Reconnaissance faciale – Étape par étape
Abordons ce problème une étape à la fois. Pour chaque étape, nous découvrirons un algorithme d’apprentissage automatique différent. Je ne vais pas expliquer complètement chaque algorithme pour éviter que cela ne devienne un livre, mais vous apprendrez les principales idées de chacun et vous apprendrez comment créer votre propre système de reconnaissance faciale en Python en utilisant OpenFace et dlib.
Étape 1: Trouver tous les visages
La première étape de notre pipeline est la détection des visages. Évidemment, nous devons localiser les visages sur une photo avant de pouvoir essayer de les distinguer!
Si vous avez utilisé un appareil photo au cours des 10 dernières années, vous avez probablement vu la détection de visage en action :

La détection de visage est une excellente fonctionnalité pour les caméras. Lorsque l’appareil photo peut sélectionner automatiquement les visages, il peut s’assurer que tous les visages sont au point avant de prendre la photo. Mais nous l’utiliserons dans un but différent: trouver les zones de l’image que nous voulons transmettre à l’étape suivante de notre pipeline.
La détection des visages s’est généralisée au début des années 2000 lorsque Paul Viola et Michael Jones ont inventé un moyen de détecter les visages suffisamment rapide pour fonctionner avec des caméras bon marché. Cependant, des solutions beaucoup plus fiables existent maintenant. Nous allons utiliser une méthode inventée en 2005 appelée Histogramme des gradients orientés — ou simplement HOG pour faire court.
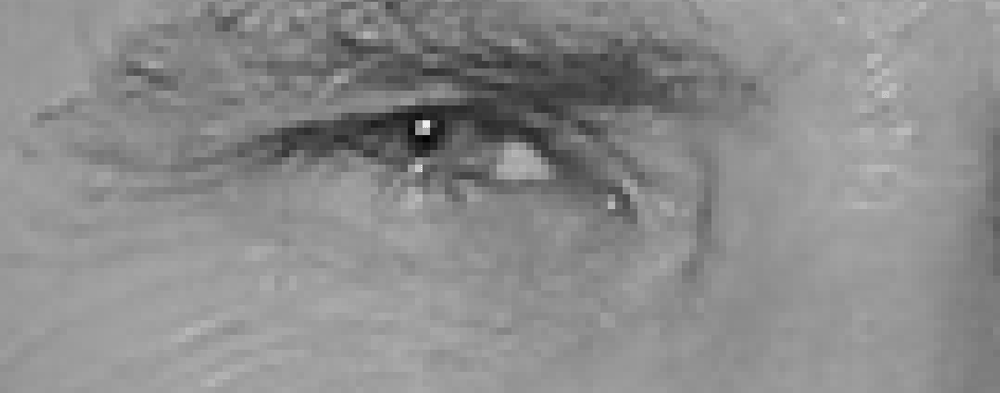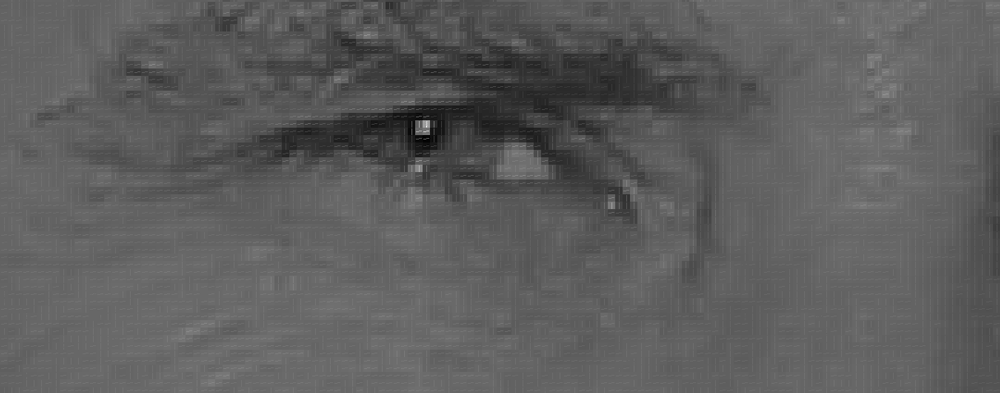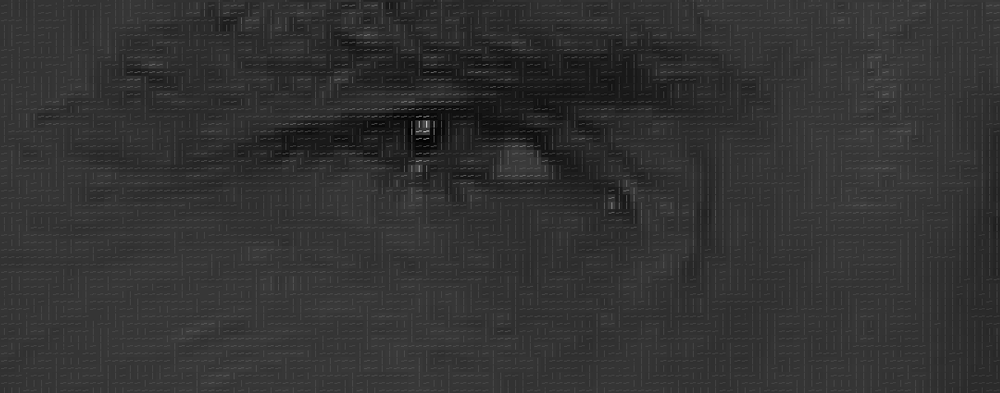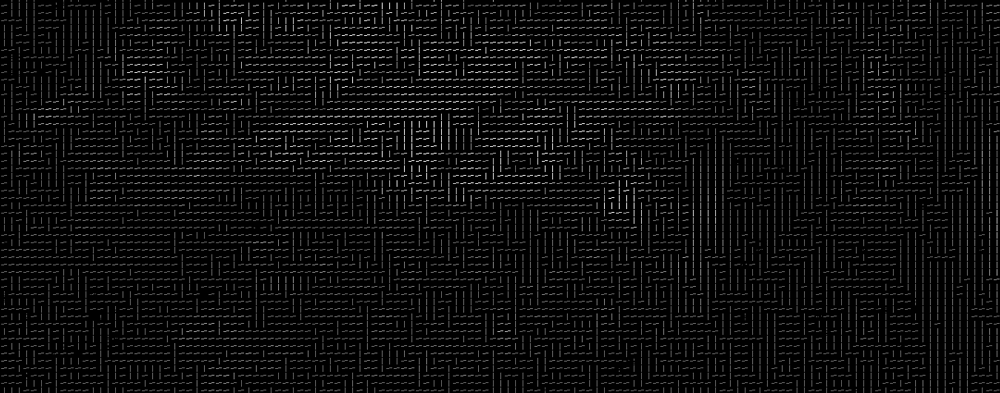
Pour trouver des visages dans une image, nous allons commencer par rendre notre image en noir et blanc car nous n’avons pas besoin de données de couleur pour trouver des visages :

Ensuite, nous examinerons chaque pixel de notre image un à la fois. Pour chaque pixel, nous voulons examiner les pixels qui l’entourent directement:

Notre objectif est de déterminer dans quelle mesure le pixel actuel est sombre par rapport aux pixels qui l’entourent directement. Ensuite, nous voulons dessiner une flèche indiquant dans quelle direction l’image devient plus sombre:

Si vous répétez ce processus pour chaque pixel de l’image, vous vous retrouvez avec chaque pixel remplacé par une flèche. Ces flèches sont appelées dégradés et montrent le flux de la lumière à l’obscurité sur toute l’image:
Cela peut sembler une chose aléatoire à faire, mais il y a une très bonne raison de remplacer les pixels par des dégradés. Si nous analysons directement les pixels, les images vraiment sombres et les images vraiment claires de la même personne auront des valeurs de pixels totalement différentes. Mais en ne considérant que la direction dans laquelle la luminosité change, les images vraiment sombres et les images vraiment lumineuses se retrouveront avec la même représentation exacte. Cela rend le problème beaucoup plus facile à résoudre!
Mais enregistrer le dégradé pour chaque pixel nous donne beaucoup trop de détails. Nous finissons par manquer la forêt pour les arbres. Ce serait mieux si nous pouvions simplement voir le flux de base de légèreté / obscurité à un niveau supérieur afin que nous puissions voir le motif de base de l’image.
Pour ce faire, nous allons diviser l’image en petits carrés de 16×16 pixels chacun. Dans chaque carré, nous compterons combien de gradients pointent dans chaque direction principale (combien de points en haut, de points en haut à droite, de points à droite, etc.). Ensuite, nous remplacerons ce carré dans l’image par les directions de flèche qui étaient les plus fortes.
Le résultat final est que nous transformons l’image d’origine en une représentation très simple qui capture la structure de base d’un visage de manière simple:

Pour trouver des visages dans cette image de PORC, il suffit de trouver la partie de notre image qui ressemble le plus à un motif de PORC connu qui a été extrait d’un tas d’autres visages d’entraînement:

En utilisant cette technique, nous pouvons maintenant facilement trouver des visages dans n’importe quelle image:

Si vous voulez essayer cette étape vous-même en utilisant Python et dlib, voici du code montrant comment générer et afficher des représentations de porc d’images.
Etape 2 : Poser et projeter des visages
Ouf, nous avons isolé les visages dans notre image. Mais maintenant, nous devons faire face au problème que les visages tournés dans des directions différentes semblent totalement différents d’un ordinateur:

Pour tenir compte de cela, nous allons essayer de déformer chaque image afin que les yeux et les lèvres soient toujours à la place de l’échantillon dans l’image. Cela nous facilitera beaucoup la comparaison des visages dans les prochaines étapes.
Pour ce faire, nous allons utiliser un algorithme appelé estimation de repère de visage. Il y a beaucoup de façons de le faire, mais nous allons utiliser l’approche inventée en 2014 par Vahid Kazemi et Josephine Sullivan.
L’idée de base est que nous allons trouver 68 points spécifiques (appelés repères) qui existent sur chaque visage — le haut du menton, le bord extérieur de chaque œil, le bord intérieur de chaque sourcil, etc. Ensuite, nous allons former un algorithme d’apprentissage automatique pour pouvoir trouver ces 68 points spécifiques sur n’importe quel visage:

Voici le résultat de la localisation des 68 repères de visage sur notre image de test:

Maintenant que nous savons que les yeux et la bouche sont, nous allons simplement faire pivoter, mettre à l’échelle et cisailler l’image afin que les yeux et la bouche soient centrés le mieux possible. Nous ne ferons pas de chaînes 3D fantaisistes car cela introduirait des distorsions dans l’image. Nous n’utiliserons que des transformations d’image de base comme la rotation et l’échelle qui préservent les lignes parallèles (appelées transformations affines):

Maintenant, peu importe la façon dont le visage est tourné, nous sommes en mesure de centrer les yeux et la bouche sont à peu près dans la même position dans l’image. Cela rendra notre prochaine étape beaucoup plus précise.
Si vous voulez essayer cette étape vous-même en utilisant Python et dlib, voici le code pour trouver des repères de visage et voici le code pour transformer l’image en utilisant ces repères.
Étape 3: Encodage des faces
Maintenant, nous sommes à la base du problème — en fait, en séparant les faces. C’est là que les choses deviennent vraiment intéressantes!
L’approche la plus simple de la reconnaissance faciale consiste à comparer directement le visage inconnu que nous avons trouvé à l’étape 2 avec toutes les photos que nous avons de personnes qui ont déjà été taguées. Lorsque nous trouvons un visage précédemment marqué qui ressemble beaucoup à notre visage inconnu, il doit s’agir de la même personne. Ça semble être une très bonne idée, non?
Il y a en fait un énorme problème avec cette approche. Un site comme Facebook avec des milliards d’utilisateurs et un billion de photos ne peut pas parcourir tous les visages étiquetés précédemment pour les comparer à chaque image nouvellement téléchargée. Cela prendrait beaucoup trop de temps. Ils doivent être capables de reconnaître les visages en millisecondes, pas en heures.
Ce dont nous avons besoin, c’est d’un moyen d’extraire quelques mesures de base de chaque visage. Ensuite, nous pourrions mesurer notre visage inconnu de la même manière et trouver le visage connu avec les mesures les plus proches. Par exemple, nous pouvons mesurer la taille de chaque oreille, l’espacement entre les yeux, la longueur du nez, etc. Si vous avez déjà regardé une émission de mauvais crime comme CSI, vous savez de quoi je parle :
div>
Le moyen le plus fiable de mesurer un visage
Ok, alors quelles mesures devons-nous collecter de chaque visage pour construire notre base de données de visages connus? La taille de l’oreille? Longueur du nez? Couleur des yeux ? Autre chose ?
Il s’avère que les mesures qui nous semblent évidentes pour nous, les humains (comme la couleur des yeux) n’ont pas vraiment de sens pour un ordinateur regardant des pixels individuels dans une image. Les chercheurs ont découvert que l’approche la plus précise consiste à laisser l’ordinateur déterminer les mesures à collecter lui-même. L’apprentissage en profondeur fait un meilleur travail que les humains pour déterminer quelles parties d’un visage sont importantes à mesurer.
La solution consiste à former un réseau neuronal convolutif Profond (comme nous l’avons fait dans la Partie 3). Mais au lieu d’entraîner le réseau à reconnaître les objets photos comme nous l’avons fait la dernière fois, nous allons l’entraîner à générer 128 mesures pour chaque visage.
Le processus d’entraînement fonctionne en regardant 3 images de visage à la fois:
- Chargez une image de visage d’entraînement d’une personne connue
- Chargez une autre image de la même personne connue
- Chargez une image d’une personne totalement différente
Puis l’algorithme examine les mesures qu’il génère actuellement pour chacune de ces trois images. Il modifie ensuite légèrement le réseau neuronal de sorte qu’il s’assure que les mesures qu’il génère pour #1 et #2 sont légèrement plus proches tout en s’assurant que les mesures pour #2 et #3 sont légèrement plus éloignées :

Après avoir répété cette étape des millions de fois pour des millions d’images de milliers de personnes différentes, le réseau de neurones apprend à générer de manière fiable 128 mesures pour chaque personne. Dix photos différentes de la même personne devraient donner à peu près les mêmes mesures.
Les gens d’apprentissage automatique appellent les 128 mesures de chaque face un embedding. L’idée de réduire des données brutes compliquées comme une image en une liste de nombres générés par ordinateur revient beaucoup dans l’apprentissage automatique (en particulier dans la traduction linguistique). L’approche exacte des visages que nous utilisons a été inventée en 2015 par des chercheurs de Google, mais de nombreuses approches similaires existent.
Encodage de notre image faciale
Ce processus d’entraînement d’un réseau neuronal convolutif pour produire des intégrations faciales nécessite beaucoup de données et de puissance informatique. Même avec une carte vidéo NVidia Telsa coûteuse, il faut environ 24 heures de formation continue pour obtenir une bonne précision.
Mais une fois le réseau formé, il peut générer des mesures pour n’importe quel visage, même ceux qu’il n’a jamais vus auparavant! Cette étape ne doit donc être effectuée qu’une seule fois. Heureusement pour nous, les gens bien d’OpenFace l’ont déjà fait et ils ont publié plusieurs réseaux formés que nous pouvons utiliser directement. Merci Brandon Amos et son équipe!
Donc, tout ce que nous avons à faire nous-mêmes est d’exécuter nos images de visage via leur réseau pré-formé pour obtenir les 128 mesures pour chaque visage. Voici les mesures pour notre image de test:

Alors, quelles parties du visage ces 128 nombres mesurent-ils exactement? Il s’avère que nous n’en avons aucune idée. Cela n’a pas vraiment d’importance pour nous. Tout ce qui nous importe, c’est que le réseau génère presque les mêmes chiffres en regardant deux images différentes de la même personne.
Si vous voulez essayer cette étape vous-même, OpenFace fournit un script lua qui générera des intégrations de toutes les images dans un dossier et les écrira dans un fichier csv. Vous le dirigez comme ça.
Étape 4: Trouver le nom de la personne à partir de l’encodage
Cette dernière étape est en fait l’étape la plus facile de tout le processus. Tout ce que nous avons à faire est de trouver la personne dans notre base de données de personnes connues qui a les mesures les plus proches de notre image de test.
Vous pouvez le faire en utilisant n’importe quel algorithme de classification d’apprentissage automatique de base. Aucune astuce d’apprentissage en profondeur n’est nécessaire. Nous utiliserons un classificateur SVM linéaire simple, mais de nombreux algorithmes de classification pourraient fonctionner.
Tout ce que nous devons faire est de former un classificateur qui peut prendre les mesures d’une nouvelle image de test et indique quelle personne connue est la correspondance la plus proche. L’exécution de ce classificateur prend des millisecondes. Le résultat du classificateur est le nom de la personne!
Alors essayons notre système. Tout d’abord, j’ai formé un classificateur avec l’incorporation d’environ 20 images chacune de Will Ferrell, Chad Smith et Jimmy Falon: