuukaudelle (tosin yksinkertaisuuden vuoksi olemme käyttäneet tietoja vain yhden kuukauden aikana).
määrittelemme useamman kuin yhden keskiarvon määrittelemällä osioluetteloon useita kenttiä.
on myös syytä huomata, että listoissa voi käyttää lausekkeita, kuten kuukausi(order_date), kuten alla olevassa kyselyssä on esitetty. Voit tehdä näistä ilmaisuista niin monimutkaisia kuin haluat, kunhan syntaksi on oikea!
yllä olevasta kuvasta näkyy selvästi, että olemme saaneet Arlingtonin kaupunkiin keskimäärin 12 333 tilausta huhtikuulle 2017.
Average Order Amount = Total Order Amount / Total Orders
= (20,000 + 15,000 + 2,000) / 3
= 12,333
voit käyttää myös summan() & COUNT () – funktiota keskiarvon laskemiseen.
MIN ()
min () – aggregaattifunktio löytää tietyn ryhmän tai koko taulukon vähimmäisarvon, jos ryhmää ei ole määritelty.
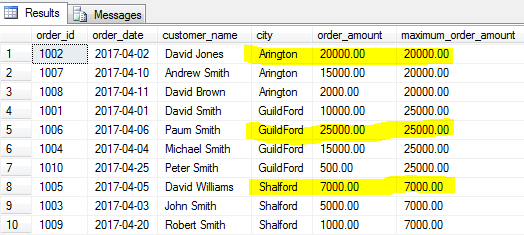
esimerkiksi etsimme jokaiselle kaupungille pienintä järjestystä (minimitilausta), jota käyttäisimme seuraavalla kyselyllä.
MAX () – funktio antaa vähimmäisarvon, samoin kuin min () – funktio tunnistaa määritellyn kentän suurimman arvon tietylle riviryhmälle tai koko taulukolle, jos ryhmää ei ole määritelty.
etsitään kullekin kaupungille suurin tilaus (suurin tilausmäärä).
kreivi () – funktio laskee tietueet / rivit.
huomaa, että erillistä ei tueta window COUNT () – funktiolla, kun taas sitä tuetaan säännölliselle COUNT () – funktiolle. Erillinen auttaa sinua löytämään eri arvot tietyn kentän.
esimerkiksi jos haluamme nähdä, kuinka moni asiakas on tehnyt tilauksen huhtikuussa 2017, emme voi suoraan laskea kaikkia asiakkaita. On mahdollista, että sama asiakas on tehnyt useita tilauksia saman kuukauden aikana.
COUNT(customer_name) antaa väärän tuloksen, koska se laskee kaksoiskappaleet. Kun taas COUNT (erillinen customer_name) antaa sinulle oikean tuloksen, koska se laskee kunkin ainutlaatuisen asiakkaan vain kerran.
voimassa säännölliselle COUNT () – funktiolle:
|
1
2
3
4
5 |
Select City,count(different customer_name) number_of_customers
from .
ryhmä kaupungeittain
|
virheellinen ikkunamäärä () – funktiolle:
yllä oleva kysely Ikkunafunktiolla antaa alla virheen.
nyt etsitään kullekin kaupungille saatu kokonaisjärjestys ikkunamäärä () – funktion avulla.
Ranking-ikkunan funktiot kokoavat tietyn kentän arvon, RANKING-funktiot luokittelevat tietyn kentän arvot ja luokittelevat ne niiden rankingin mukaan.
tavallisin RANKINGFUNKTIOIDEN käyttö on löytää top (N) tietueet tietyn arvon perusteella. Esimerkiksi Top 10 korkeimmin palkatut työntekijät, Top 10 sijoittuneet opiskelijat, Top 50 suurimmat tilaukset jne.
seuraavat ovat tuettuja RANKING-funktioita:
sijoitus(), DENSE_RANK(), ROW_NUMBER(), NTILE()
keskustellaan niistä yksi kerrallaan.
RANK ()
RANK () – funktiota käytetään antamaan jokaiselle tietueelle yksilöllinen arvo, joka perustuu tiettyyn arvoon, esimerkiksi palkkaan, järjestyssummaan jne.
Jos kahdella tietueella on sama arvo, RANK () – funktio antaa saman arvon molemmille tietueille ohittamalla seuraavan sijan. Tämä tarkoittaa – jos listalla 2 on kaksi identtistä arvoa, se antaa molemmille tietueille saman sijan 2 ja ohittaa sijan 3 ja antaa sijan 4 seuraavalle tietueelle.
pistetään jokainen järjestys paremmuusjärjestykseen niiden järjestyssumman mukaan.
|
1
2
3
4
5 |
select order_id,order_date,customer_name,City,
rank() over(Order by order_amount desc)
alkaen .
|
yllä olevasta kuvasta näkyy, että sama sijoitus (3) on annettu kahdelle identtiselle tietueelle (kummallakin järjestyssumma 15,000) ja se sitten ohittaa seuraavan sijan (4) ja antaa sijan 5 seuraavalle ennätykselle.
DENSE_RANK ()
dense_rank () – funktio on identtinen RANK () – funktion kanssa, paitsi että se ei ohita mitään rank-funktiota. Tämä tarkoittaa, että jos kaksi identtistä tietuetta löytyy, dense_rank() antaa saman arvon molemmille tietueille, mutta ei ohita sitten seuraavaa arvoa.
katsotaan, miten tämä toimii käytännössä.
kuten edellä selvästi näkyy, sama sijoitus annetaan kahdelle identtiselle tietueelle (joilla molemmilla on sama järjestysluku) ja seuraava numero annetaan seuraavalle tietueelle ohittamatta arvojärjestystä.
RIVI_NUMERO ()
nimi on itsestään selvä. Nämä funktiot antavat kullekin tietueelle yksilöllisen rivinumeron.
rivinumero nollataan jokaiselle osiolle, jos PARTITION BY on määritetty. Katsotaanpa, miten ROW_NUMBER () toimii ilman osio ja sitten osio.
ROW_ NUMBER() ilman jakoa
ROW_NUMBER (), jonka osion
huomaa, että olemme tehneet osion Kaupungista. Tämä tarkoittaa, että rivinumero nollataan jokaisessa kaupungissa ja käynnistyy uudelleen 1: llä. Rivien järjestys määräytyy kuitenkin järjestyssumman mukaan siten, että mille tahansa kaupungille suurin järjestyssumma on ensimmäinen rivi ja siten annettu rivi 1.
NTILE ()
NTILE() on erittäin hyödyllinen ikkunafunktio. Se auttaa sinua tunnistamaan, mihin prosenttipisteeseen (tai kvartiiliin tai muuhun alajakoon) tietty rivi kuuluu.
tämä tarkoittaa, että jos sinulla on 100 riviä ja haluat luoda 4 kvartiilia tietyn arvokentän perusteella, voit tehdä sen helposti ja nähdä, kuinka monta riviä kuhunkin kvartiiliin putoaa.
Katsotaanpa esimerkkiä. Alla olevassa kyselyssä olemme täsmentäneet, että haluamme luoda neljä kvartiilia tilausmäärän perusteella. Sitten haluamme nähdä, kuinka monta tilausta kuhunkin kvartiiliin lankeaa.
NTILE luo laattoja seuraavan kaavan perusteella:
rivien määrä jokaisessa laatassa = rivien määrä tulosjoukossa/määriteltyjen laattojen lukumäärä
tässä on esimerkkimme, meillä on yhteensä 10 riviä ja kyselyssä on määritelty 4 laattaa, joten rivien määrä kussakin laatassa on 2,5 (10/4). Koska rivien määrän tulisi olla kokonaislukua, ei desimaalia. SQL engine määrittää 3 riviä kaksi ensimmäistä ryhmää ja 2 riviä jäljellä kaksi ryhmää.
Arvoikkunafunktiot
LAG() ja LEAD ()
LEAD() ja LAG() ovat hyvin voimakkaita, mutta voivat olla monimutkaisia selittää.
koska tämä on johdanto artikkeli alla, tarkastelemme hyvin yksinkertainen esimerkki havainnollistaa, miten niitä käytetään.
LAG-funktion avulla voidaan käyttää edellisen rivin tietoja samassa tulosjoukossa ilman SQL-liittymiä. Näet alla esimerkki, käyttämällä LAG-toiminto löysimme edellisen tilauksen päivämäärä.
skripti edellisen tilauspäivän löytämiseksi LAG () – funktion avulla:
LYIJYFUNKTIO mahdollistaa pääsyn seuraavan rivin tietoihin samassa tulosjoukossa ilman SQL-liittymiä. Näet alla esimerkki, käyttäen johtaa toiminto löysimme seuraavan tilauksen päivämäärä.
skripti seuraavan tilauspäivän löytämiseksi LEAD () – funktion avulla:
FIRST_VALUE() ja LAST_VALUE ()
nämä funktiot auttavat tunnistamaan ensimmäisen ja viimeisen tietueen osiosta tai koko taulukosta, jos PARTITION BY-toimintoa ei ole määritelty.
etsitään kunkin kaupungin ensimmäinen ja viimeinen järjestys olemassa olevasta aineistostamme. Huomautus järjestys lausekkeella on pakollinen FIRST_VALUE() ja LAST_VALUE () funktioille
yllä olevasta kuvasta näkyy selvästi, että ensimmäinen tilaus vastaanotettu 2017-04-02 ja viimeinen tilaus vastaanotettu 2017-04-11 Arlington Citylle ja se toimii samoin muillekin kaupungeille.
hyödyllisiä linkkejä
- Backup Types & Strategies for SQL Databases
- TechNet Article on the OVER Clause
- MSDN Article On DENSE_RANK
muita hienoja artikkeleita Benistä
miten SQL Server valitsee umpikujaan joutuneen uhrin
ikkunafunktioiden käyttö
Katso kaikki Ben Richardsonin viestit
- Power BI: Waterfall Charts and Combined Visuals – 19. tammikuuta 2021
- teho bi: Ehdollinen muotoilu ja tiedon värit toiminnassa – tammikuu 14, 2021
- Power BI: Tietojen tuominen SQL serveriltä ja MySQL: ltä – tammikuu 12, 2021