BasicsEdit
Tout d’abord, un peu de vocabulaire:
| activation | = valeur d’état de la neurone. Pour les neurones binaires, c’est généralement 0 / 1, ou +1/-1. |
| CAM | =mémoire adressable de contenu. Rappeler une mémoire par un motif partiel au lieu d’une adresse mémoire. |
| convergence | = la stabilisation d’un modèle d’activation sur un réseau. En SL, la convergence signifie la stabilisation des biais & plutôt que des activations. |
| discriminatoire | = relative aux tâches de reconnaissance. Aussi appelé analyse (en Théorie des modèles), ou inférence. |
| énergie | = quantité macroscopique décrivant le schéma d’activation dans un réseau. (voir ci-dessous) |
| généralisation | = se comporter avec précision sur des entrées précédemment non rencontrées |
| générative | =Tâche imaginée et de rappel par la machine. parfois appelé synthèse (en théorie des modèles), mimétisme ou faux profonds. |
| inférence | = la phase « run » (par opposition à la formation). Pendant l’inférence, le réseau effectue la tâche à laquelle il est formé — soit reconnaître un motif (SL), soit en créer un (UL). Habituellement, l’inférence descend le gradient d’une fonction d’énergie. Contrairement à SL, la descente de gradient se produit pendant l’entraînement, PAS l’inférence. |
| vision industrielle | =apprentissage automatique sur images. |
| PNL | =Traitement du langage naturel. Apprentissage automatique des langues humaines. |
| pattern | = activations réseau qui ont un ordre interne dans un certain sens, ou qui peuvent être décrites de manière plus compacte par des fonctionnalités dans les activations. Par exemple, le motif de pixels d’un zéro, qu’il soit donné sous forme de données ou imaginé par le réseau, a une caractéristique qui peut être décrite comme une boucle unique. Les caractéristiques sont codées dans les neurones cachés. |
| formation | = la phase d’apprentissage. Ici, le réseau ajuste ses biais de poids & pour apprendre des entrées. |
Tâches

Les méthodes UL préparent généralement un réseau pour des tâches génératives plutôt que pour la reconnaissance, mais le regroupement des tâches supervisées ou non peut être flou. Par exemple, la reconnaissance de l’écriture manuscrite a commencé dans les années 1980 sous le nom de SL. Puis en 2007, UL est utilisé pour amorcer le réseau pour SL par la suite. Actuellement, SL a retrouvé sa position de meilleure méthode.
Formation
Pendant la phase d’apprentissage, un réseau non supervisé essaie d’imiter les données qu’il donne et utilise l’erreur dans sa sortie mimée pour se corriger (par exemple. ses poids & biais). Cela ressemble au comportement mimétique des enfants lorsqu’ils apprennent une langue. Parfois, l’erreur est exprimée comme une faible probabilité que la sortie erronée se produise, ou elle peut être exprimée comme un état instable à haute énergie dans le réseau.
Énergie
Une fonction énergétique est une mesure macroscopique de l’état d’un réseau. Cette analogie avec la physique est inspirée par l’analyse par Ludwig Boltzmann de l’énergie macroscopique d’un gaz à partir des probabilités microscopiques du mouvement des particules p ∝{\displaystyle\propto}

eE/kT, où k est la constante de Boltzmann et T la température. Dans le réseau RBM, la relation est p = e-e/Z, où p & E varie sur tous les modèles d’activation possibles et Z = A A l l p a t t e r n s {\displaystyle\sum_{AllPatterns}}

e – E (motif). Pour être plus précis, p(a) = e-E(a)/Z, où a est un motif d’activation de tous les neurones (visibles et cachés). Par conséquent, les premiers réseaux de neurones portent le nom de machine de Boltzmann. Paul Smolensky appelle -E l’Harmonie. Un réseau recherche une énergie faible qui est une harmonie élevée.
Réseaux
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencodeur | VAE |
|---|---|---|---|---|---|
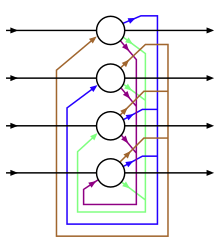
|
 |
 restricted Boltzmann machine
|
 |
 autoencodeur
|

autoencodeur variationnel
|
Boltzmann et Helmholtz sont venus avant les formulations des réseaux de neurones, mais ces réseaux ont emprunté à leurs analyses, donc ces réseaux portent leurs noms. Hopfield, cependant, a directement contribué à UL.
IntermediateEdit
Ici, les distributions p(x) et q(x) seront abrégées en p et q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Il est principalement utilisé en SL, mais mérite une mention ici. |
| 1982 | Variante d’ising Hopfield net décrite comme CAMs et classificateurs par John Hopfield. |
| 1983 | Variante d’Ising machine de Boltzmann avec des neurones probabilistes décrite par Hinton &Sejnowski à la suite des travaux de Sherington &de Kirkpatrick en 1975. |
| 1986 | Paul Smolensky publie la Théorie de l’harmonie, qui est un RBM avec pratiquement la même fonction énergétique de Boltzmann. Smolensky n’a pas donné de programme de formation pratique. Hinton l’a fait au milieu des années 2000 |
| 1995 | Schmidthuber introduit le neurone LSTM pour les langages. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| Probabilité | |
| cdf | = fonction de distribution cumulative. l’intégrale du pdf. La probabilité de se rapprocher de 3 est l’aire sous la courbe comprise entre 2,9 et 3,1. |
| divergence contrastive | =une méthode d’apprentissage où l’on abaisse l’énergie sur les schémas d’entraînement et augmente l’énergie sur les schémas indésirables en dehors de l’ensemble d’entraînement. Ceci est très différent de la divergence KL, mais partage une formulation similaire. |
| valeur attendue | =E(x)= ∑x {\displaystyle\sum_{x}}

x*p(x). Il s’agit de la valeur moyenne ou de la valeur moyenne. Pour l’entrée continue x, remplacez la sommation par une intégrale. |
| variable latente | = une quantité non observée qui aide à expliquer les données observées. par exemple, une infection grippale (non observée) peut expliquer pourquoi une personne éternue (observée). Dans les réseaux de neurones probabilistes, les neurones cachés agissent comme des variables latentes, bien que leur interprétation latente ne soit pas explicitement connue. |
| = fonction de densité de probabilité. La probabilité qu’une variable aléatoire prenne une certaine valeur. Pour un pdf continu, p(3) = 1/2 peut encore signifier qu’il y a presque zéro chance d’atteindre cette valeur exacte de 3. Nous rationalisons cela avec le cdf. | |
| stochastique | = se comporte selon une formule de densité de probabilité bien décrite. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. C’est le travail réversible maximal qui peut être effectué par un système de chaleur à température et pression constantes. énergie libre G = chaleur-température * entropie |
| information | = la quantité d’informations d’un message x=-log p(x) |
| KLD | = entropie relative. Pour les réseaux probabilistes, il s’agit de l’analogue de l’erreur entre l’entrée & sortie imitée. La divergence de Kullback-Liebler (KLD) mesure l’écart d’entropie de 1 distribution par rapport à une autre distribution. KLD(p, q) = xx {\displaystyle\sum_{x}}
p*log(p/q). Typiquement, p reflète les données d’entrée, q reflète l’interprétation du réseau et KLD reflète la différence entre les deux. |
Comparaison des réseaux
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE | ||
|---|---|---|---|---|---|---|---|
| utilisation¬ables | CAM, problème de vendeur itinérant | CAM. La liberté de connexion rend ce réseau difficile à analyser. | reconnaissance de formes (MNIST, reconnaissance vocale) | imagination, mimétisme | langue: écriture créative, traduction. Vision: amélioration des images floues | générer des données réalistes | |
| neurone | état binaire déterministe. Activation = {0 (ou -1) si x est négatif, 1 sinon} | binaire stochastique neurone de Hopfield | binaire stochastique. Étendu à la valeur réelle au milieu des années 2000 | binaire, sigmoïde | langage: LSTM. vision : champs réceptifs locaux. activation de relu valorisée généralement réelle. | ||
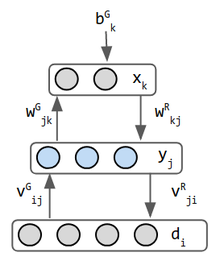
| connexions | 1 couche avec des poids symétriques. Pas d’auto-connexions. | 2 couches. 1 – caché &1 – visible. poids symétriques. | 2 couches. poids symétriques. pas de connexions latérales dans une couche. | 3 couches : poids asymétriques. 2 réseaux combinés en 1. | 3 couches. L’entrée est considérée comme une couche même si elle n’a pas de poids entrant. couches récurrentes pour la PNL. circonvolutions pour la vision. l’entrée & la sortie a le même nombre de neurones. | 3 couches: entrée, encodeur, décodeur d’échantillonneur de distribution. l’échantillonneur n’est pas considéré comme une couche (e) | |
| inférence &énergie | l’énergie est donnée par la mesure de probabilité de Gibbs : E = − 1 2 i i, j w i s i s j + θ i θ i s i {\displaystyle E = -{\frac {1} {2}} \sum _{i, j} {w_{i}} {s_{j}}} +\sum _{i}{\theta_{i}} {s_{i}}}

|
← même | ← même | minimiser la divergence KL | l’inférence n’est qu’un feed-forward. les réseaux UL précédents ont couru en avant ET en arrière | minimiser l’erreur= erreur de reconstruction – KLD | |
| formation | Δwij = si *sj, pour +1/-1 neurone | Δwij=e *(pij-p’ij). Ceci est dérivé de la minimisation de KLD. e = taux d’apprentissage, p’ = distribution prévue et p = distribution réelle. | divergence contrastive avec échantillonnage de Gibbs | entraînement en phase de réveil-sommeil 2 | propagation arrière de l’erreur de reconstruction | réparez l’état caché pour backprop | |
| force | ressemble aux systèmes physiques, elle hérite donc de leurs équations | < — même. les neurones cachés agissent comme une représentation interne du monde extérieur | système d’entraînement plus rapide et plus pratique que les machines de Boltzmann | légèrement anatomiques. analyse avec théorie de l’information &mécanique statistique | |||
| faiblesse | hopfield | difficile à entraîner en raison de connexions latérales | RBM | Helmholtz |
Réseaux spécifiques
Ici, nous mettons en évidence certaines caractéristiques de chaque réseau. Le ferromagnétisme a inspiré les réseaux Hopfield, les machines Boltzmann et les RBM. Un neurone correspond à un domaine de fer avec des moments magnétiques binaires de haut en bas, et les connexions neuronales correspondent à l’influence du domaine les unes sur les autres. Les connexions symétriques permettent une formulation énergétique globale. Pendant l’inférence, le réseau met à jour chaque état à l’aide de la fonction d’étape d’activation standard. Les poids symétriques garantissent la convergence vers un modèle d’activation stable.
Les réseaux Hopfield sont utilisés comme CAMES et sont garantis pour s’installer dans un certain modèle. Sans poids symétriques, le réseau est très difficile à analyser. Avec la bonne fonction énergétique, un réseau convergera.
Les machines Boltzmann sont des filets de Hopfield stochastiques. Leur valeur d’état est échantillonnée à partir de ce pdf comme suit: supposons qu’un neurone binaire se déclenche avec la probabilité de Bernoulli p(1) = 1/3 et repose avec p(0) = 2/3. On en échantillonne en prenant un nombre aléatoire y UNIFORMÉMENT distribué, et en le branchant dans la fonction de distribution cumulée inversée, qui est dans ce cas la fonction pas à pas seuillée à 2/3. La fonction inverse = {0 if x <=2/3, 1 if x >2/3}
Les machines de Helmholtz sont les premières inspirations des codeurs automatiques variationnels. Ses 2 réseaux combinés en un seul – les poids en avant opèrent la reconnaissance et les poids en arrière implémentent l’imagination. C’est peut-être le premier réseau à faire les deux. Helmholtz n’a pas travaillé dans l’apprentissage automatique, mais il a inspiré la vision du « moteur d’inférence statistique dont la fonction est d’inférer les causes probables de l’entrée sensorielle » (3). le neurone binaire stochastique émet une probabilité que son état soit 0 ou 1. L’entrée de données n’est normalement pas considérée comme une couche, mais dans le mode de génération de machine de Helmholtz, la couche de données reçoit l’entrée de la couche intermédiaire a des poids distincts à cet effet, elle est donc considérée comme une couche. Ce réseau a donc 3 couches.
L’Autoencodeur variationnel (VAE) est inspiré des machines de Helmholtz et combine un réseau de probabilité avec des réseaux de neurones. Un Autoencodeur est un réseau de CAM à 3 couches, où la couche intermédiaire est censée être une représentation interne des motifs d’entrée. Les poids sont nommés phi &thêta plutôt que W et V comme dans Helmholtz — une différence cosmétique. Le réseau neuronal codeur est une distribution de probabilité qφ (z/x) et le réseau décodeur est pθ (x|z). Ces 2 réseaux peuvent ici être entièrement connectés, ou utiliser un autre schéma NN.
Apprentissage Hebbien, ART, SOM
L’exemple classique d’apprentissage non supervisé dans l’étude des réseaux de neurones est le principe de Donald Hebb, c’est-à-dire que les neurones qui tirent ensemble filent ensemble. Dans l’apprentissage Hebbien, la connexion est renforcée indépendamment d’une erreur, mais est exclusivement fonction de la coïncidence entre les potentiels d’action entre les deux neurones. Une version similaire qui modifie les poids synaptiques prend en compte le temps entre les potentiels d’action (plasticité dépendante du temps de pointe ou STDP). L’apprentissage Hebbien a été supposé sous-tendre une gamme de fonctions cognitives, telles que la reconnaissance de formes et l’apprentissage expérientiel.
Parmi les modèles de réseaux neuronaux, la carte d’auto-organisation (SOM) et la théorie de la résonance adaptative (ART) sont couramment utilisées dans les algorithmes d’apprentissage non supervisés. Le SOM est une organisation topographique dans laquelle les emplacements voisins de la carte représentent des entrées avec des propriétés similaires. Le modèle ART permet au nombre de clusters de varier en fonction de la taille du problème et permet à l’utilisateur de contrôler le degré de similitude entre les membres des mêmes clusters au moyen d’une constante définie par l’utilisateur appelée paramètre de vigilance. Les réseaux ART sont utilisés pour de nombreuses tâches de reconnaissance de formes, telles que la reconnaissance automatique de cibles et le traitement des signaux sismiques.