BasicsEdit
ensin some sanasto:
| aktivointi | neuronin arvo. Binäärisillä neuroneilla tämä on yleensä 0 / 1 eli +1 / -1. |
| CAM | = content addressable memory. Muiston palauttaminen osittaisella kuviolla muistiosoitteen sijaan. |
| konvergenssi | = aktivaatiomallin stabilointi verkossa. SL: ssä konvergenssi tarkoittaa painojen vakiintumista & harhoja aktivaatioiden sijaan. |
| syrjivä | = tunnustamistehtäviin liittyvä. Kutsutaan myös analyysi (Pattern Theory), tai päättely. |
| energia | = makroskooppinen suure, joka kuvaa aktivaatiomallia verkossa. (katso alla) |
| yleistys | = käyttäytyminen tarkasti aiemmin havaitsemattomilla tuloilla |
| generatiivinen | = koneen kuviteltu ja takaisinkutsutehtävä. joskus kutsutaan synteesi (kuvio teoriassa), matkiminen, tai syvä väärennöksiä. |
| päättely | = ”run” – vaihe (toisin kuin harjoittelu). Päättelyn aikana verkko suorittaa tehtävän, johon se on koulutettu—joko tunnistaa kuvion (SL) tai luo sellaisen (UL). Yleensä päättely laskee energiafunktion gradientin. Toisin kuin SL, gradientin laskeutuminen tapahtuu harjoittelun aikana, ei päättelyä. |
| Konenäkö | = koneoppiminen kuvilla. |
| NLP | = luonnollisen kielen käsittely. Ihmisten kielten koneoppiminen. |
| kuvio | = verkkoaktivaatiot, joilla on jossain mielessä sisäinen järjestys, tai joita voidaan kuvata tiiviimmin aktivointien piirteillä. Esimerkiksi nollan pikselikuviolla, oli se sitten datana annettu tai verkon kuvittama, on ominaisuus, jota voidaan kuvata yhtenä silmukkana. Ominaisuudet koodataan piilotettuihin neuroneihin. |
| koulutus | = oppimisvaihe. Tässä Verkko säätää painojaan & ottaa oppia syötteistä. |
tehtävät

UL-menetelmät valmistavat yleensä verkoston generatiivisia tehtäviä varten tunnustamisen sijaan, mutta tehtävien ryhmittely valvottaviksi tai ei-valvottaviksi voi olla epämääräistä. Esimerkiksi käsialantunnistus alkoi 1980-luvulla nimellä SL. Sitten vuonna 2007, UL käytetään prime verkon SL jälkeenpäin. Tällä hetkellä SL on vakiinnuttanut asemansa parempana menetelmänä.
koulutus
oppimisvaiheessa valvomaton verkko yrittää matkia antamaansa dataa ja käyttää matkitun ulostulonsa virhettä korjatakseen itsensä (esim. sen painot & harhat). Tämä muistuttaa lasten matkivaa käyttäytymistä heidän oppiessaan kieltä. Joskus virhe ilmaistaan pienellä todennäköisyydellä, että virheellinen lähtö tapahtuu, tai se voidaan ilmaista epävakaana korkean energian tilana verkossa.
Energia
energiafunktio on verkon tilan makroskooppinen mitta. Tämä analogia fysiikan kanssa perustuu Ludwig Boltzmannin analyysiin kaasun ” makroskooppisesta energiasta hiukkasliikkeen mikroskooppisista todennäköisyyksistä p ∝ {\displaystyle \propto }

ee / kT, missä k on Boltzmannin vakio ja T on lämpötila. RBM-verkossa relaatio on P = e-E / Z, jossa p & e vaihtelee jokaisella mahdollisella aktivaatiokuviolla ja Z = ∑ A L L P a T E r n s {\displaystyle \sum _{AllPatterns}}

E-E(kuvio). Tarkemmin sanottuna P(a) = e-E (A) / Z, jossa a on kaikkien neuronien (näkyvien ja piilotettujen) aktivaatiokuvio. Siksi varhaiset hermoverkot kantavat nimeä Boltzmannin kone. Paul Smolensky kutsuu-E: tä harmoniaksi. Verkko pyrkii matalaan energiaan, joka on korkeaa harmoniaa.
Networks
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
 |
 restricted Boltzmann machine
|
 |

autoencoder
|
 variational autoencoder
|
|---|

Boltzmann ja Helmholtz tulivat ennen neuroverkkojen muotoiluja, mutta nämä verkot lainasivat niiden analyyseistä, joten nämä verkot kantavat nimeään. Hopfield osallistui kuitenkin suoraan UL: n toimintaan.
IntermediateEdit
tässä jakaumat p(x) ja q(x) lyhennetään p: ksi ja q: ksi.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Sitä käytetään enimmäkseen SL, mutta ansaitsee maininnan täällä. |
| 1982 | Ising variant Hopfield net kuvasi John Hopfieldin kamerat ja luokittelijat. |
| 1983 | Ising-variantti Boltzmannin kone, jolla on Hintonin kuvaamia probabilistisia neuroneja & Sejnowski sheringtonin & Kirkpatrickin 1975 työ. |
| 1986 | Paul Smolensky julkaisee Harmoniateorian, joka on RBM, jossa on käytännössä sama Boltzmannin energiafunktio. Smolenski ei antanut harjoitteluohjelmaa. Hinton teki 2000-luvun puolivälissä |
| 1995 | Schmidthuber esitteli kielten lstm-neuronin. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| todennäköisyys | |
| CDF | = kumulatiivinen jakaumafunktio. PDF-tiedoston integraali. Todennäköisyys päästä lähelle 3 on käyrän alle jäävä alue välillä 2,9-3,1. |
| contrastive divergence | = oppimistapa, jossa vähennetään energiaa harjoitusmalleihin ja nostetaan energiaa ei-toivottuihin harjoitusmalleihin harjoitusjoukon ulkopuolella. Tämä on hyvin erilainen kuin KL-ero, mutta jakaa saman sanamuodon. |
| odotusarvo | = e(x) = ∑ x {\displaystyle \sum _{x}}
 x * p(x). Tämä on keskiarvo eli keskiarvo. Jatkuvassa tulossa x korvataan yhteenlasku integraalilla. |
| piilevä muuttuja | = havaitsematon määrä, joka auttaa selittämään havaittuja tietoja. esimerkiksi flunssa infektio (huomaamatta) voi selittää, miksi henkilö aivastaa (havaittu). Todennäköisyysabilistisissa hermoverkoissa piilevät hermosolut toimivat latentteina muuttujina, joskaan niiden piilevää tulkintaa ei eksplisiittisesti tunneta. |
| = todennäköisyystiheysfunktio. Todennäköisyys, että satunnaismuuttuja saa tietyn arvon. Jatkuva pdf, p (3) = 1/2 voi silti tarkoittaa, että on lähes nolla mahdollisuutta saavuttaa tämä tarkka arvo 3. Järkeistämme tämän cdf: llä. | |
| stokastinen | = käyttäytyy hyvin kuvatun todennäköisyystiheyskaavan mukaisesti. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Se on suurin palautuva työ, jonka lämpöjärjestelmä voi tehdä vakiolämpötilassa ja-paineessa. vapaa energia G = lämpö-lämpötila * entropia |
| tiedot | = viestin informaatiomäärä x = -log p(x) |
| KLD | = suhteellinen entropia. Probabilistisissa verkoissa tämä on tulon & monistetun lähdön välisen virheen analogia. Kullback-Liebler-divergenssi (KLD) mittaa 1-jakauman entropiapoikkeamaa toisesta jakaumasta. KLD( p, q) = ∑ x {\displaystyle \sum _{x}}
p * log (p / q ). Tyypillisesti p heijastaa syöttötietoja, q kuvaa verkon tulkintaa siitä ja KLD heijastaa näiden kahden eroa. |
verkkojen Vertailu
| Boltzmann | RBM | Helmholtz | autoencoder | Vae | käyttö & notables | cam, traveling salesman problem | cam. Yhteyksien vapaus tekee tästä verkosta vaikeasti analysoitavan. | hahmontunnistus (MNIST, puheentunnistus) | mielikuvitus, matkiminen | kieli: Luova kirjoittaminen, kääntäminen. Visio: tarkentavat sumeat kuvat | tuottavat realistista tietoa | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| neuroni | deterministinen binääritila. Aktivaatio = { 0 (tai -1) jos x on negatiivinen, 1 muuten } | stokastinen binäärinen Hopfieldin neuroni | stokastinen binäärinen neuroni. Laajennettu 2000-luvun puolivälissä reaaliarvoon | binäärinen, sigmoid | kieli: LSTM. visio: paikalliset vastaanottokentät. yleensä reaalinen arvo relu aktivointi. | ||||||||
| liitokset | 1-kerros symmetrisillä painoilla. Ei itsesuhteita. | 2-kerroksinen. 1-piilossa & 1-näkyvissä. symmetriset painot. | 2-kerroksinen. symmetriset painot. ei sivuttaisliitoksia kerroksen sisällä. | 3-kerrokset: epäsymmetriset painot. 2 verkot yhdistetään 1. | 3-kerroksinen. Tulo pidetään kerros, vaikka se ei ole sidottu painot. toistuvat kerrokset NLP: tä varten. syöte kohti convolutions for vision. tulo & ulostulolla on samat hermosolumäärät. | 3-layers: input, encoder, distribution sampler dekooderi. näytteenottajaa ei pidetä kerroksena (e) | |||||||
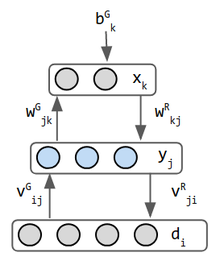
| päättely & energia | energia annetaan Gibbsin todennäköisyysmittarilla : E = − 1 2 ∑ i , j w i j s i s j + ∑ i θ I S i {\displaystyle E=-{\frac {1}{2}}\sum _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\sum _{i}{\theta _{i}}{s_{i}}}
 |
← sama | minimoi KL divergenssi | päättely on vain syöte eteenpäin. aiemmat UL-verkot kulkivat eteen – ja taaksepäin | minimum error = reconstruction error – KLD | ||||||||
| training | Δwij = si*sj, +1/-1 neuronille | Δwij = e*(pij-p ’ IIJ). Tämä on johdettu KLD: n minimoinnista. e = Oppimisnopeus, P’ = ennustettu ja p = todellinen jakauma. | contrastive divergence w/ Gibbs Sampling | wake-sleep 2 phase training | back propagate the rekonstruktiovirhe | reparametrize hidden state for backprop | |||||||
| strength | muistuttaa fysikaalisia järjestelmiä, joten se perii niiden yhtälöt | < – – – sama. piilotetut hermosolut toimivat ulkoisen maailman sisäisinä esikuvina | nopeammin enemmän käytännön harjoitusohjelmaa kuin Boltzmannin koneet | lievästi anatomiset. analyyttinen w/ informaatioteoria & tilastollinen mekaniikka | heikkous | hopfield | vaikeasti koulutettava lateraaliyhteyksien vuoksi | RBM | Helmholtz |
erityisverkot
tässä korostetaan kunkin verkon joitakin ominaisuuksia. Ferromagnetismi innoitti Hopfield-verkkoja, Boltzmannin koneita ja RBMs-järjestelmiä. Hermosolu vastaa rautakomponenttia, jossa on binäärisiä magneettisia momentteja ylös ja alas, ja hermoyhteydet vastaavat domeenin vaikutusta toisiinsa. Symmetriset yhteydet mahdollistavat globaalin energianmuodostuksen. Päättelyn aikana verkko päivittää jokaisen tilan käyttäen standardia aktivointivaihetoimintoa. Symmetriset painot takaavat lähentymisen vakaaseen aktivaatiomalliin.
Hopfieldin verkkoja käytetään kameroina, ja ne asettuvat taatusti jonkinlaiseen kaavaan. Ilman symmetrisiä painoja verkkoa on hyvin vaikea analysoida. Oikealla energiafunktiolla verkko lähentyy.
Boltzmannin koneet ovat stokastisia Hopfield-verkkoja. Niiden tilan arvo on otettu tästä pdf: stä seuraavasti: oletetaan, että binäärinen neuroni ampuu Bernoullin todennäköisyydellä p(1) = 1/3 ja on P(0) = 2/3. Yksi näyte siitä ottamalla tasaisesti jakautunut satunnaisluku y ja liittämällä se käänteiseen kumulatiiviseen jakaumafunktioon, joka tässä tapauksessa on porrasfunktio, jonka arvo on 2/3. Käänteisfunktio = { 0 if x <= 2/3, 1 if x > 2/3 }
Helmholtzin koneet ovat variationaalisten Automaattiantureiden varhaisia innoittajia. Se on 2 verkot yhdistettynä yhden eteenpäin painot toimii tunnustamista ja taaksepäin painot toteuttaa mielikuvitusta. Se on ehkä ensimmäinen verkosto, joka tekee molempia. Helmholtz ei toimi koneoppimisen, mutta hän innoitti näkemyksen ”tilastollinen inference moottori, jonka tehtävänä on päätellä todennäköisiä syitä sensory input” (3). stokastinen binäärinen neuroni tuottaa todennäköisyyden, että sen tila on 0 tai 1. Datasyöttöä ei yleensä pidetä kerroksena, mutta Helmholtzin konesukupolvitilassa datakerroksella, joka saa syötteen keskikerrokselta, on tähän tarkoitukseen erilliset painot, joten sitä pidetään kerroksena. Siksi tämä verkko on 3 kerrosta.
Variational Autoencoder (VAE) on saanut vaikutteita Helmholtzin koneista ja yhdistää todennäköisyysverkon neuroverkkoihin. Autokooderi on 3-kerroksinen CAM-verkko, jossa keskimmäisen kerroksen on tarkoitus olla jokin sisäinen esitys syöttökuvioista. Painojen nimenä on phi & theta eikä W ja V kuten helmholtzissa—kosmeettinen ero. Kooderin neuroverkko on todennäköisyysjakauma qφ(z|x) ja dekooderin verkko on pθ (x|z). Nämä 2 verkot täällä voidaan täysin kytketty, tai käyttää toista NN järjestelmä.
Hebbian Learning, ART, som
klassinen esimerkki valvomattomasta oppimisesta neuroverkkojen tutkimuksessa on Donald Hebbin periaate, eli hermosolut, jotka ampuvat yhteen lanka yhteen. Hebbiläisessä oppimisessa yhteys vahvistuu virheestä riippumatta, mutta on yksinomaan kahden neuronin välisten toimintapotentiaalien yhteensattuman funktio. Vastaava synaptisia painoja muokkaava versio ottaa huomioon toimintapotentiaalien välisen ajan (piikki-ajoituksesta riippuva plastisuus tai STDP). Hebbiläisen oppimisen on oletettu taustalla olevan erilaisia kognitiivisia toimintoja, kuten hahmontunnistus ja kokemuksellinen oppiminen.
neuroverkkomalleista itseorganisoituvaa karttaa (Som) ja adaptiivista resonanssiteoriaa (ART) käytetään yleisesti valvomattomissa oppimisalgoritmeissa. SOM on topografinen organisaatio, jossa lähellä olevat paikat kartalla edustavat syötteitä, joilla on samanlaiset ominaisuudet. ART-mallin avulla klusterien määrä voi vaihdella ongelmakokojen mukaan ja käyttäjä voi hallita samojen klustereiden jäsenten samankaltaisuuden astetta käyttäjän määrittelemän vakion avulla, jota kutsutaan vigilanssiparametriksi. TAIDEVERKOSTOJA käytetään moniin hahmontunnistustehtäviin, kuten automaattiseen maalintunnistukseen ja seismiseen signaalinkäsittelyyn.