
« Il existe trois types de mensonges – mensonges, merde mensonges et statistiques. »- Benjamin Disraeli
Les analyses statistiques ont toujours été un pilier des industries de haute technologie et de pointe, et elles sont aujourd’hui plus importantes que jamais. Avec l’essor des technologies de pointe et des opérations mondialisées, les analyses statistiques donnent aux entreprises un aperçu de la résolution des incertitudes extrêmes du marché. Les études favorisent la prise de décisions éclairées, les jugements solides et les actions menées en fonction du poids des preuves, et non des hypothèses.
Les entreprises étant souvent obligées de suivre une feuille de route du marché difficile à interpréter, les méthodes statistiques peuvent aider à la planification nécessaire pour naviguer dans un paysage rempli de nids de poule, d’embûches et de concurrence hostile. Les études statistiques peuvent également aider à la commercialisation de biens ou de services et à comprendre les facteurs de valeur uniques de chaque marché cible. À l’ère numérique, ces capacités ne sont améliorées et exploitées que par la mise en œuvre de technologies de pointe et de logiciels de business intelligence. Si tout cela est vrai, quel est le problème des statistiques?
En fait, il n’y a pas de problème en soi – mais il peut y en avoir. Les statistiques sont tristement célèbres pour leur capacité et leur potentiel à exister en tant que données trompeuses et mauvaises.
Qu’Est-Ce Qu’Une Statistique Trompeuse ?
Les statistiques trompeuses sont simplement l’utilisation abusive – intentionnelle ou non – d’une donnée numérique. Les résultats fournissent une information trompeuse au destinataire, qui croit alors que quelque chose ne va pas s’il ne remarque pas l’erreur ou s’il n’a pas l’image complète des données.
Compte tenu de l’importance des données dans le monde numérique en évolution rapide d’aujourd’hui, il est important de se familiariser avec les bases des statistiques trompeuses et de la surveillance. Dans le cadre d’un exercice de diligence raisonnable, nous examinerons certaines des formes les plus courantes d’utilisation abusive des statistiques, ainsi que divers exemples alarmants (et malheureusement courants) de statistiques trompeuses de la vie publique.
Les statistiques sont-Elles fiables ?
73,6% des statistiques sont fausses. Vrai? Non, bien sûr, c’est un numéro inventé (même si une telle étude serait intéressante à connaître – mais encore une fois, pourrait avoir tous les défauts qu’elle essaie en même temps de souligner). La fiabilité statistique est cruciale pour assurer la précision et la validité de l’analyse. Pour s’assurer que la fiabilité est élevée, il existe différentes techniques à effectuer – en premier lieu les tests de contrôle, qui devraient avoir des résultats similaires lors de la reproduction d’une expérience dans des conditions similaires. Ces mesures de contrôle sont essentielles et devraient faire partie de toute expérience ou enquête – malheureusement, ce n’est pas toujours le cas.
Bien que les nombres ne mentent pas, ils peuvent en fait être utilisés pour induire en erreur avec des demi-vérités. C’est ce qu’on appelle » l’utilisation abusive des statistiques. »On suppose souvent que l’utilisation abusive des statistiques est limitée aux individus ou aux entreprises qui cherchent à tirer profit de la distorsion de la vérité, qu’il s’agisse de l’économie, de l’éducation ou des médias.
Cependant, le fait de dire des demi-vérités par l’étude ne se limite pas aux amateurs de mathématiques. Une enquête menée en 2009 par le Dr Daniele Fanelli de l’Université d’Édimbourg a révélé que 33,7% des scientifiques interrogés admettaient des pratiques de recherche douteuses, notamment la modification des résultats pour améliorer les résultats, l’interprétation subjective des données, la rétention de détails analytiques et l’abandon des observations en raison de sentiments intestinaux…. Scientifiques!
Bien que les nombres ne doivent pas toujours être fabriqués ou trompeurs, il est clair que même les sociétés les plus fiables des gardiens numériques ne sont pas à l’abri de la négligence et des biais qui peuvent survenir avec les processus d’interprétation statistique. Il existe différentes façons dont les statistiques peuvent être trompeuses que nous détaillerons plus tard. Le plus courant est bien sûr la corrélation par rapport à la causalité, qui laisse toujours de côté un autre facteur (ou deux ou trois) qui est la causalité réelle du problème. Boire du thé augmente le diabète de 50% et la calvitie augmente le risque de maladie cardiovasculaire jusqu’à 70%! Avons-nous oublié de mentionner la quantité de sucre mise dans le thé, ou le fait que la calvitie et la vieillesse sont liées – tout comme les risques de maladies cardiovasculaires et la vieillesse?
Alors, les statistiques peuvent-elles être manipulées? Ils le peuvent. Les chiffres mentent-ils ? Vous pouvez être le juge.
Comment les statistiques peuvent être trompeuses

N’oubliez pas que l’utilisation abusive des statistiques peut être accidentelle ou intentionnelle. Alors qu’une intention malveillante de brouiller les lignes avec des statistiques trompeuses amplifiera sûrement le biais, l’intention n’est pas nécessaire pour créer des malentendus. L’utilisation abusive des statistiques est un problème beaucoup plus vaste qui s’étend maintenant à de multiples industries et domaines d’études. Voici quelques mésaventures potentielles qui conduisent généralement à une mauvaise utilisation:
- Sondage défectueux
La manière dont les questions sont formulées peut avoir un impact énorme sur la façon dont un public y répond. Les modèles de formulation spécifiques ont un effet persuasif et incitent les répondants à répondre de manière prévisible. Par exemple, lors d’un sondage pour obtenir des opinions fiscales, examinons les deux questions potentielles:
– Croyez-vous que vous devriez être taxé pour que les autres citoyens n’aient pas à travailler?- Pensez-vous que le gouvernement devrait aider les personnes qui ne peuvent pas trouver de travail?
Ces deux questions sont susceptibles de provoquer des réponses très différentes, même si elles traitent du même sujet de l’aide gouvernementale. Ce sont des exemples de « questions chargées. »
Une façon plus précise de formuler la question serait : « Soutenez-vous les programmes d’aide du gouvernement pour le chômage? » ou, (encore plus neutre) » Quel est votre point de vue sur l’aide au chômage?”
Les deux derniers exemples des questions originales éliminent toute inférence ou suggestion du sondeur et sont donc nettement plus impartiaux. Une autre méthode injuste de sondage consiste à poser une question, mais à la précéder d’une déclaration conditionnelle ou d’une déclaration de fait. En gardant notre exemple, cela ressemblerait à ceci: « Compte tenu des coûts croissants pour la classe moyenne, soutenez-vous les programmes d’aide du gouvernement?”
Une bonne règle de base est de toujours prendre les sondages avec un grain de sel, et d’essayer de revoir les questions qui ont été réellement présentées. Ils fournissent une grande perspicacité, souvent plus que les réponses.
- Corrélations imparfaites
Le problème avec les corrélations est le suivant: si vous mesurez suffisamment de variables, il apparaîtra éventuellement que certaines d’entre elles sont en corrélation. Comme une personne sur vingt sera inévitablement considérée comme significative sans corrélation directe, des études peuvent être manipulées (avec suffisamment de données) pour prouver une corrélation qui n’existe pas ou qui n’est pas suffisamment significative pour prouver la causalité.
Pour illustrer davantage ce point, supposons qu’une étude ait trouvé une corrélation entre une augmentation des accidents de voiture dans l’État de New York au mois de juin (A) et une augmentation des attaques d’ours dans l’État de New York au mois de juin (B).
Cela signifie qu’il y aura probablement six explications possibles:
– Les accidents de voiture (A) provoquent des attaques d’ours (B) – Les attaques d’ours (B) provoquent des accidents de voiture (A) – Les accidents de voiture (A) et les attaques d’ours (B) se provoquent en partie – Les accidents de voiture (A) et les attaques d’ours (B) sont causés par un troisième facteur (C) – Les attaques d’ours (B ) sont causés par un troisième facteur (C) qui est corrélé aux accidents de voiture (A) – La corrélation n’est que le hasard
Toute personne sensée identifierait facilement le fait que les accidents de voiture ne provoquent pas d’attaques d’ours. Chacun est probablement le résultat d’un troisième facteur, à savoir: une augmentation de la population, due à la haute saison touristique du mois de juin. Il serait absurde de dire qu’ils se causent mutuellement… et c’est exactement pourquoi c’est notre exemple. Il est facile de voir une corrélation.
Mais qu’en est-il de la causalité? Et si les variables mesurées étaient différentes ? Et si c’était quelque chose de plus crédible, comme la maladie d’Alzheimer et la vieillesse? Il y a clairement une corrélation entre les deux, mais y a-t-il un lien de causalité? Beaucoup supposeraient à tort, oui, uniquement en fonction de la force de la corrélation. Faites attention, en connaissance de cause ou par ignorance, la chasse aux corrélations continuera d’exister dans les études statistiques.
- Pêche aux données
Cet exemple de données trompeuses est également appelé « dragage de données » (et lié à des corrélations erronées). Il s’agit d’une technique d’exploration de données dans laquelle des volumes de données extrêmement importants sont analysés dans le but de découvrir des relations entre les points de données. Rechercher une relation entre les données n’est pas une mauvaise utilisation des données en soi, cependant, le faire sans hypothèse l’est.
Le dragage de données est une technique égoïste souvent utilisée dans le but contraire à l’éthique de contourner les techniques traditionnelles d’exploration de données, afin de rechercher des conclusions de données supplémentaires qui n’existent pas. Cela ne veut pas dire qu’il n’y a pas d’utilisation appropriée de l’exploration de données, car elle peut en fait conduire à des valeurs aberrantes surprises et à des analyses intéressantes. Cependant, le plus souvent, le dragage de données est utilisé pour supposer l’existence de relations de données sans autre étude.
Souvent, la pêche aux données donne lieu à des études très médiatisées en raison de leurs conclusions importantes ou farfelues. Ces études sont très vite contredites par d’autres découvertes importantes ou farfelues. Ces fausses corrélations laissent souvent le grand public très confus et à la recherche de réponses concernant l’importance de la causalité et de la corrélation.
De même, une autre pratique courante avec les données est l’omission, ce qui signifie qu’après avoir examiné un grand ensemble de données de réponses, vous ne choisissez que celles qui soutiennent vos points de vue et conclusions et omettez celles qui les contredisent. Comme mentionné au début de cet article, il a été démontré qu’un tiers des scientifiques ont admis qu’ils avaient des pratiques de recherche douteuses, notamment en retenant les détails analytiques et en modifiant les résultats…! Mais là encore, nous sommes face à une étude qui pourrait elle-même tomber dans ces 33% de pratiques douteuses, de sondages erronés, de biais sélectifs… Il devient difficile de croire à une analyse!
- Visualisation trompeuse des données
Des graphiques et des tableaux perspicaces incluent un regroupement d’éléments très basique, mais essentiel. Quels que soient les types de visualisation de données que vous choisissez d’utiliser, elle doit transmettre:
– Les échelles utilisées – La valeur de départ (zéro ou autre) – La méthode de calcul (par exemple, jeu de données et période de temps)
En l’absence de ces éléments, les représentations visuelles des données doivent être visualisées avec un grain de sel, en tenant compte des erreurs courantes de visualisation des données que l’on peut commettre. Les points de données intermédiaires devraient également être identifiés et le contexte donné si cela ajoutait de la valeur aux informations présentées. Compte tenu du recours croissant à l’automatisation intelligente des solutions pour les comparaisons de points de données variables, les meilleures pratiques (conception et mise à l’échelle) devraient être mises en œuvre avant de comparer les données provenant de différentes sources, ensembles de données, heures et emplacements.
- Biais délibéré et sélectif
Le dernier de nos exemples les plus courants d’utilisation abusive de statistiques et de données trompeuses est peut-être le plus grave. Le biais délibéré est la tentative délibérée d’influencer les résultats des données sans même feindre la responsabilité professionnelle. Le biais est le plus susceptible de prendre la forme d’omissions ou d’ajustements de données.
Le biais sélectif est légèrement plus discret pour qui ne lit pas les petites lignes. Il tombe généralement sur l’échantillon de personnes interrogées. Par exemple, la nature du groupe de personnes interrogées: interroger une classe d’étudiants sur l’âge légal de consommation d’alcool ou un groupe de retraités sur le système de soins aux personnes âgées. Vous vous retrouverez avec une erreur statistique appelée « biais sélectif ».
- En utilisant la variation en pourcentage en combinaison avec une petite taille d’échantillon
Une autre façon de créer des statistiques trompeuses, également liée au choix de l’échantillon discuté ci-dessus, est la taille dudit échantillon. Lorsqu’une expérience ou une enquête est menée sur une taille d’échantillon totalement non significative, non seulement les résultats seront inutilisables, mais la façon de les présenter – à savoir en pourcentages – sera totalement trompeuse.
Poser une question à un échantillon de 20 personnes, où 19 répondent « oui » (= 95% disent oui) par rapport à poser la même question à 1 000 personnes et 950 répondent « oui » (= 95% également): la validité du pourcentage n’est clairement pas la même. Fournir uniquement le pourcentage de changement sans le nombre total ou la taille de l’échantillon sera totalement trompeur. la bande dessinée de xkdc illustre très bien cela, pour montrer à quel point la revendication de la « croissance la plus rapide » est un discours marketing totalement relatif:

De même, la taille de l’échantillon nécessaire est influencée par le type de question que vous posez, la signification statistique dont vous avez besoin (étude clinique vs étude commerciale) et la technique statistique. Si vous effectuez une analyse quantitative, les tailles d’échantillon inférieures à 200 personnes ne sont généralement pas valides.
Exemples de statistiques trompeuses Dans la vie réelle
Maintenant que nous avons passé en revue plusieurs des méthodes les plus courantes d’utilisation abusive des données, examinons divers exemples de statistiques trompeuses à l’ère numérique sur trois spectres distincts, mais liés: médias et politique, publicité et science. Alors que certains sujets énumérés ici sont susceptibles de susciter des émotions selon le point de vue de chacun, leur inclusion est uniquement à des fins de démonstration de données.
- Exemples de statistiques trompeuses dans les médias et la politique
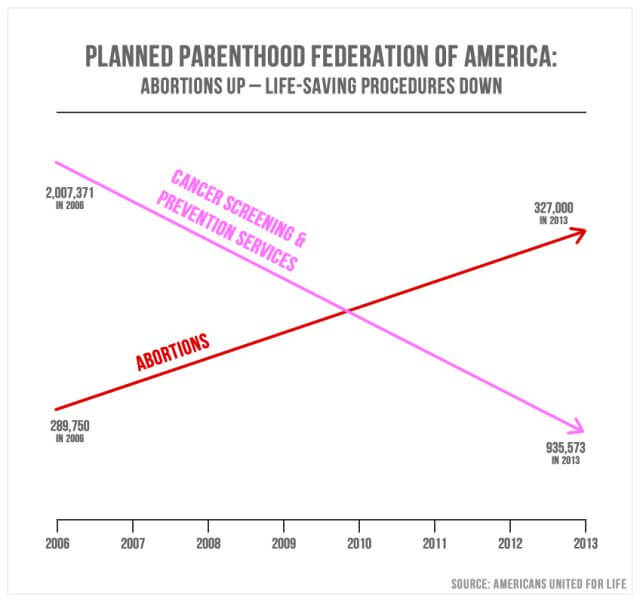
Les statistiques trompeuses dans les médias sont assez courantes. En septembre. 29, 2015, les républicains du Congrès américain ont interrogé Cecile Richards, la présidente de Planned Parenthood, concernant le détournement de 500 millions de dollars de financement fédéral annuel. Le graphique ci-dessus a été présenté comme un point d’accent.
Le représentant Jason Chaffetz de l’Utah a expliqué: « En rose, c’est la réduction des examens des seins, et le rouge est l’augmentation des avortements. C’est ce qui se passe dans votre organisation. »
Sur la base de la structure du graphique, il semble en fait montrer que le nombre d’avortements depuis 2006 a connu une croissance substantielle, tandis que le nombre de dépistages du cancer a considérablement diminué. L’objectif est de passer du dépistage du cancer à l’avortement. Les points du graphique semblent indiquer que 327 000 avortements ont une valeur intrinsèque supérieure à 935 573 dépistages du cancer. Pourtant, un examen plus approfondi révélera que le graphique n’a pas d’axe des ordonnées défini. Cela signifie qu’il n’y a pas de justification définissable pour l’emplacement des lignes de mesure visibles.
Politifact, un site Web de plaidoyer pour la vérification des faits, a examiné les chiffres du représentant Chaffetz via une comparaison avec les propres rapports annuels de Planned Parenthood. En utilisant une échelle clairement définie, voici à quoi ressemblent les informations:

Et comme ceci avec une autre échelle valide:
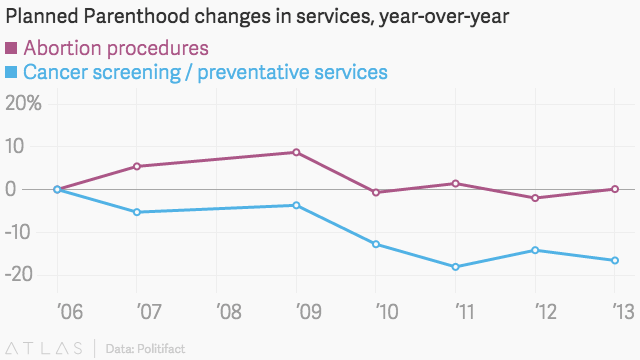
Une fois placée dans une échelle clairement définie, il devient évident que, bien que le nombre de dépistages du cancer ait en fait diminué, il dépasse encore de loin la quantité de procédures d’avortement effectuées chaque année. En tant que tel, il s’agit d’un excellent exemple de statistiques trompeuses, et certains pourraient soutenir un biais étant donné que le graphique ne provient pas du membre du Congrès, mais d’Americans United for Life, un groupe anti-avortement. Ce n’est là qu’un des nombreux exemples de statistiques trompeuses dans les médias et la politique.
- Statistiques trompeuses dans la publicité

En 2007, Colgate a été commandé par le Advertising Standards Authority (ASA) du Royaume-Uni pour abandonner leur demande: « Plus de 80% des dentistes recommandent Colgate. »Le slogan en question a été placé sur un panneau publicitaire au Royaume-Uni et a été jugé en violation des règles de publicité du Royaume-Uni.
L’allégation, qui était fondée sur des enquêtes menées auprès de dentistes et d’hygiénistes par le fabricant, s’est avérée fausse puisqu’elle permettait aux participants de sélectionner une ou plusieurs marques de dentifrice. L’ASA a déclaré que l’allégation » mean serait comprise par les lecteurs comme signifiant que 80% des dentistes recommandent Colgate au-delà des autres marques, et les 20% restants recommanderaient différentes marques. »
L’ASA a poursuivi: « Parce que nous avons compris que la marque d’un autre concurrent était recommandée presque autant que la marque Colgate par les dentistes interrogés, nous avons conclu que l’allégation impliquait de manière trompeuse que 80% des dentistes recommandent le dentifrice Colgate de préférence à toutes les autres marques. »L’ASA a également affirmé que les scripts utilisés pour l’enquête informaient les participants que la recherche était effectuée par une société de recherche indépendante, ce qui était intrinsèquement faux.
Sur la base des techniques d’utilisation abusive que nous avons couvertes, il est sûr de dire que cette technique détournée par Colgate est un exemple clair de statistiques trompeuses dans la publicité, et tomberait sous un sondage erroné et un biais pur et simple.
- Statistiques trompeuses en science
Tout comme l’avortement, le réchauffement climatique est un autre sujet politiquement chargé qui est susceptible de susciter des émotions. Il se trouve également que c’est un sujet qui est vigoureusement approuvé par les opposants et les partisans via des études. Jetons un coup d’œil à certaines des preuves pour et contre.
Il est généralement convenu que la température moyenne mondiale en 1998 était de 58,3 degrés Fahrenheit. C’est selon le Goddard Institute for Space Studies de la NASA. En 2012, la température moyenne mondiale a été mesurée à 58,2 degrés. Les opposants au réchauffement de la planète soutiennent donc que, comme il y a eu une diminution de 0,1 degré de la température moyenne mondiale sur une période de 14 ans, le réchauffement de la planète est réfuté.
Le graphique ci-dessous est celui le plus souvent référencé pour réfuter le réchauffement climatique. Il démontre la variation de la température de l’air (Celsius) de 1998 à 2012.
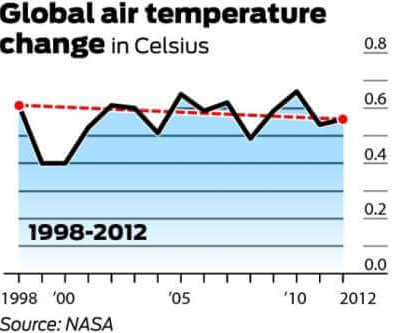
Il convient de mentionner que 1998 a été l’une des années les plus chaudes jamais enregistrées en raison d’un courant de vent El Niño anormalement fort. Il convient également de noter que, comme il existe une grande variabilité dans le système climatique, les températures sont généralement mesurées avec un cycle d’au moins 30 ans. Le graphique ci-dessous exprime le changement des températures moyennes mondiales sur 30 ans.
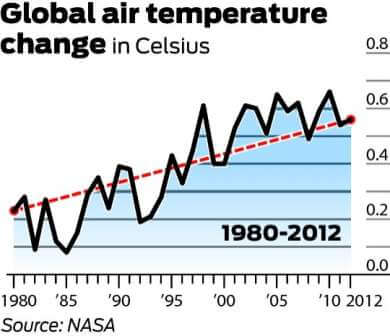
Et maintenant regardez la tendance de 1900 à 2012: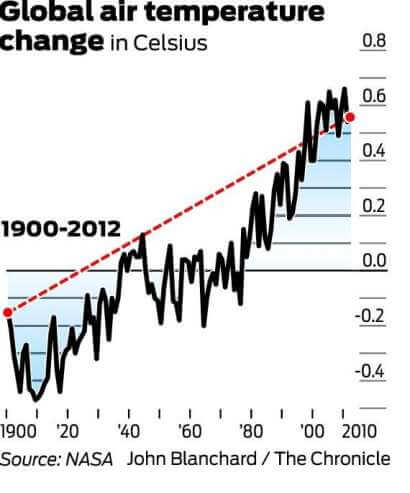
Bien que les données à long terme puissent sembler refléter un plateau, elles brossent clairement un tableau d’un réchauffement progressif. Par conséquent, l’utilisation du premier graphique, et seulement du premier graphique, pour réfuter le réchauffement climatique est un parfait exemple de statistiques trompeuses.
Comment Lire les statistiques Avec la distance
Une première bonne chose serait bien sûr de se tenir devant une enquête / expérience / recherche honnête – choisissez celle que vous avez sous les yeux -, qui a appliqué les bonnes techniques de collecte et d’interprétation des données. Mais vous ne pouvez pas savoir avant de vous poser quelques questions et d’analyser les résultats que vous avez entre vos mains.
Comme le conseille l’entrepreneur et ancien consultant Mark Suster dans un article, vous devriez vous demander qui a fait la recherche principale de ladite analyse. Groupe d’étude universitaire indépendant, équipe de recherche affiliée à un laboratoire, société de conseil? De là découle naturellement la question: qui les a payés? Comme personne ne travaille gratuitement, il est toujours intéressant de savoir qui parraine la recherche. De même, quels sont les motifs derrière la recherche? Qu’est-ce que le scientifique ou les statisticiens ont essayé de comprendre? Enfin, quelle était la taille de l’échantillon et qui en faisait partie? À quel point était-ce inclusif?
Ce sont des questions importantes à réfléchir et à répondre avant de diffuser partout des résultats biaisés ou biaisés – même si cela arrive tout le temps, à cause de l’amplification. Un exemple typique d’amplification se produit souvent avec les journaux et les journalistes, qui prennent une donnée et doivent la transformer en gros titres – donc souvent hors de son contexte d’origine. Personne n’achète un magazine où il est indiqué que l’année prochaine, la même chose se produira sur le marché XYZ que cette année – même si c’est vrai. Les éditeurs, les clients et les gens veulent quelque chose de nouveau, pas quelque chose qu’ils connaissent; c’est pourquoi nous nous retrouvons souvent avec un phénomène d’amplification qui se fait écho et plus qu’il ne le devrait.
Utilisation abusive des statistiques – Un résumé
À la question « les statistiques peuvent-elles être manipulées? », nous pouvons aborder 6 méthodes souvent utilisées – exprès ou non – qui faussent l’analyse et les résultats. Voici les types courants d’utilisation abusive des statistiques:
- Sondage défectueux
- Corrélations défectueuses
- Pêche aux données
- Visualisation trompeuse des données
- Biais intentionnel et sélectif
- Utilisant un changement en pourcentage en combinaison avec une petite taille d’échantillon
Maintenant que vous les connaissez, il sera plus facile de les repérer et de remettre en question toutes les statistiques qui vous sont données chaque jour. De même, afin de vous assurer de garder une certaine distance avec les études et les enquêtes que vous lisez, rappelez-vous les questions à vous poser – qui a fait des recherches et pourquoi, qui a payé pour cela, quel était l’échantillon.
Solutions commerciales axées sur la transparence et les données
S’il est clair que les données statistiques peuvent être utilisées à mauvais escient, elles peuvent également générer une valeur marchande éthique dans le monde numérique. Le Big data a la capacité de fournir aux entreprises de l’ère numérique une feuille de route pour l’efficacité et la transparence, et finalement, la rentabilité. Les solutions technologiques avancées telles que les logiciels de création de rapports en ligne peuvent améliorer les modèles de données statistiques et permettre aux entreprises de l’ère numérique de se démarquer de la concurrence.
Que ce soit pour l’intelligence de marché, l’expérience client ou le reporting commercial, l’avenir des données est maintenant. Veillez à appliquer les données de manière responsable, éthique et visuelle, et regardez votre identité d’entreprise transparente se développer.